







 本文介绍了网络浏览器的发展历程,从早期的文本浏览器到现代浏览器,以及B/S模式与C/S模式的对比。讨论了RESTful API在构建Web服务中的角色,主流浏览器的结构和工作原理。最后,简述了JavaScript的事件循环机制,以及Canvas和WebGL在图形渲染中的应用,并以three.js和cannon.js为例展示了WebGL在3D图形和物理模拟中的实践。
本文介绍了网络浏览器的发展历程,从早期的文本浏览器到现代浏览器,以及B/S模式与C/S模式的对比。讨论了RESTful API在构建Web服务中的角色,主流浏览器的结构和工作原理。最后,简述了JavaScript的事件循环机制,以及Canvas和WebGL在图形渲染中的应用,并以three.js和cannon.js为例展示了WebGL在3D图形和物理模拟中的实践。
从网路冲浪开始
网络浏览器的发展史可以追溯到互联网的早期,随着时间的推移,浏览器已经经历了多次重大的变革和发展。

以下是网络浏览器发展史的一个简要概述:
1. 早期的文本浏览器
- 1990年:蒂姆·伯纳斯-李(Tim Berners-Lee)开发了第一个网络浏览器WorldWideWeb(后来更名为Nexus),运行在NeXT计算机上。同时,他还开发了第一个网页服务器和HTML。
- 1991年:伯纳斯-李的学生马克·安德森(Mark Andreessen)在伊利诺伊大学香槟分校参与开发了Mosaic,这是第一个广泛使用的图形界面浏览器。
2. 商业化和浏览器战争
- 1994年:安德森与吉姆·克拉克(Jim Clark)共同创立了Mosaic Communications Corporation,后来改名为Netscape Communications。同年,Netscape发布了Netscape Navigator,迅速成为市场领导者。
- 1995年:微软推出了Internet Explorer 1.0,并随Windows 95操作系统捆绑销售。这标志着浏览器战争的开始。
- 1996年:Opera浏览器由挪威的Opera Software公司首次发布。
3. 标准化和开放源代码
- 1998年:网景通信公司开源了其浏览器代码,创建了Mozilla项目,目标是开发一个开源的浏览器。
