






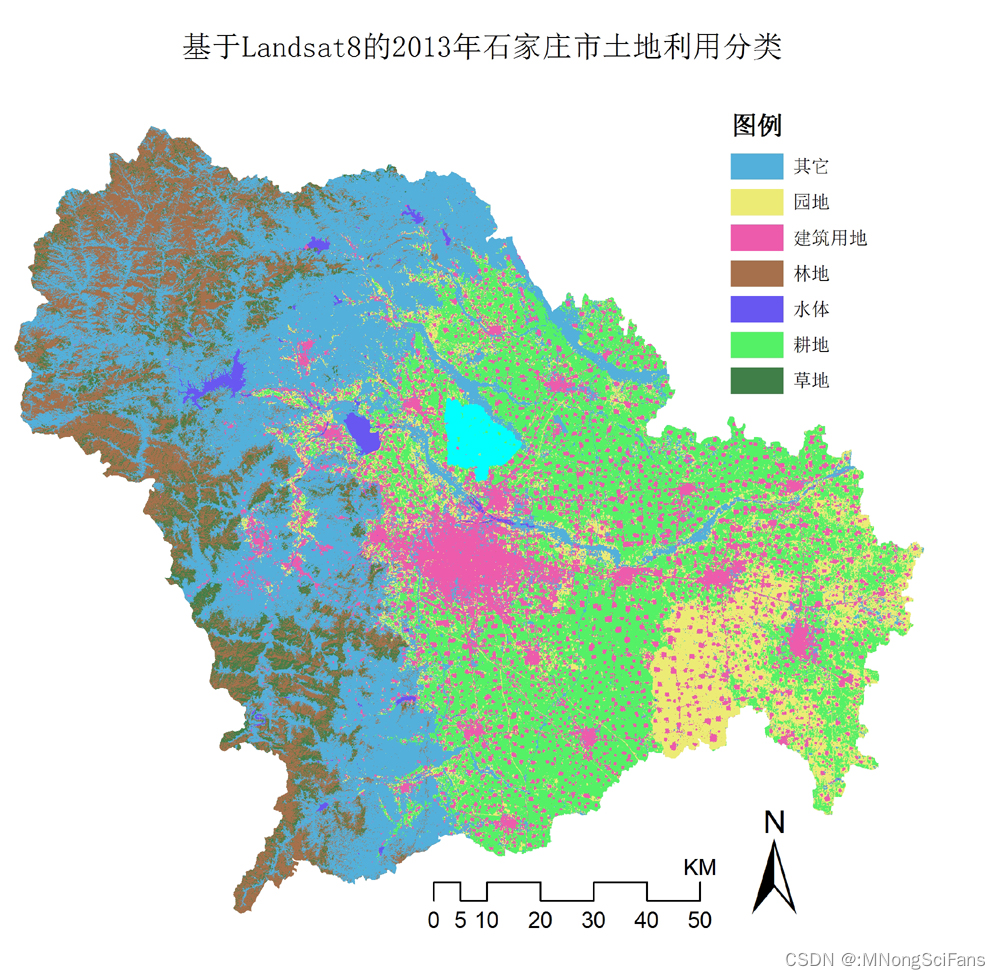
土地利用/覆被变化解译
多光谱和全色波段遥感影像结合滨海湿地分类系统、《中国湿地调查纲要》和研究区现状及相关研究,将江苏海岸带滨海湿地解译类型确定为浅海水域、芦苇、互花米草、盐地碱蓬、混生湿地植被、河流、水库坑塘、养殖水域、道路、建筑、裸地、农业用地、林地、其他陆生植被、光滩15类。
- 土地利用类型分为6大类,分别为河流、湿地、农田、建设用地、裸地、林地。
- 基于高分辨率遥感影像,土地利用类型分为6大类:分别为农田、林地、草地、建筑用地、裸地、湿地,其中湿地细分为6小类,分别是:河流水域、河流洪泛湿地、农用湿地、水库/库区湿地、人工河渠、城市景观河娱乐型湿地,总共11类。湿地分类可参考已有的湿地分类系统,如湿地公约和中国湿地调查的分类成果,以及牛振国等人制定的基于遥感的全国湿地分类系统(牛振国等,2009)。具体说明如下:
- 河流水域:永久性或季节性河流、溪流和三角洲;人工开挖的主干型河道;
- 河流洪泛湿地:季节性泛滥的农用地;季节性或间歇性洪泛地;
- 农用湿地:农用的水塘、蓄水池;水产池塘;稻田;小型水沟/渠;
- 水库/库区湿地:水库、拦河坝和堤坝形成的蓄水区;
- 人工河渠:人工开挖的顺直型水渠,不包括人工开挖的主干型河道;
- 城市景观河娱乐型湿地。

- 分类边界准确、清晰;
- 基于高分辨率影像,分类精度为2米(使用全色波段融合后分辨率为2米的影像进行分类)。
土地利用类型分为七大类,分别是耕地、园地、林地、草地、建筑用地、水体和其它。分类标准和编码采用“GB/T 21010-2007 《土地利用现状分类》国家标准”,其中编码05,06,07,08,09,10均划分为建筑用地(编码为05)。
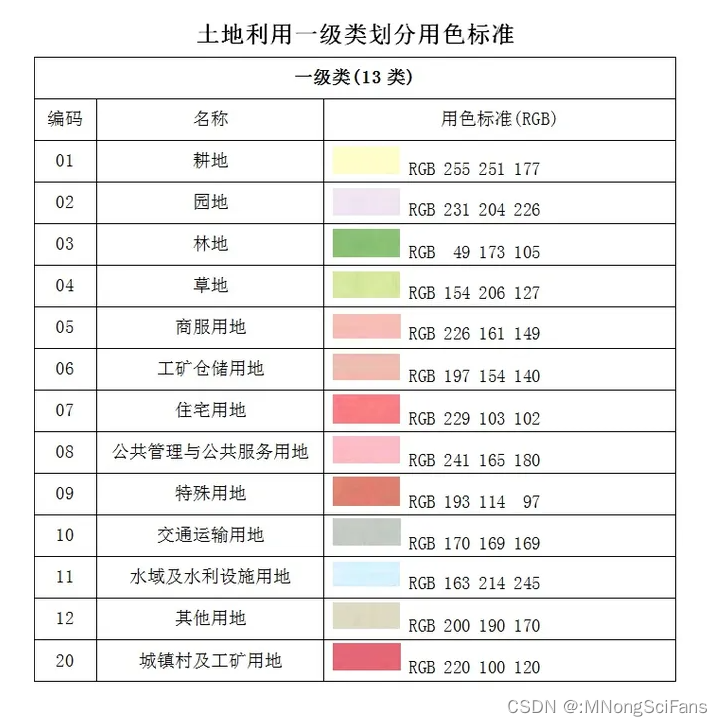
举例:数据如果共有5类,数值分别为1、2、5、7、11,分别代表水体、林地、耕地、建筑用地、草地。土地利用类型数据栅格(*.tif)包含六种土地利用类型:
- 【黄 色】开放性用地(主要是农业)
- 【紫 色】居住用地
- 【蓝 色】水域(开放的水体和大型河流)
- 【绿 色】森林
- 【天蓝色】湿地
- 【黑 色】城镇用地
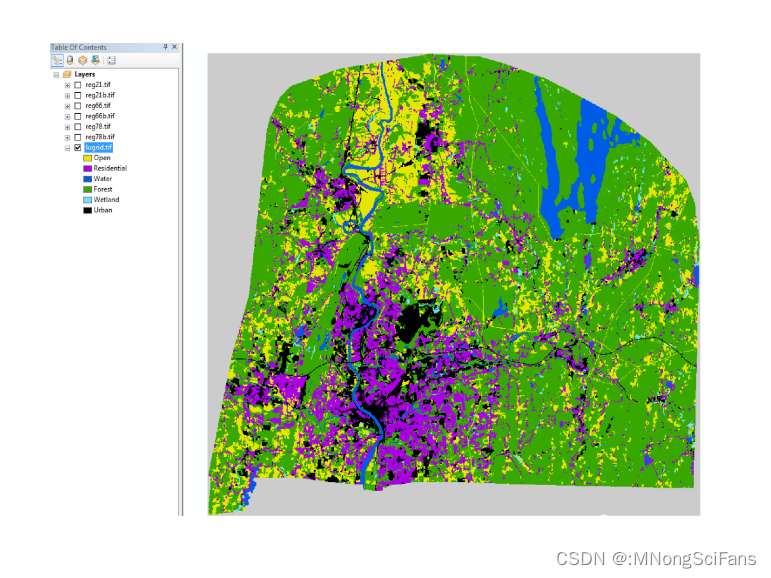
图层的属性,列数和行数是(1104列×1035行)、像元大小(50米)、格式(TIFF)、像素类型(有符号整型)。如果景观有边框,则必须使用带符号整数像素类型:即景观边界外的分类单元带,并指定负分类值。如果横向视图不包含边框,则可以使用无符号整数类型。