- 2001年:基于Mozilla代码,网景通信公司发布了Netscape 6,但市场占有率继续下降。
- 2002年:Phoenix(后来的Firefox)的第一个版本发布,它是Mozilla项目的衍生产品。
4. 现代浏览器的崛起
- 2003年:苹果公司发布了Safari浏览器,最初是Mac OS X的默认浏览器。
- 2008年:Google发布了Chrome浏览器,基于Webkit引擎,很快因其快速和简洁而受到欢迎。
- 2009年:Mozilla基金会发布了Firefox 3.5,引入了新的JavaScript引擎TraceMonkey,显著提高了性能。
5. 移动和多样化
- 2010年代:随着智能手机的普及,移动浏览器开始快速发展。Chrome、Safari、Firefox和Opera等都在移动平台上推出了相应的版本。
- 2013年:微软推出了Internet Explorer 11,并开始开发新的浏览器Edge。
- 2015年:Mozilla基金会发布了Firefox 44,支持多个操作系统和设备。
- 2016年:微软的Edge浏览器随Windows 10周年更新发布,取代了Internet Explorer成为新的默认浏览器。
6. 当前和未来
- 至今:浏览器继续发展,重点包括性能提升、安全性增强、隐私保护、对新兴Web标准的支持等。Chrome因其快速、安全、丰富的扩展程序而成为市场领导者。
- 未来:随着Web技术的不断进步,浏览器将继续向着更加快速、安全、用户友好的方向发展。新的浏览技术,如WebAssembly和Service Workers,将进一步扩展浏览器的功能。

网络浏览器的发展史见证了互联网的快速成长和变革,从简单的文本浏览器到功能丰富的现代浏览器,它们已经成为我们日常生活中不可或缺的一部分。
C/S两层到B/S三层
B/S(Browser/Server,浏览器/服务器)模式和C/S(Client/Server,客户端/服务器)模式是两种常见的网络架构模式,它们在客户端和服务器之间的交互方式、软件部署、用户体验等方面有着显著的区别。
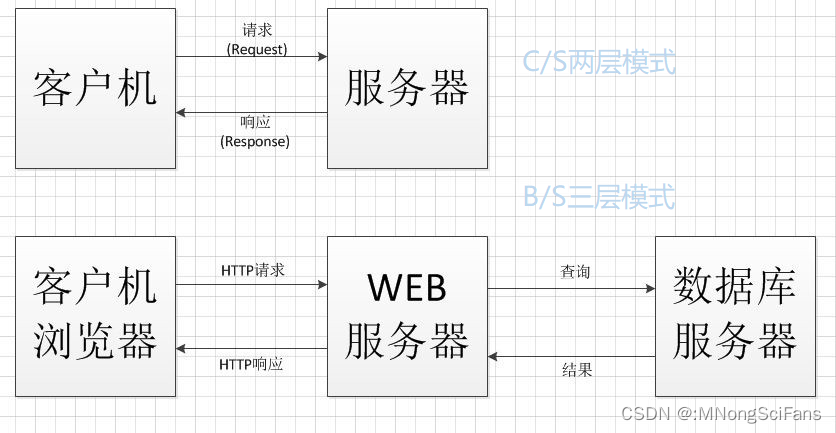
B/S模式
B/S模式是一种基于网络的架构,用户通过浏览器访问服务。主要特点包括:
- 集中管理:应用程序的核心逻辑和数据存储在服务器上,便于集中管理和维护。
- 客户端简单:用户通过浏览器访问服务,无需在客户端安装额外的软件。
- 跨平台兼容性:由于浏览器的普遍存在,B/S模式的应用程序通常能够跨不同的操作系统和设备工作。
- 网络依赖性:B/S模式需要持续的网络连接,客户端的体验受网络速度和质量的影响较大。
- 更新方便:服务器端更新应用程序后,所有用户都可以立即使用最新版本。
C/S模式
C/S模式是一种传统的客户端-服务器架构,客户端和服务器之间通常有直接的连接。主要特点包括:
- 分布式架构:客户端和服务器分工明确,客户端负责用户界面和部分业务逻辑,服务器负责数据处理和存储。
- 客户端复杂:客户端通常需要安装专用的客户端软件,这可能涉及到跨平台的兼容性问题。
- 性能优势:部分业务逻辑在客户端处理,可以减少服务器负载,提高性能。
- 离线工作:某些C/S应用允许客户端在离线状态下工作,减少对网络的依赖。
- 更新困难:客户端软件的更新需要用户手动进行,这可能导致不同用户使用不同版本的应用程序。
对比分析
- 用户体验:B/S模式通常提供更加一致的用户体验,而C/S模式可以提供更加丰富和响应迅速的用户界面。
- 部署和维护:B/S模式在部署和维护方面更加简便,而C/S模式可能需要更多的客户端配置和维护工作。
- 网络依赖:B/S模式更加依赖于网络,而C/S模式可以在一定程度上减少对网络的依赖。
- 性能和响应:C/S模式在性能和响应速度方面可能具有优势,尤其是对于复杂和计算密集型的应用。
- 适用场景:B/S模式适合于信息查询、在线交易等Web应用,而C/S模式适合于需要高性能、复杂客户端逻辑或离线工作的应用。
选择B/S还是C/S模式取决于应用的需求、用户体验的要求、网络的可靠性以及维护和部署的便利性等因素。随着技术的发展,这两种模式也在不断地演变和融合,例如,通过使用HTML5和WebAssembly等技术,B/S应用可以提供更加丰富的客户端体验。
RESTful API
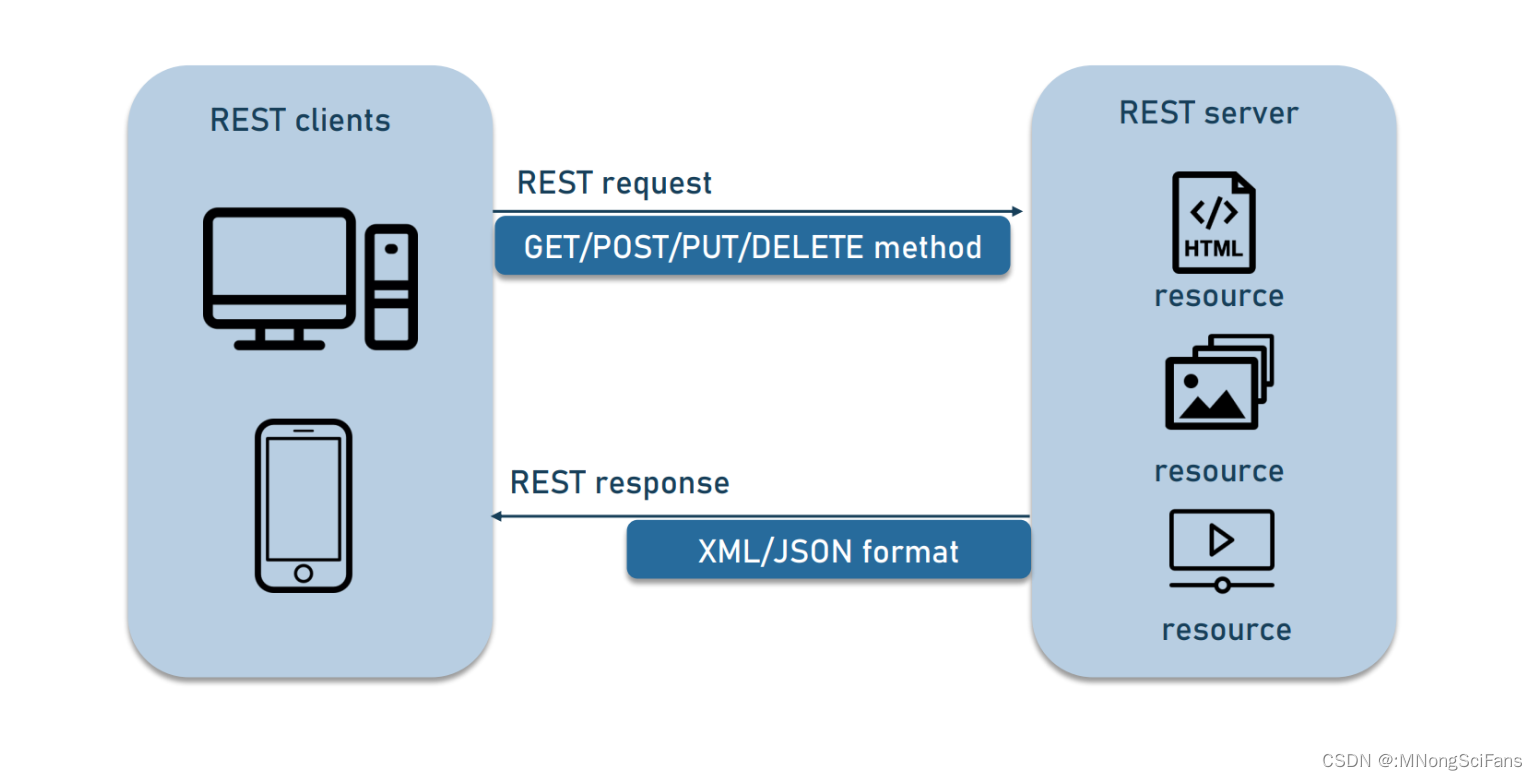
RESTful API是基于REST(Representational State Transfer)原则设计的一种软件架构风格,用于在网络上构建分布式系统。它使用HTTP协议进行通信,并通过HTTP动词(GET,POST,PUT,DELETE等)来执行操作。
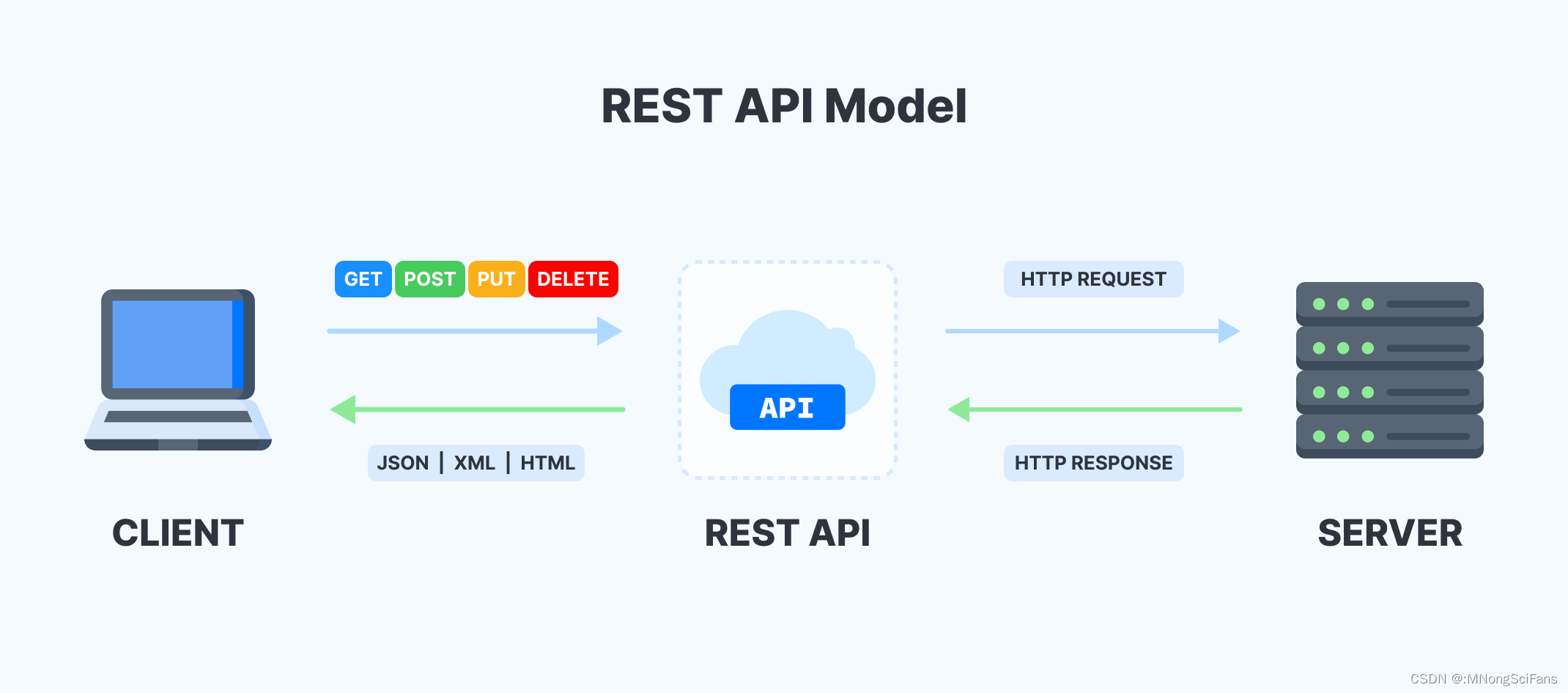
RESTful API的设计原则包括:
-
资源:将应用程序的数据和功能表示为资源,并使用唯一的URL(统一资源定位符)来标识每个资源。
-
表示:资源的表示应该使用通用的标准格式,例如JSON(JavaScript Object Notation)或XML(eXtensible Markup Language)。
-
状态转移:通过HTTP动词来执行对资源的操作,例如GET获取资源,POST创建新资源,PUT更新资源,DELETE删除资源。
-
无状态:API应该是无状态的,服务器不会保存客户端的状态。每个请求都是独立的,每个请求都应包含足够的信息来处理该请求,简化了系统设计,提高了可伸缩性。
使用RESTful API来构建web应用程序的步骤如下:
-
定义资源:确定应用程序中的数据和功能,将其表示为资源,并为每个资源定义唯一的URL。
-
设计URL:根据资源的层次结构和关系来设计URL。使用合适的HTTP动词来表示对资源的操作。
-
实现HTTP方法:根据定义的URL和HTTP方法(如GET、POST、PUT、DELETE),实现相应的资源的CRUD(创建、读取、更新、删除)操作功能。例如,使用GET方法来获取资源的列表或特定资源的详细信息,使用POST方法创建新资源,使用PUT方法更新资源,使用DELETE方法删除资源。RESTful API通常遵循统一的接口设计原则,使用标准的HTTP方法(如GET、POST、PUT、DELETE)来进行资源的CRUD(创建、读取、更新、删除)操作。利用HTTP缓存机制,减少客户端和服务器之间的数据传输,提高性能。
-
处理错误:在API的设计中考虑错误处理机制,为每种可能的错误情况定义合适的HTTP状态码,并返回相应的错误信息。
-
身份验证和授权:如果需要,为API添加身份验证和授权机制,以确保只有授权用户可以访问资源。
-
文档化:为API提供清晰的文档,包括资源的定义、URL的示例和参数的说明,以便开发人员可以使用和理解API。