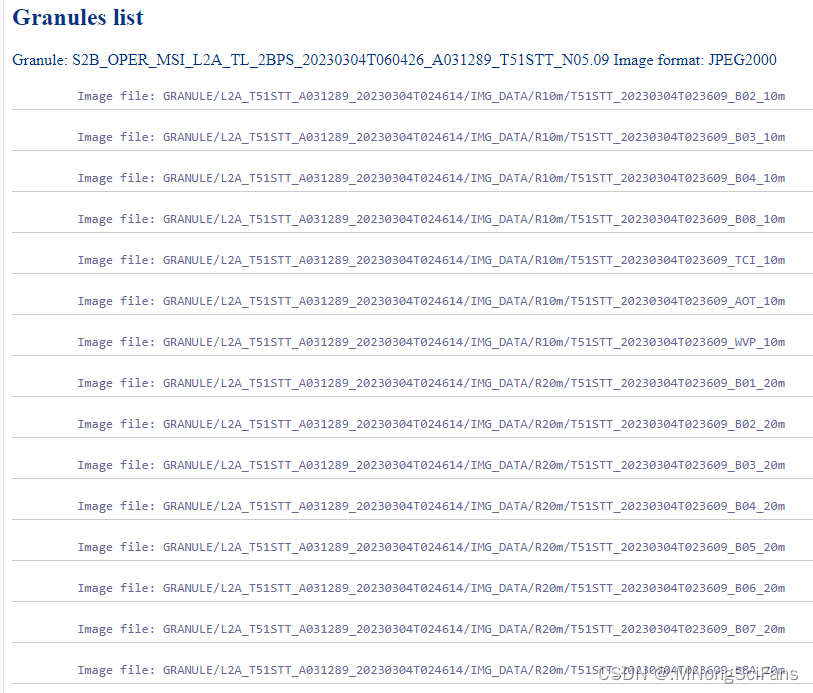
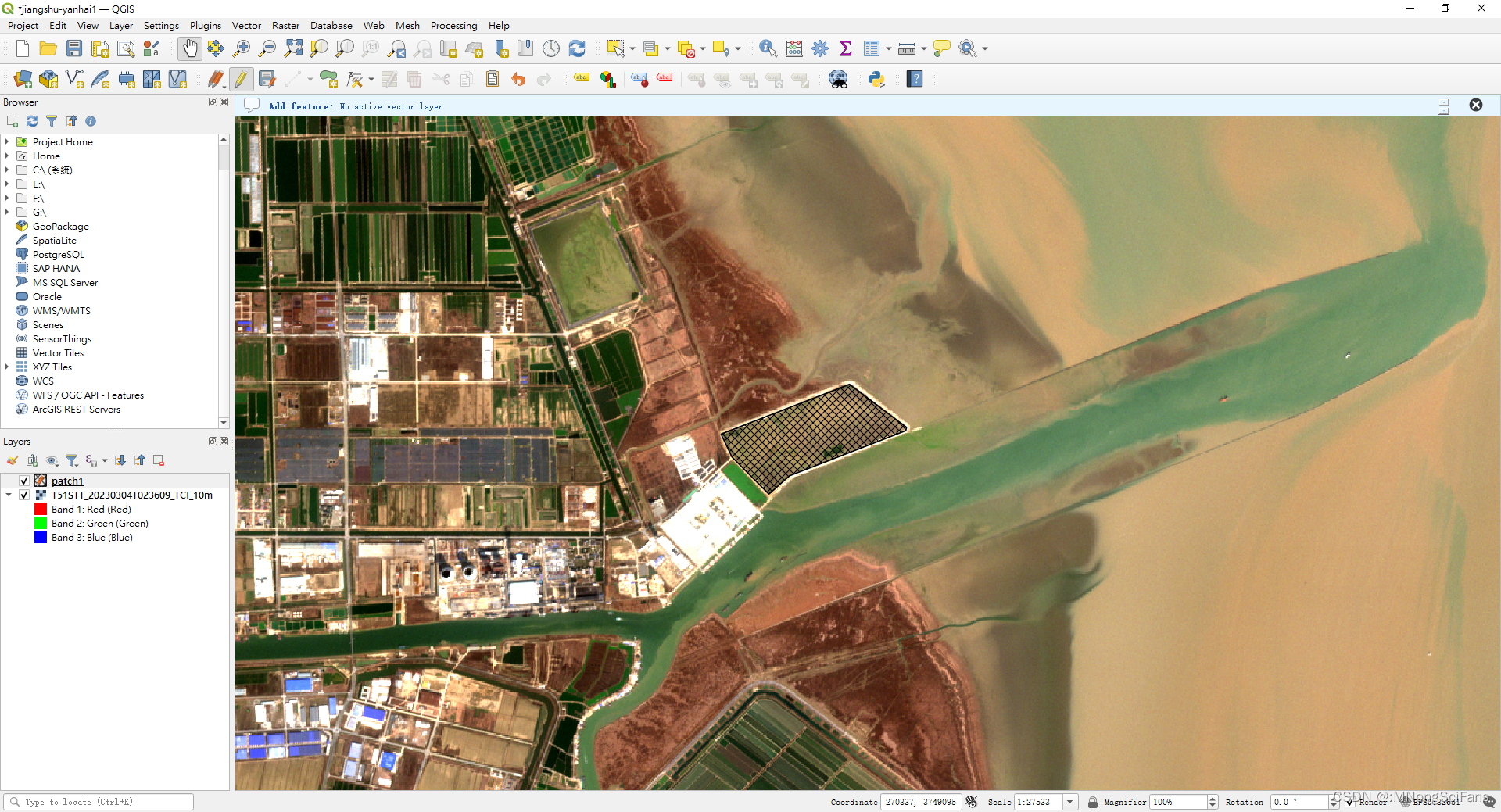
下载Sentinel-2哨兵-2卫星的影像数据,波段空间分辨率有10m、20m和60m,光谱分辨率较高,影像质量好,不用几何校正,进行大气校正即可。
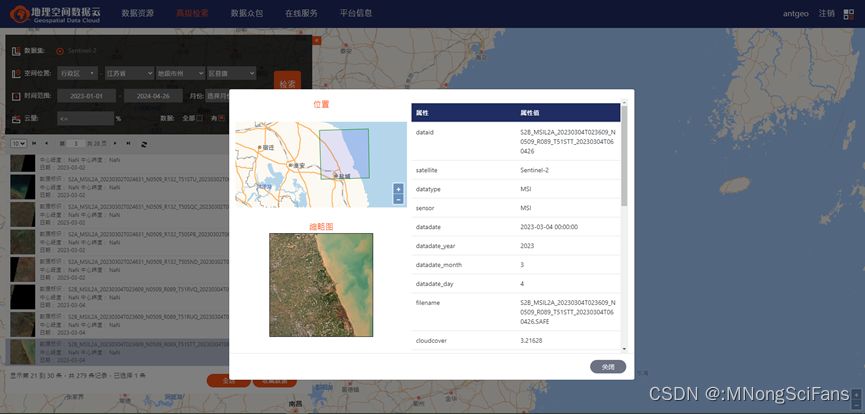
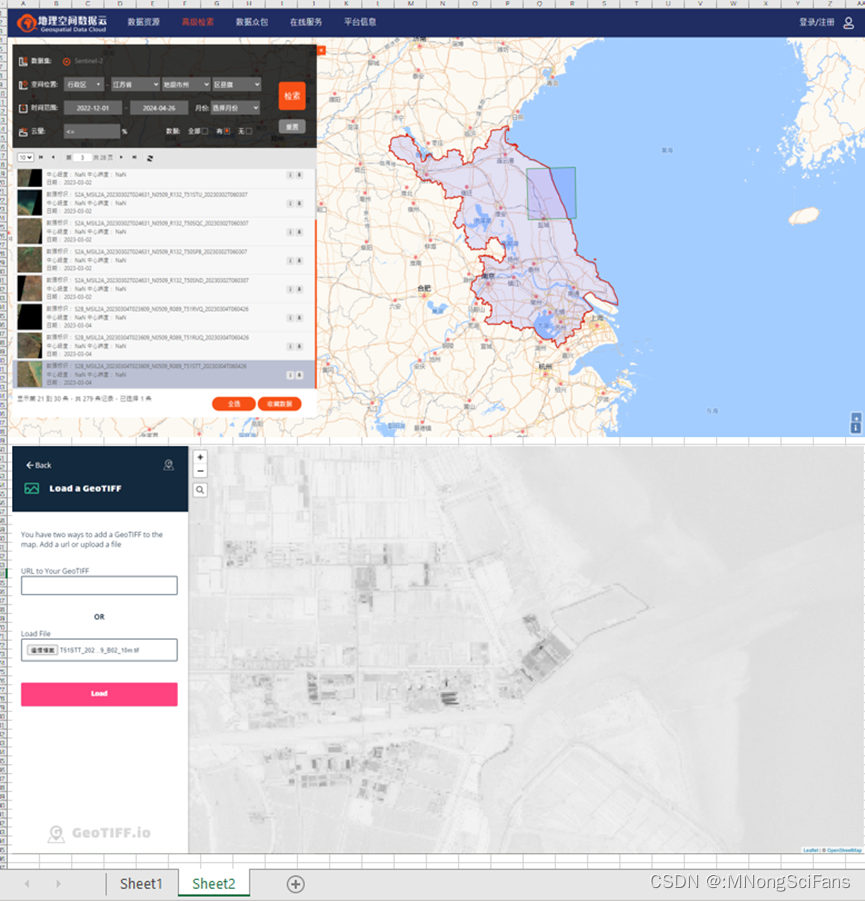
影像列表为jp2格式,可以转为tif格式
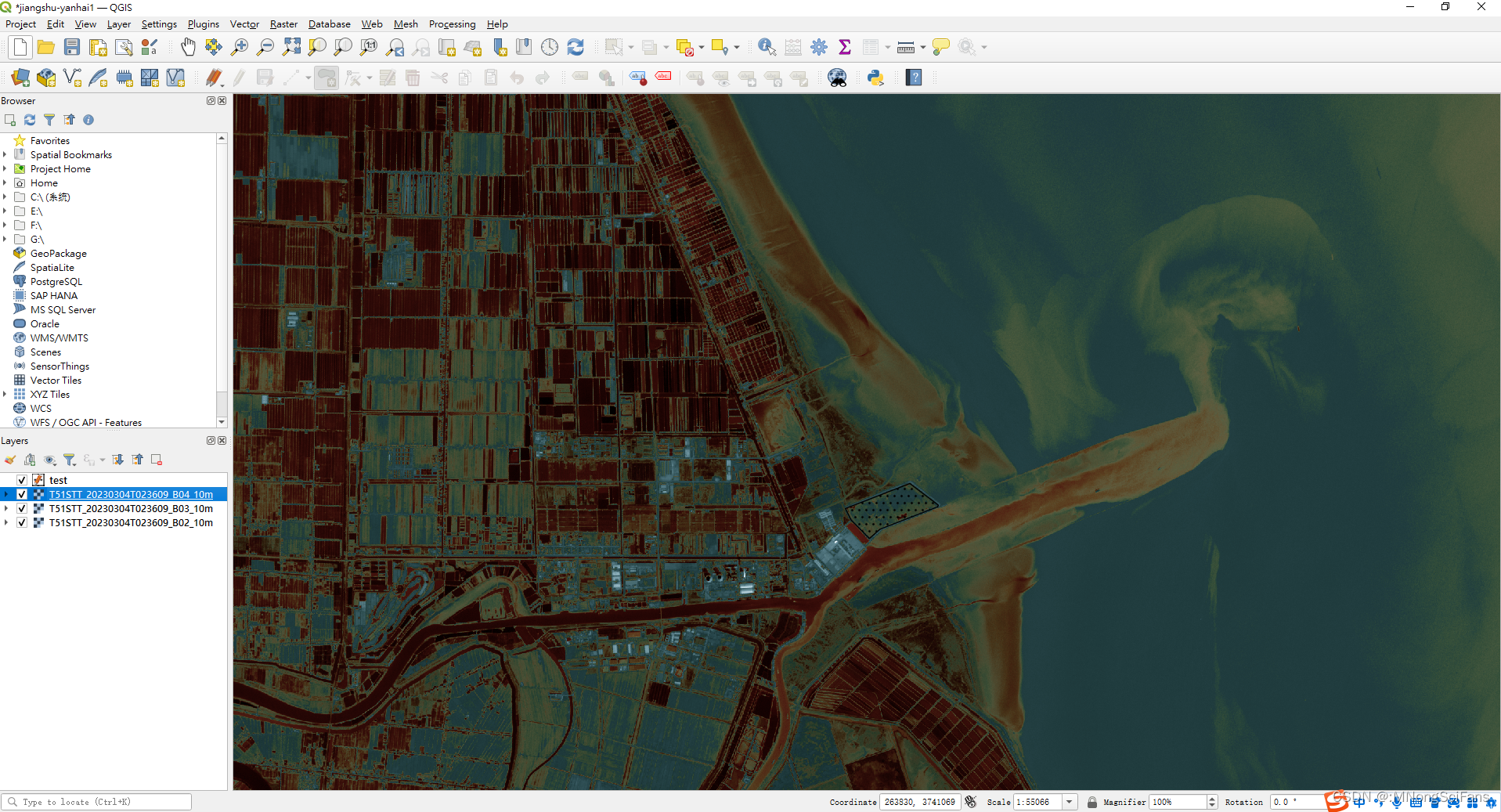
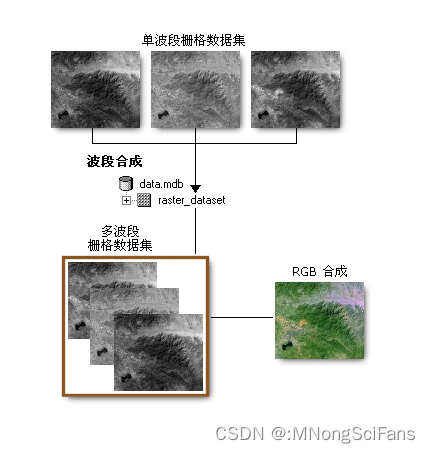
可以使用移动窗口法,网格分析法,临近法分类,支持向量机(SVM)分类,或者决策树(CART)分类。
景观格局指数计算:Fragstats4
选择GeoTIFF grid 栅格格式
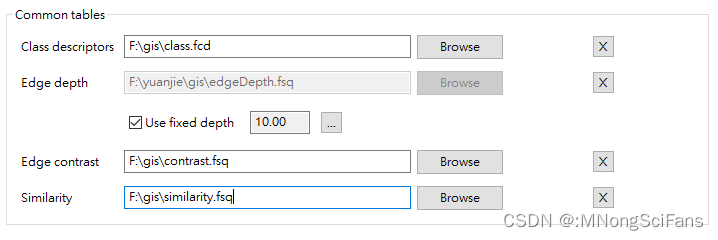
加载四个参数文件
文件1:类别描述文件 "class.fcd’,更改影像值及对应类别名称即可,以下为文件内容:
ID,Name,Enabled,IsBackground
1,water,true,false
2,tree,true,false
5,crop,true,false
7,build,true,false
11,grass,true,false
文件2:边缘深度文件 "edgeDepth.fsq’,更改影像值及对应类别名称,更改各个类别之间边缘深度值(0~100),矩阵为5*5对称矩阵,以下为文件内容:
FSQ_TABLE
CLASS_LIST_LITERAL(water,tree,crop,build,grass)
CLASS_LIST_NUMERIC(1,2,5,7,11)
0,30,40,10,60
30,0,50,10,60
40,50,0,20,60
10,10,20,0,10
60,60,60,10,0
文件3:边缘差异度文件 "contrast.fsq’,更改影像值及对应类别名称,更改各个类别之间差异度值(0~1),矩阵为5*5对称矩阵,以下为文件内容:
FSQ_TABLE
CLASS_LIST_LITERAL(water,tree,crop,build,grass)
CLASS_LIST_NUMERIC(1,2,5,7,11)