RESTful API的设计和使用促进了不同系统之间的互操作性。它是现代微服务架构和云服务的关键组成部分。通过遵循REST原则,开发者可以创建易于理解、可扩展、可维护、可靠且高效的API,实现数据的共享和交互,提供更好的用户体验。
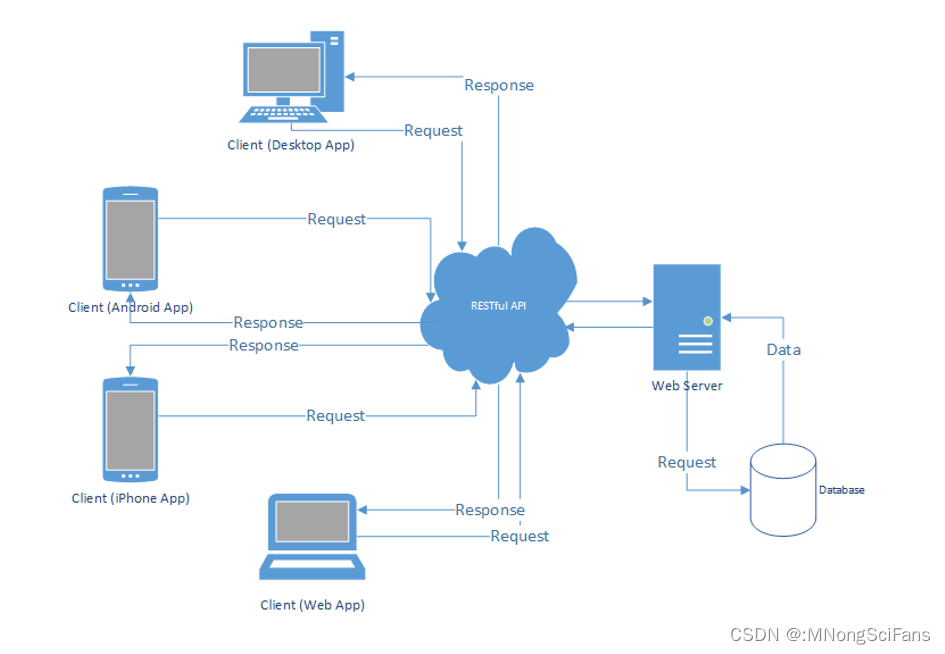
RESTful API在实际项目中的应用非常广泛,尤其是在构建微服务架构、前后端分离的应用程序、以及提供第三方服务的平台上。以下是一些具体的应用场景:
-
前后端分离:在现代Web应用中,通常会将前端(用户界面)和后端(服务器逻辑)分离。RESTful API作为前后端之间的通信桥梁,前端通过HTTP请求与后端进行数据交互,后端返回JSON或XML格式的数据。
-
移动应用开发:移动应用经常使用RESTful API与服务器进行数据同步。例如,一个天气应用可能会使用API来获取天气预报数据。
-
微服务架构:在微服务架构中,不同的服务通常通过网络进行通信。RESTful API是服务之间进行通信的一种常见方式,每个服务都暴露出一组API供其他服务调用。
-
第三方集成:许多企业和开发者会提供公开的API,允许第三方开发者利用这些服务来增强自己的应用程序。例如,Google Maps API允许开发者将地图集成到自己的应用中。
-
物联网(IoT):物联网设备通常需要将收集到的数据发送到服务器进行分析和处理。RESTful API可以用于设备与服务器之间的数据交换。
-
数据分析和报告:数据分析工具可以使用RESTful API从不同的数据源获取数据,然后进行加工和分析,生成报告。
在实际应用中,设计和实现RESTful API时需要考虑以下几个方面:
- 资源的设计:确定API要操作的资源,并为它们设计合理的URL结构。
- HTTP方法的使用:根据资源的CRUD操作,选择合适的HTTP方法(GET、POST、PUT、DELETE等)。
- 状态码的返回:使用合适的HTTP状态码来反映请求的处理结果。
- 数据的格式:通常使用JSON或XML格式来交换数据。
- 安全性:考虑API的安全性,如使用OAuth、JWT等机制进行身份验证和授权。
- 限流和缓存:为了防止滥用和提高性能,可以实施限流和缓存策略。
RESTful API的成功应用需要在设计、实现和文档编写方面下功夫,确保API易于理解、使用和维护。