0,0.6,0.5,0.4,0.6
0.6,0,0.2,0.6,0.3
0.5,0.2,0,0.6,0.5
0.4,0.6,0.6,0,0.6
0.6,0.3,0.5,0.6,0
文件4:相似度文件 "similarity.fsq’,更改影像值及对应类别名称,更改各个类别之间相似度(0~1),矩阵为5*5对称矩阵,以下为文件内容:
FSQ_TABLE
CLASS_LIST_LITERAL(water,tree,crop,build,grass)
CLASS_LIST_NUMERIC(1,2,5,7,11)
1,0.2,0.3,0.2,0.3
0.2,1,0.5,0.3,0.6
0.3,0.5,1,0.3,0.6
0.2,0.3,0.3,1,0.4
0.3,0.6,0.6,0.4,1
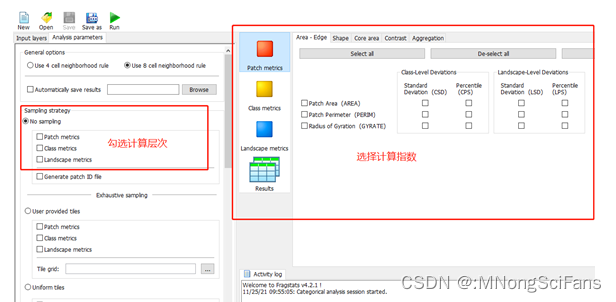
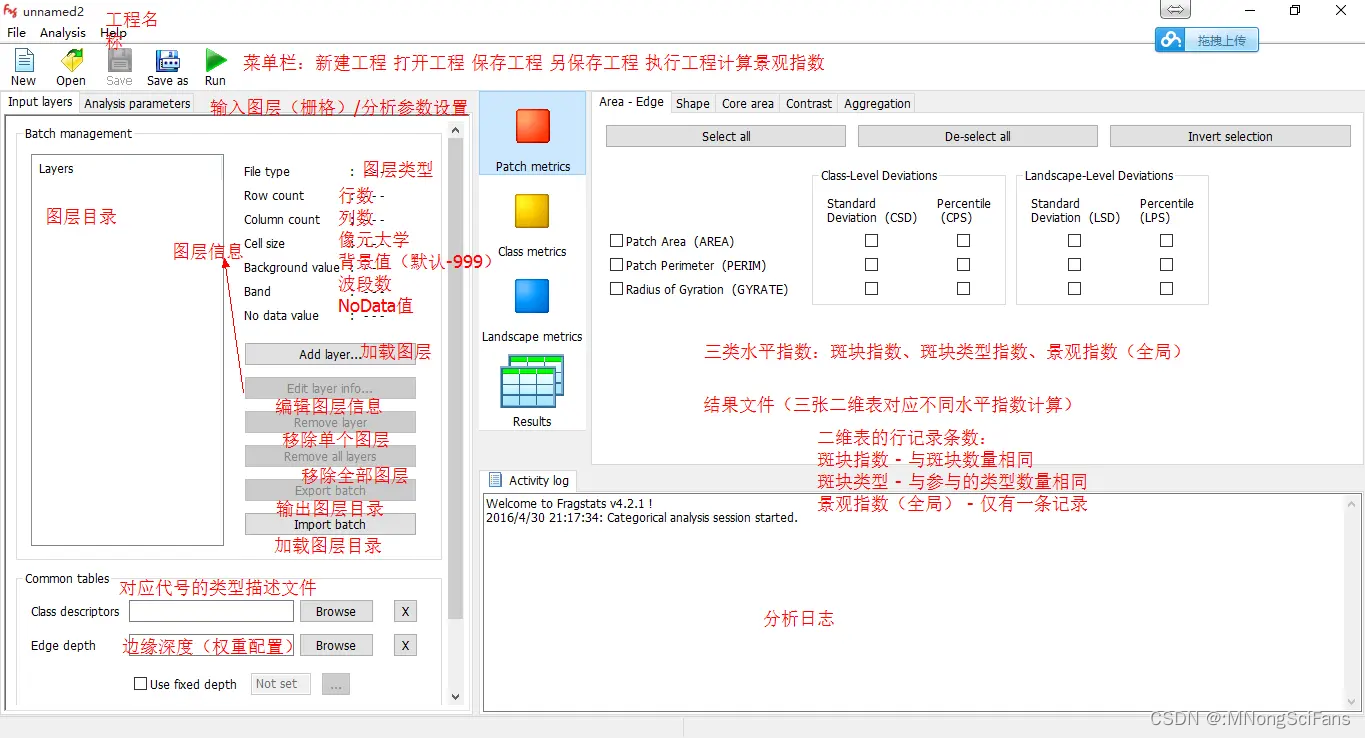
设置分析参数和要计算的景观指数,分析参数中设置斑块(patch)、类型(class)和景观(landscape),根据需要计算分景观指数所属尺度选择分析参数中的对应尺度。
教程1 设置软件和查看栅格。
教程2 分析单个栅格。
教程3 批处理多个网格。
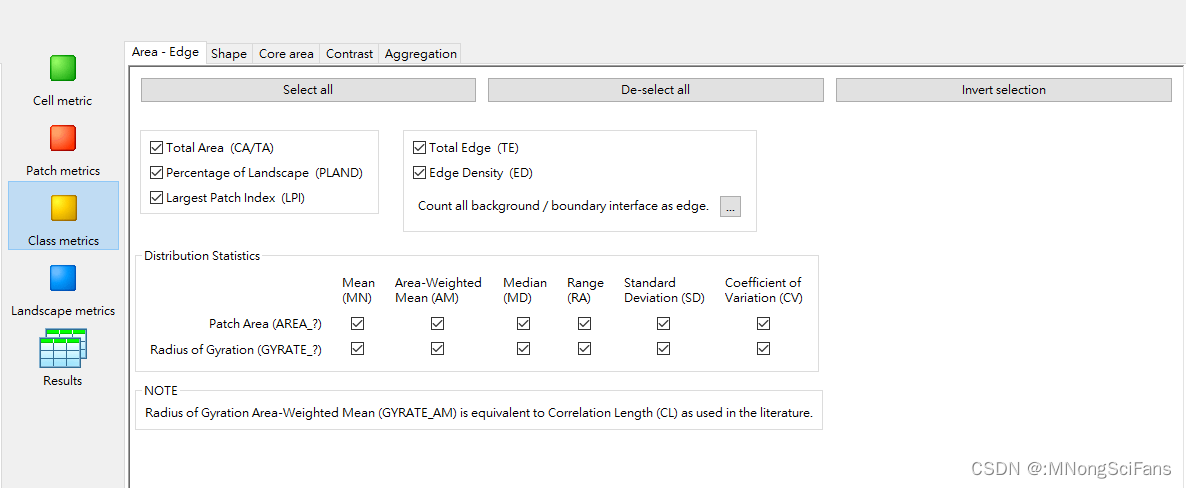
教程4 移动窗口分析。
教程5 使用抽样策略来分析子景观,包括:
(1)使用由用户提供的,移动窗口或系统平铺方案的详尽抽样;
(2)基于用户提供的或随机抽样点周围的用户指定窗口的部分抽样。
点击工具栏下方的Analysis parameters,并在下方选择Use 8 cell neighborhood rule,8近邻相比4近邻更为平滑,但计算也相对较慢。
勾选Patch metrics、Class metrics、Landscape metrics以及Generate patch ID file。
视情况需要选择是否输入分类描述信息(表)。
土地利用分类信息表可以对不同取值的所有地表类型进行特定的描述,比如是否对每种地表都进行计算,是否把某种地类视为背景等等。
分类信息表并不是必要的,不输入时软件会默认所有地表类型全部参与运算,除了已经设定好的背景值(这里是999)。
新建文本文件,重命名为descriptors.fcd,使用记事本打开descriptors.fcd文件。