主流浏览器
目前,常用的浏览器主要有:Chrome、IE(Edge)、Safari、Firefox等。不同的浏览器在结构方面虽然有所差异,但是整体的设计理念是相似的。因此,可以抽象得到如下图所示的参考结构:
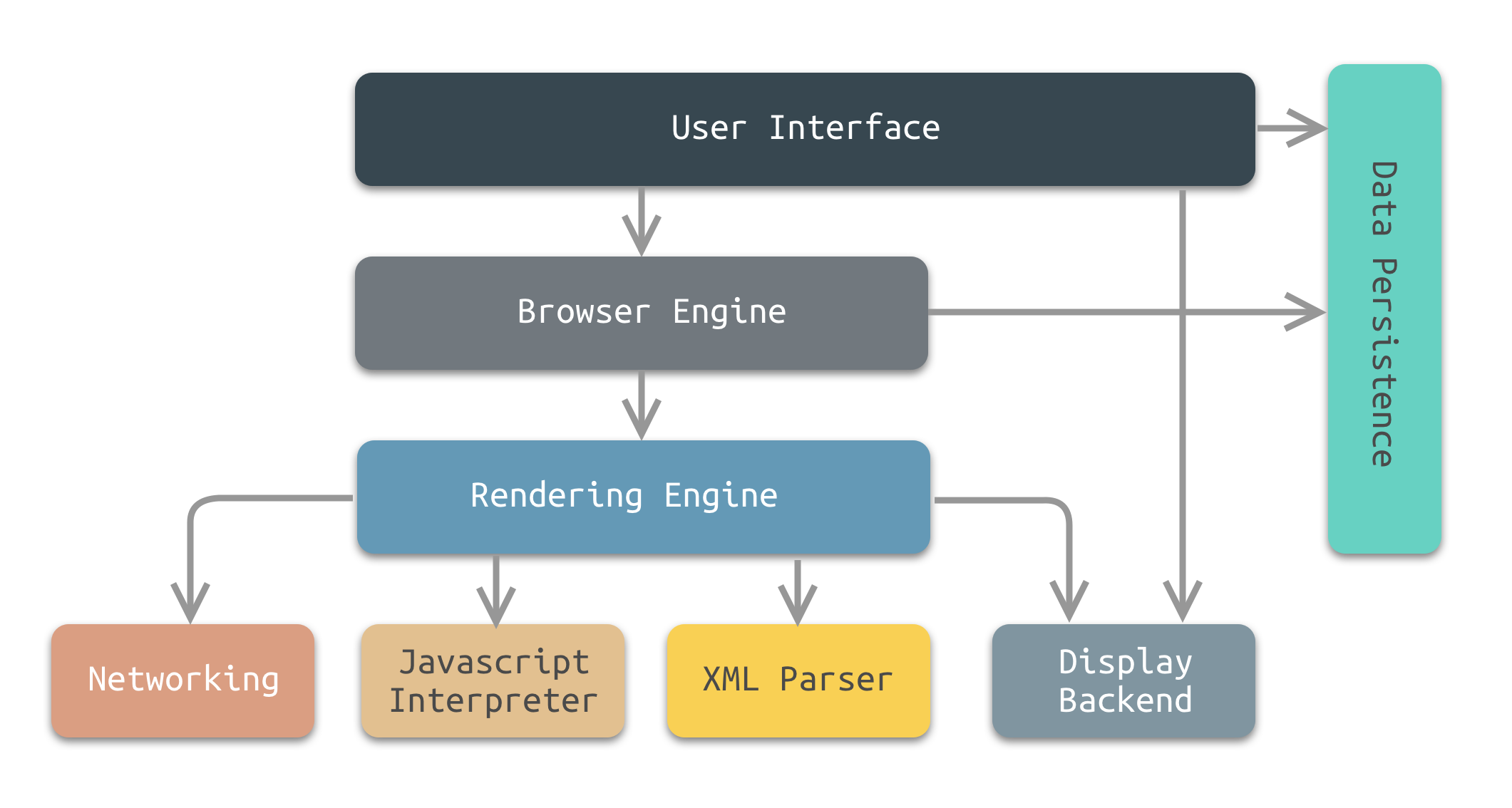
浏览器的结构
浏览器的抽象分层结构图中将浏览器分成了以下8个子系统:
- 用户界面(User Interface)
用户界面主要包括工具栏、地址栏、前进/后退按钮、书签菜单、可视化页面加载进度、智能下载处理、首选项、打印等。除了浏览器主窗口显示请求的页面之外,其他显示的部分都属于用户界面。
用户界面还可以与桌面环境集成,以提供浏览器会话管理或与其他桌面应用程序的通信。 - 浏览器引擎(Browser Engine)
浏览器引擎是一个可嵌入的组件,其为渲染引擎提供高级接口。
浏览器引擎可以加载一个给定的URI,并支持诸如:前进/后退/重新加载等浏览操作。
浏览器引擎提供查看浏览会话的各个方面的挂钩,例如:当前页面加载进度、JavaScript alert。
浏览器引擎还允许查询/修改渲染引擎设置。 - 渲染引擎(Rendering Engine)
渲染引擎为指定的URI生成可视化的表示。
渲染引擎能够显示HTML和XML文档,可选择CSS样式,以及嵌入式内容(如图片)。
渲染引擎能够准确计算页面布局,可使用“回流”算法逐步调整页面元素的位置。
渲染引擎内部包含HTML解析器。 - 网络(Networking)
网络系统实现HTTP和FTP等文件传输协议。 网络系统可以在不同的字符集之间进行转换,为文件解析MIME媒体类型。 网络系统可以实现最近检索资源的缓存功能。 - JavaScript解释器(JavaScript Interpreter)
JavaScript解释器能够解释并执行嵌入在网页中的JavaScript(又称ECMAScript)代码。 为了安全起见,浏览器引擎或渲染引擎可能会禁用某些JavaScript功能,如弹出窗口的打开。 - XML解析器(XML Parser)
XML解析器可以将XML文档解析成文档对象模型(Document Object Model,DOM)树。 XML解析器是浏览器架构中复用最多的子系统之一,几乎所有的浏览器实现都利用现有的XML解析器,而不是从头开始创建自己的XML解析器。 - 显示后端(Display Backend)