注意Fragstats可以识别.fcd类型的分类描述文件,但并不要求分类描述文件全部采用这种后缀名。打开后可以看到,描述信息里包含了四个字段。ID即为不同地表类型的取值,它们取决于输入的栅格。Name是每种地表分类的描述,在Fragstats的输出文件中将以TYPE字段显示。Enabled 和IsBackground两者都是逻辑描述,前者表示是否计算并输出本类型,后者表示是否将本类型作为背景值。
点击用户界面上Common tables -> Class descriptors -> Browse按钮,即可使用土地利用分类信息表descriptors.fcd。
Edge depth需要景观边缘深度效应距离文件,便于软件读取识别地类的说明。
下面的两个文件一个是比邻景观类型差异度权重文件,另外一个是比邻的景观类型相似度文件,软件的帮助文档中(Help -> USER GUIDELINES -> Running via the Graphical User lnterface -> Step 4.)有更为详细的介绍,大家可以自行查看。
选择完成后点击run按钮,弹出running……界面。
其实,你还是需要点一下proceed这个按钮的……这样fragstats就开始计算了,不要在这个页面空空坐等。
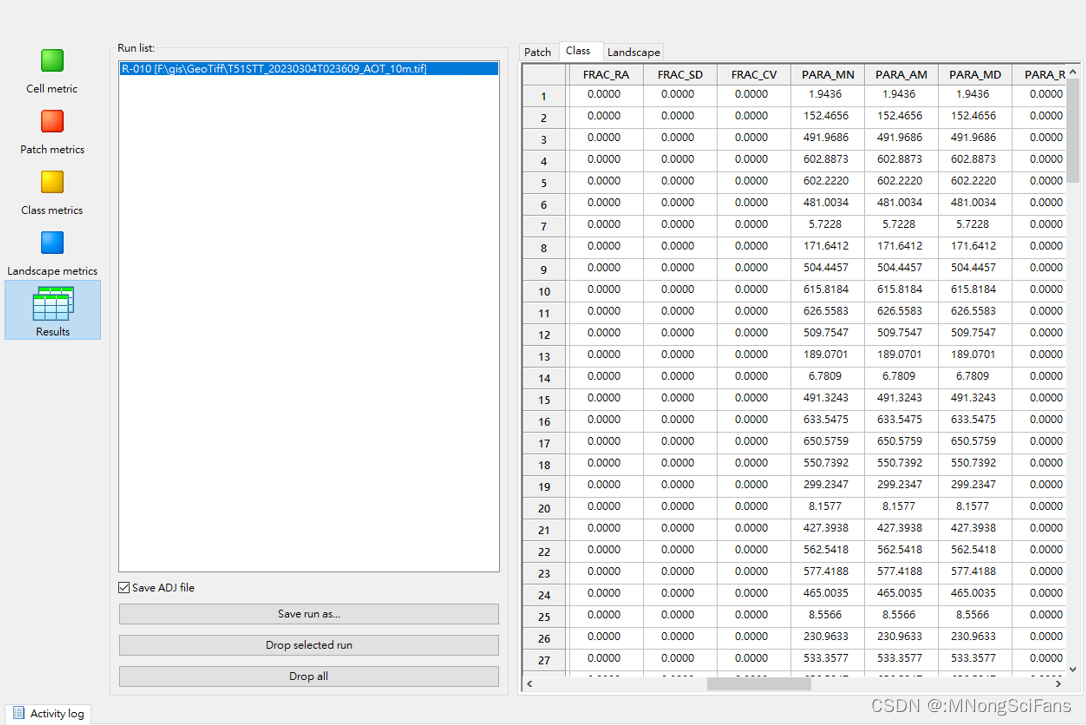
完成后,单击用户界面右上角窗格中的Results按钮,然后单击每个选项卡结果集。结果被分别显示在不同度量级别的表中。
因此,如果你分别计算了斑块(patch)、类型(class)和景观(landscape)三个级别的指标,那么在每个对应的选项卡中都会有结果。否则,只有我们选择的那个级别的选项卡才会有数据。
结果数据中,Patch选项卡的行表示输入栅格中每个斑块(patch),列表示我们所选择的所有斑块(patch)级别的指标。Class选项卡的行表示输入栅格的每一个类型(class),列表示我们所选择的所有类型(class)级别的指标。Landscape选项卡的行表示整个输入的栅格构成的景观,列表示我们所选择的所有景观(landscape)级别的指标。
之后,要导出结果,在运行列表中单击Save run as…就可以了。
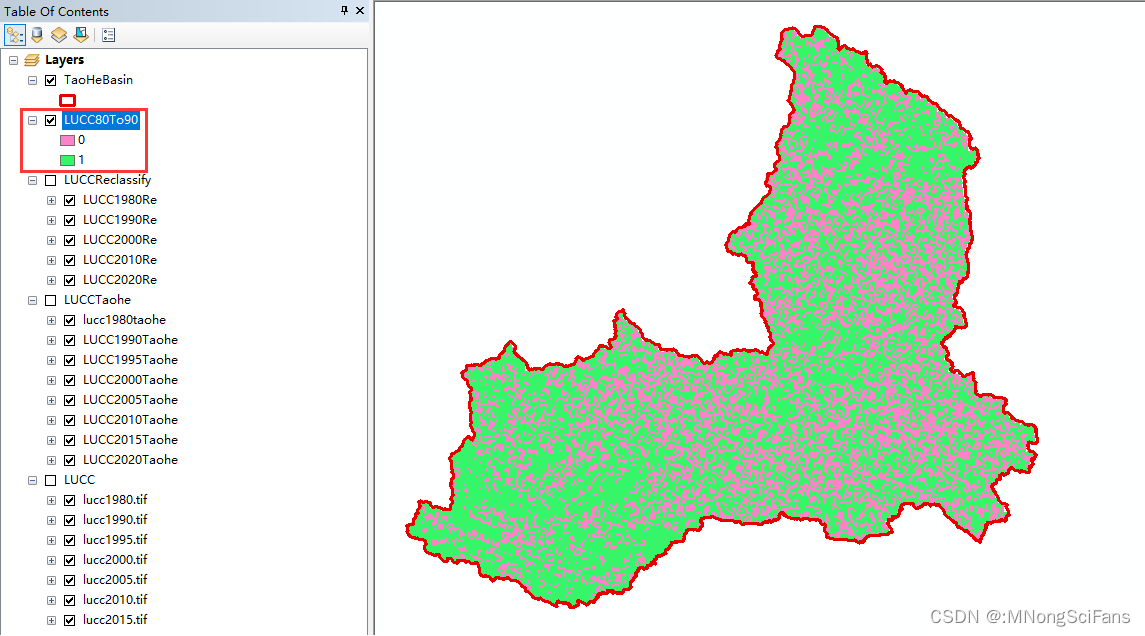
解译后景观格局分析
(1)数据格式
Shape矢量格式和TIFF格式,shape格式数据中包含每个景观类型的面积属性字段。
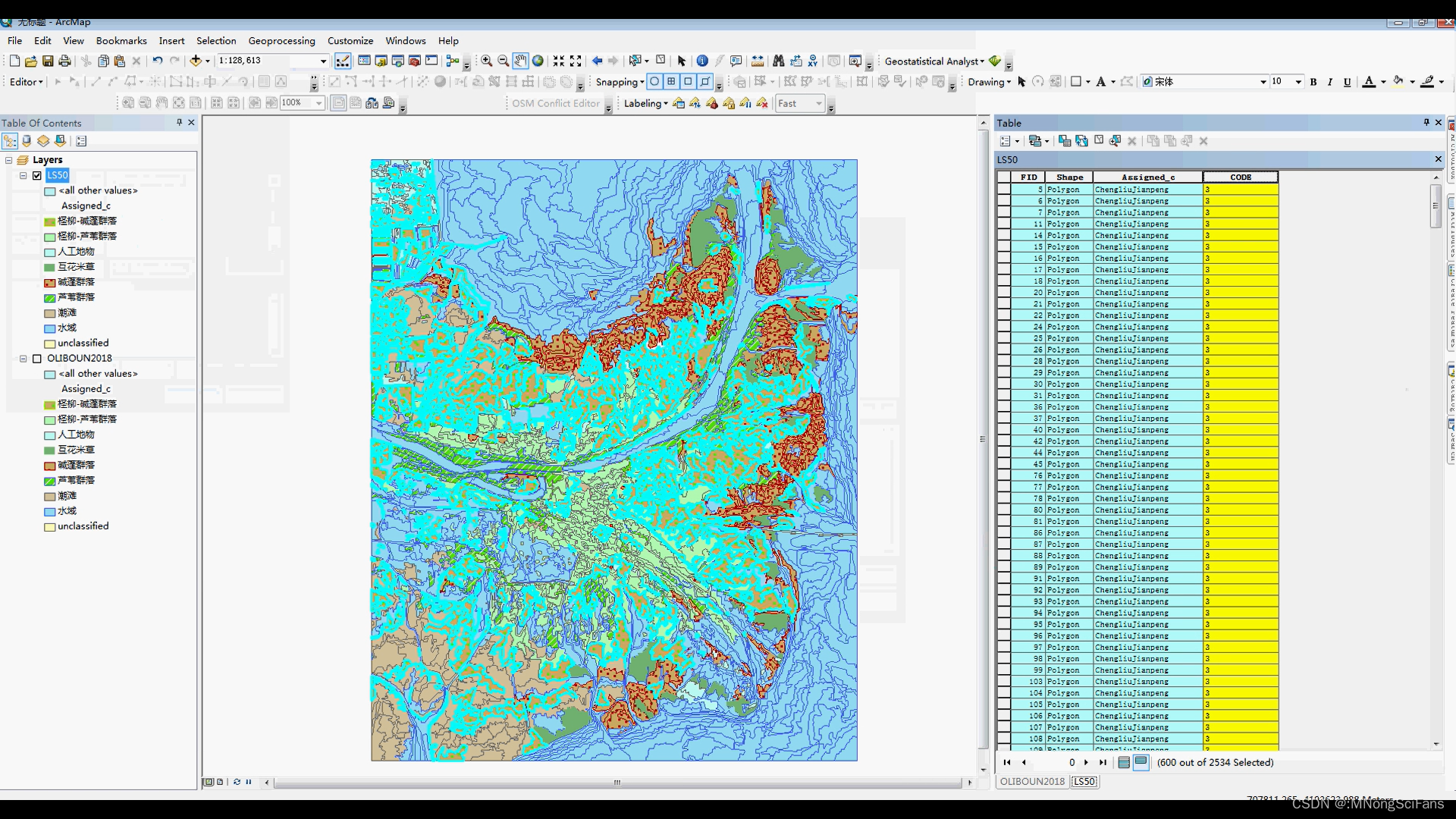
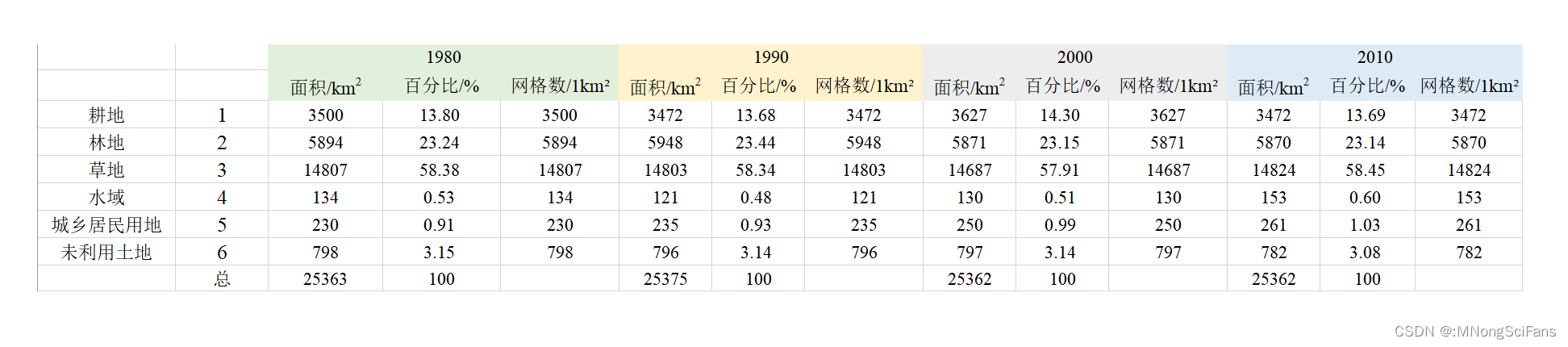