显示后端提供绘图和窗口原语,包括:用户界面控件集合、字体集合。 - 数据持久层(Data Persistence)
数据持久层将与浏览会话相关联的各种数据存储在硬盘上。 这些数据可能是诸如:书签、工具栏设置等这样的高级数据,也可能是诸如:Cookie,安全证书、缓存等这样的低级数据。
渲染引擎
浏览器的组成模块众多,而渲染引擎则是浏览器中最重要的模块(渲染引擎有时候也被称为“浏览器内核”,这种说法并不严谨,不推荐使用)。目前,常见的渲染引擎有Trident、Gecko、WebKit等。下表所示为几种渲染引擎在不同浏览器中的应用:

网路HTML文档
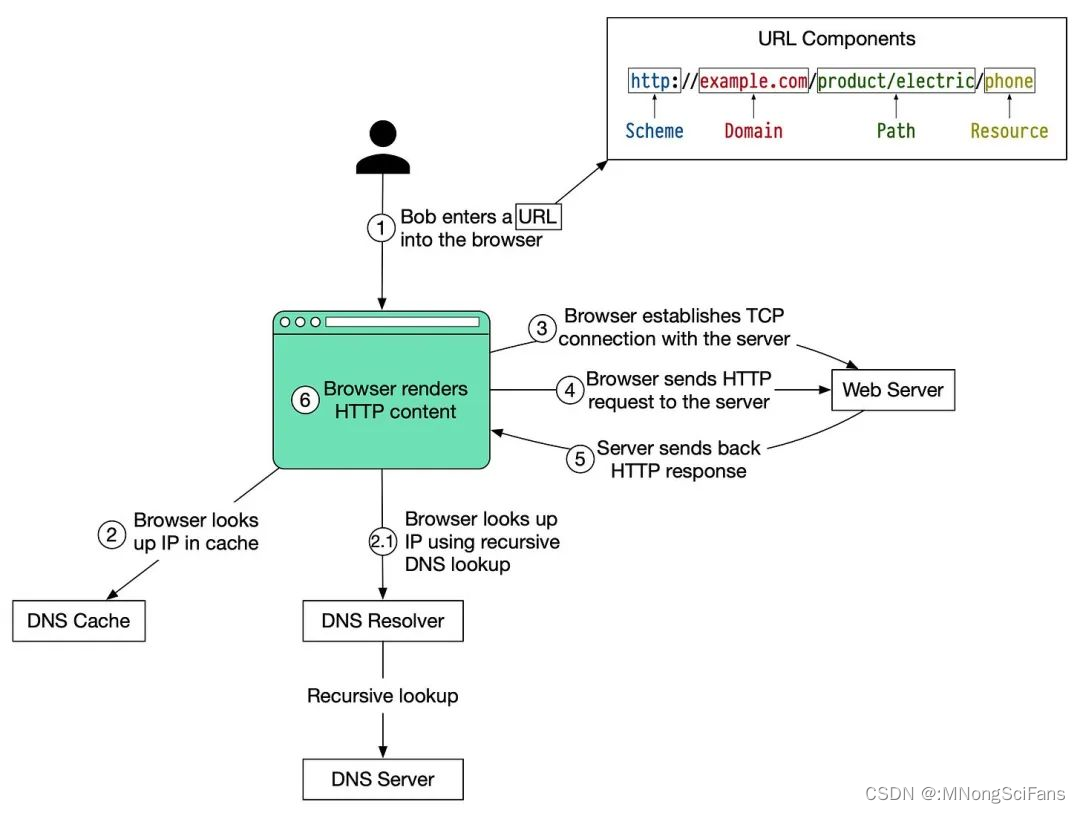
TCP三次握手
TCP三次握手是TCP/IP协议中用于建立网络连接的过程。它确保了数据的可靠传输。以下是TCP三次握手的步骤:
-
第一次握手(SYN):客户端发送一个带有SYN(同步序列编号)标志的数据包给服务器,以便开始一个新的连接。
-
第二次握手(SYN-ACK):服务器收到SYN后,会应答一个带有SYN-ACK(同步和确认)标志的数据包,确认收到了客户端的SYN,同时也告诉客户端,服务器已经准备好建立连接了。
-
第三次握手(ACK):客户端收到服务器的SYN-ACK后,会发送一个带有ACK(确认)标志的数据包,确认收到了服务器的SYN-ACK。此时,连接建立成功,客户端和服务器可以开始数据传输。
TCP四次挥手
TCP四次挥手是TCP/IP协议中用于终止网络连接的过程。以下是TCP四次挥手的步骤:
-
第一次挥手(FIN):当客户端完成数据传输后,它会发送一个带有FIN(结束)标志的数据包给服务器,请求关闭连接。
-
第二次挥手(ACK):服务器收到这个FIN请求后,会发送一个带有ACK标志的数据包,确认收到了客户端的FIN请求。
-
第三次挥手(FIN):服务器准备好关闭连接时,也会发送一个带有FIN标志的数据包给客户端。
-
第四次挥手(ACK):客户端收到服务器的FIN请求后,会发送一个带有ACK标志的数据包,确认收到了服务器的FIN请求。在发送完这个ACK后,客户端会等待一段时间(通常是2倍的最大段生命周期MSL),以确保服务器收到了客户端的ACK包。