(2)斑块参数分析
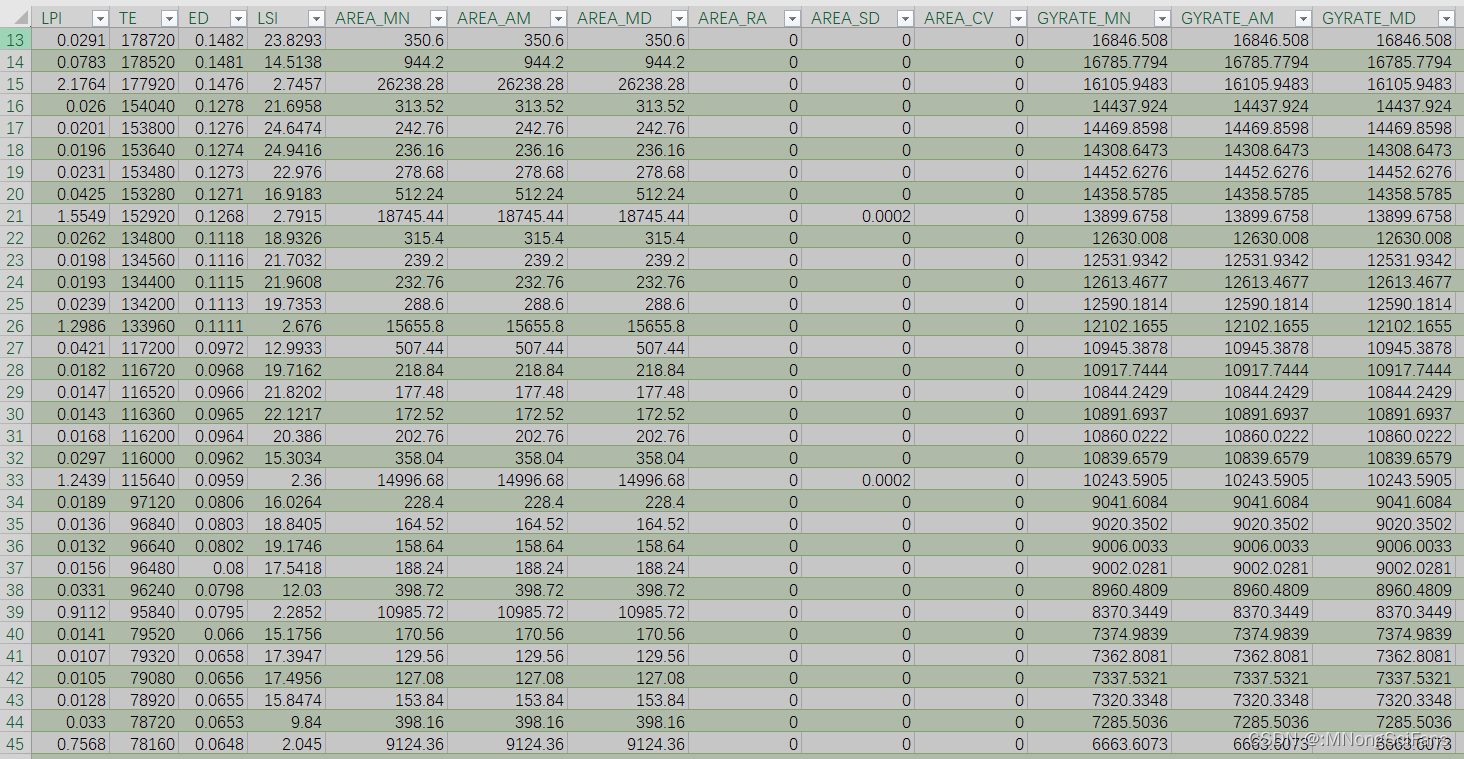
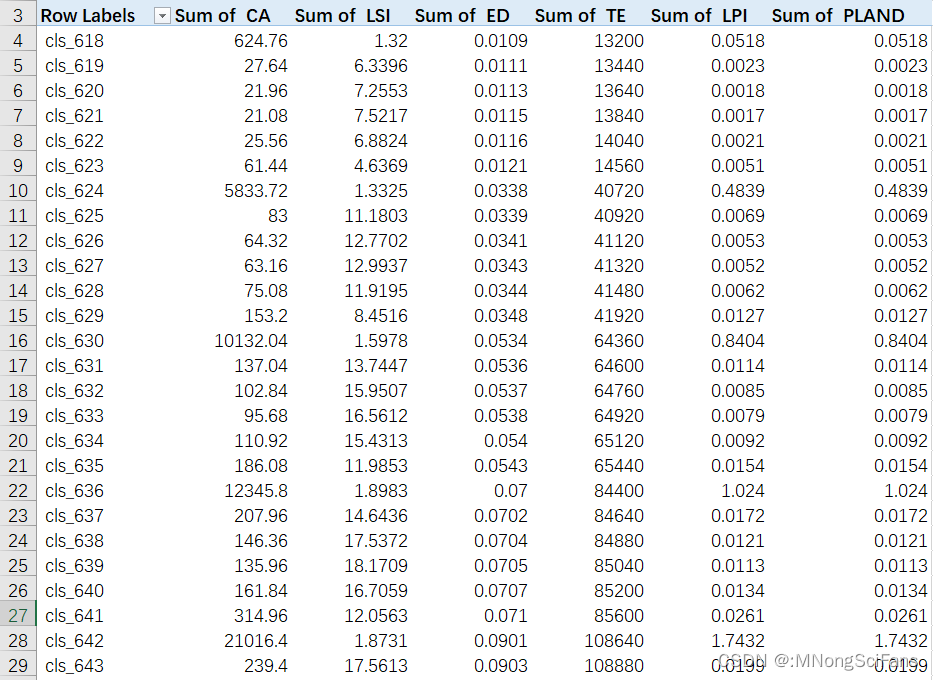
基于土地利用解译结果进行斑块参数分析,每期单独一张表,excel格式。样表如下。
| 地类名称 | 斑块数 | 百分比 | 最小面积 | 最大面积 | 平均面积 | 总面积 |
根据解译结果,利用Fragstat软件计算斑块特征指数、斑块密度指数、平均斑块形状指数、边缘密度指数、景观离散度指数、平均形状破碎化指数、聚集度指数、均一度指数、香浓多样性指数、蔓延度指数等。
景观格局指标包括斑块密度(PD)、平均分形维数(FRAC)、最大斑块面积指数(LPI)、景观分割指数(DIVISION)、香浓多样性指数(SHDI)和聚集度指数(AI)。
斑块密度(PD)
指标位置:Class metrics -> Aggregation
生态学意义:表征景观格局破碎程度的指标之—。斑块密度值越高,斑块的数量越多,反映景观破碎化程度以及景观空间异质性程度越大。
平均分形维数(FRAC)
指标位置:Patch metrics -> Shape
生态学意义:平均分形维数=1表示景观形状简单,其值越大表示景观斑块形状越复杂。
最大斑块面积指数(LPI)
指标位置:Class metrics -> Area-Edge
生态学意义:最大斑块指数有助于确定景观的优势类型,可以反映人类活动的方向和强弱。
景观分割指数(DIVISION)
指标位置:Class metrics -> Aggregation
生态学意义:景观分割指数反映景观中斑块的分离程度,值越大表明景观内斑块组成越破碎、景观越复杂。
香浓多样性指数(SHDI)
指标位置:Landscape metrics -> Diversity
生态学意义:香浓多样性指数能反映景观异质性,对景观中各斑块类型非均衡分布状况较敏感,且在一个景观系统中,土地利用越丰富,破碎化程度越高,SHDI值越高。
聚集度指数(AI)
指标位置:Landscape metrics -> Aggregation
生态学意义:聚集度指数表明景观斑块间聚合的程度,其值越大表示同类斑块的聚集度越高。
单个输入栅格计算一套完整的、同时具备结构性和功能性的指标。包括斑块、类型和景观三个不同的级别。这里斑块(patch)、类型(class)、景观(landscape)分别是FRAGSTATS的三个不同的分析级别,每一个级别下有不一样的指标,后面查看输出结果的时候,也会按照不同的级别分别给出。这三个级别之间的差异如下:
斑块(patch):反映单个 块 的特征;
类型(class):反映属于相同类型的斑块的结果特征;
景观(landscape):反映不同类型的斑块共同组合下的整体结构特征
Results结果集。结果被分别显示在不同度量级别的表中。因此,如果您像本例所示计算斑块(patch)、类型(class)和景观(landscape)三个级别的指标,那么在每个对应的选项卡中都会有结果。
Patch选项卡的行表示输入栅格中每个斑块(patch),列表示您所选择的所有斑块(patch)级别的指标。
Class选项卡的行表示输入栅格的每一个类型(class),列表示您所选择的所有类型(class)级别的指标。
Landscape选项卡的行表示整个输入的栅格构成的景观,列表示您所选择的所有景观(landscape)级别的指标。
基于单元格的指标、表面指标、抽样策略、功能指标、度量标准等多种功能模块,可以对环境变量进行完善的流程分析和控制,解决环境变量中出现的各类问题景观生态学中计算景观格局常用的软件。
景观格局是指大小和形状各异的景观要素(斑块、廊道、基质)在景观空间上的排列,体现了景观异质性,也体现了各种生态过程在不同空间和不同尺度上的相互作用。
其中景观格局指数反映了景观格局的变化、特征与对比,对于区域景观生态规划、国土空间规划等方面意义重大。
Fragstats中景观格局指数较多,但有些指数表示的含义相近,一共分为3个级别:斑块级别(patch)、类型级别(class)、景观级别(landscape),其中类型级别(class)和景观级别(landscape)用的较。具体选择三个级别中的哪些指标,一般结合研究中想要表述什么问题和探讨什么问题。
[1]斑块级别patch(一个斑块对应一个指数)
1)斑块面积—AREA—ha—(0,+∞)—值越大斑块面积就越大;
2)斑块周长—PERIM—m—(0,+∞)—面积相对的情况下,值越大镶嵌体中生境更优越;
3)斑块相似系数—LSIM—%—;
4)边缘对比度—EDCON—%—;
5)形状指标—SHAPE—无单位—;
6)分维数—FRACT—无单位—[1,2];
7)核心斑块面积—CORE—ha—;
8)核心斑块数量—NCORE—个/100ha—;
9)最近邻距离—NEAR—m—;
10)邻近指标—CONTIG—无单位—;
[2]类型级别class(一种景观类型对应一个指数)
1)平均分维指数—FRAC MN—无单位—[1-2]—1表示正方形,值越大,表示斑块形状越复杂;
2)景观形状指数—LSI—无单位—[1+∞)—描述整个景观内斑块形状的特点,值越大,斑块越分离;
3)斑块数量—NP—个—[1+∞)—类型或是景观镶嵌体中的斑块数量,值越大,这一类型的斑块数量越多;
4)总面积—CA—ha—(0,+∞)—某一类型景观的面积之和;
5)面积百分比—PLAND—%—(0%,100%]—某一类景观的面积百分比;
6)平均斑块面积—AREA MN—(0,+∞)—值越小破碎化程度越大,值越大,景观聚集化程度低;
7)最大斑块指数—LPI—%—(0%,100%]—景观中最大斑块的面积占景观总面积的比例,值越大,斑块优势越明显;
8)斑块密度—PD—个/100ha—(0,+∞)—单位面积上的斑块数量,值越大,斑块分割越细;
9)边界密度—ED—m/ha—(0,+∞)—单位面积边界长度;
10)聚集度—AI—%—(0,100]—景观斑块聚合程度,值越大,聚合越好;
11)景观破碎度指数—Ci—%—[0,1)—0表示无破碎化,1表示完全破碎化;
12)斑块面积方差—PSSD—ha—;
13)斑块面积均方差—PSCV—%;
14)总边缘长度—TE—m—;
15)边缘密度—ED—m/ha—;
—IJI—%——值越小,表明该斑块类型仅与少数几种其他类型相邻接;
[3]景观级别landscape(一个景观图生成一个指数)
1)蔓延度指数—CONTAG—%—(0,100]—景观里不同斑块类型的团聚程度或延展趋势,值越大,斑块连接性越好;
2)景观破碎度指数—Ci—%—[0,1)—0表示无破碎化,1表示完全破碎化;
3)香农均匀度指数—SHEI—无单位—[0,1)—值越小,说明景观受少数优势类型所支配的趋势越强,值越大,表明各种景观类型分布越均匀;
4)香农多样性指数—SHDI—无单位—[0,+∞)—值越大,表示景观中各斑块类型及分布更加丰富;
5)聚集度—AI—%—(0,100]—景观斑块聚合程度,值越大,聚合越好;
6)边界密度—ED—m/ha—(0,+∞)—单位面积边界长度;
7)斑块密度—PD—个/100ha—(0,+∞)—单位面积上的斑块数量,值越大,斑块分割越细;
8)平均斑块面积—AREA MN—(0,+∞)—值越小破碎化程度越大,值越大,景观聚集化程度低;
9)总面积—CA—ha—(0,+∞)—某一类型景观的面积之和;
10)景观形状指数—LSI—无单位—[1+∞)—描述整个景观内斑块形状的特点,值越大,斑块越分离;
11)斑块数量—NP—个—[1+∞)—类型或是景观镶嵌体中的斑块数量,值越大,这一类型的斑块数量越多;
12)总边缘长度—TE—m—;
13)边缘密度—ED—m/ha—;
—IJI—%——
[4按指标含义进行分类]
1)表面积的指标;
2)表密度大小及差异的指标;
3)表边缘性的指标;
4)表形状的指标;
5)表核心面积的指标;
6)表邻近度的指标;
7)表多样性的指标;
8)表聚散性的指标。
WhiteboxTools-ArcGIS
WhiteboxTools-ArcGIS是WhiteboxTools的 ArcGIS Python 工具箱,WhiteboxTools 是由圭尔夫大学地貌测量和水文地理研究小组的 John Lindsay 教授(网页;jblindsay )开发的高级地理空间数据分析平台。WhiteboxTools可用于执行常见的地理信息系统 (GIS) 分析操作,例如成本距离分析、距离缓冲和栅格重新分类。遥感和图像处理任务包括图像增强(例如全色锐化、对比度调整)、图像镶嵌、大量过滤操作、简单分类(k-means)和常见图像变换。

白盒工具还包含用于空间水文分析(例如流量累积、流域划分、河流网络分析、汇去除)、地形分析(例如常见地形指数,如坡度、曲率、湿度指数、山体阴影;测高分析;多尺度地形)的高级工具位置分析)和激光雷达数据处理。

可以询问 LiDAR 点云(LidarInfo、LidarHistogram)、分割、平铺和连接、分析异常值、插值到栅格(DEM、强度图像),并且可以对地面点进行分类或过滤。白盒工具不是制图或空间数据可视化包;相反,它旨在充当其他数据可视化软件(主要是 GIS)的分析后端。建议引用:Lindsay, JB (2016)。Whitebox GAT:地貌测量分析的案例研究。计算机与地球科学,95, 75-84。doi:10.1016/j.cageo.2016.07.003。
成果的内容
1、各期NPP数据(TIFF格式);
2、土地利用类型分布数据(shp格式和TIFF格式)研究所使用的遥感影像列表及原始影像预处理结果;
3、数据精度报告与分析(混淆矩阵、用户精度、生产者精度、总体精度);
4、数据处理说明书及详细的数据处理流程(word文档);
5、土地利用类型统计图表等。
参见:
GitHub - opengeos/WhiteboxTools-ArcGIS: ArcGIS Python Toolbox for WhiteboxTools
















 7979
7979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