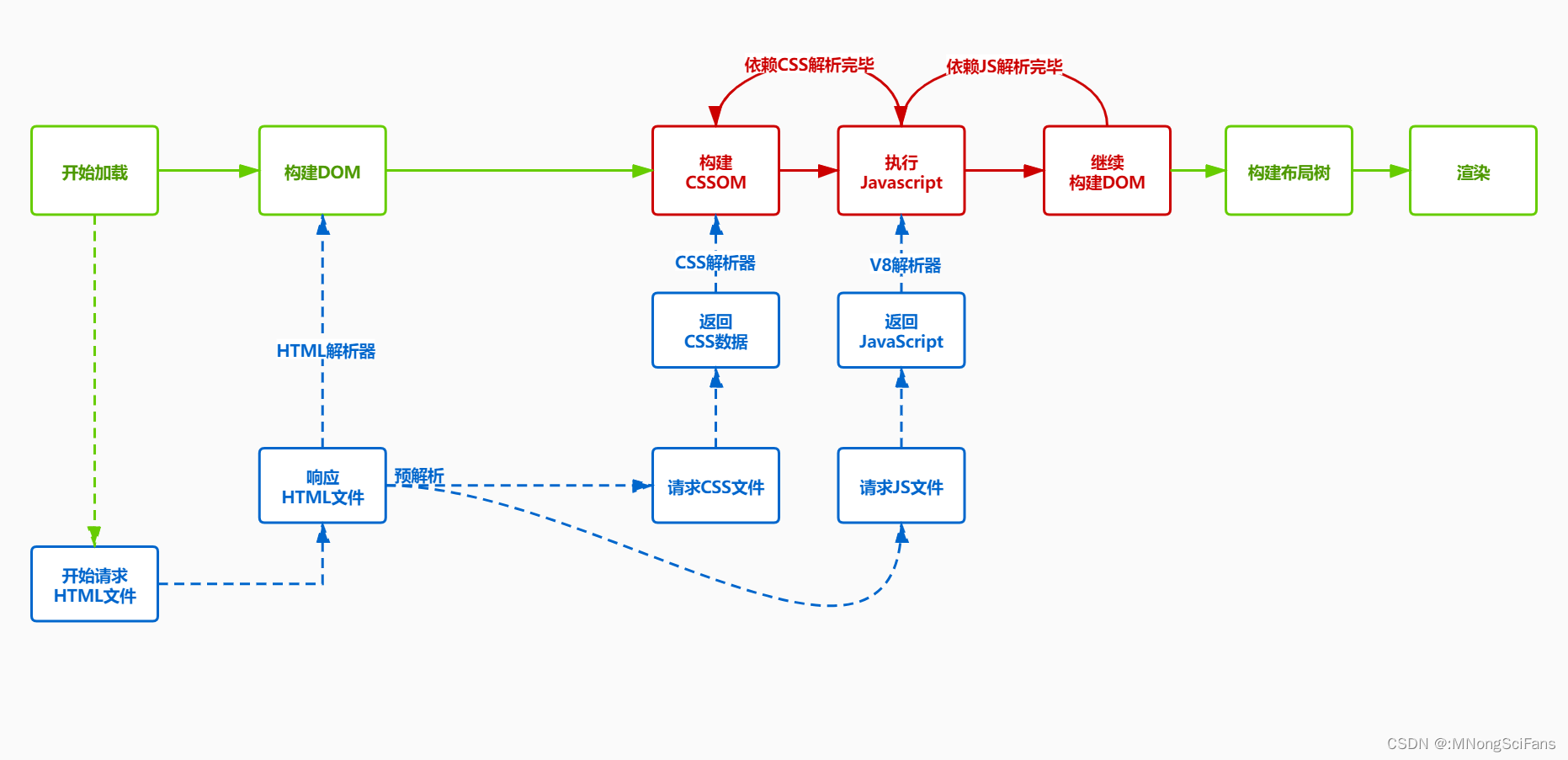
文档解析流程
浏览器加载和解析HTML文档的过程的基本步骤:
-
域名解析(DNS查询):浏览器首先解析URL中的域名,找到对应的IP地址。
-
建立连接:浏览器使用TCP三次握手与服务器建立连接。
-
发送请求:浏览器发送HTTP请求,请求服务器提供HTML文档。
-
接收响应:服务器处理请求后,返回HTTP响应,包含HTML文档的内容。
-
构建DOM树:浏览器解析HTML文档,构建DOM(文档对象模型)树。DOM树是HTML文档的树形结构表示,用于表示文档中的元素和它们之间的关系。
-
执行脚本:如果HTML文档中包含JavaScript脚本,浏览器会执行这些脚本,可能会修改DOM树。
-
加载外部资源:浏览器加载HTML文档中引用的外部资源,如CSS样式表、图片、视频等。
-
渲染页面:浏览器根据DOM树和CSS样式,计算页面的布局,并渲染页面。
-
交互:用户与页面交互,浏览器根据交互事件进行相应的处理和响应。
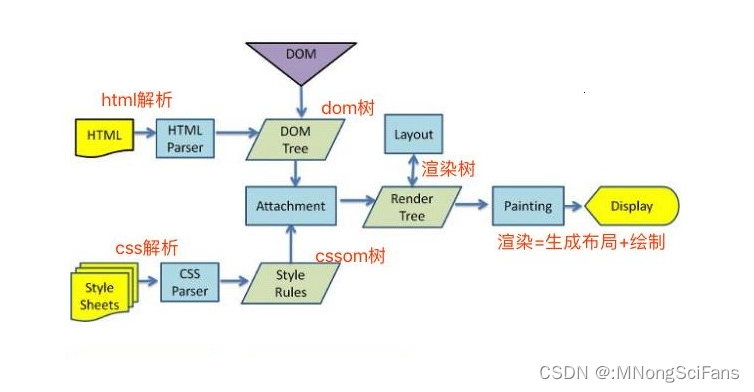
- Parsing HTML to Construct DOM Tree 渲染引擎使用HTML解析器(调用XML解析器)解析HTML(XML)文档,将各个HTML(XML)元素逐个转化成DOM节点,从而生成DOM树。同时,渲染引擎使用CSS解析器解析外部CSS文件以及HTML(XML)元素中的样式规则。元素中带有视觉指令的样式规则将用于下一步,以创建另一个树结构:渲染树。
- Render Tree construction 渲染引擎使用第1步CSS解析器解析得到的样式规则,将其附着到DOM树上,从而构成渲染树。
渲染树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。 - Layout of Render Tree 渲染树构建完毕之后,进入本阶段进行“布局”,也就是为每个节点分配一个应出现在屏幕上的确切坐标。
- Painting Render Tree 渲染引擎将遍历渲染树,并调用显示后端将每个节点绘制出来。
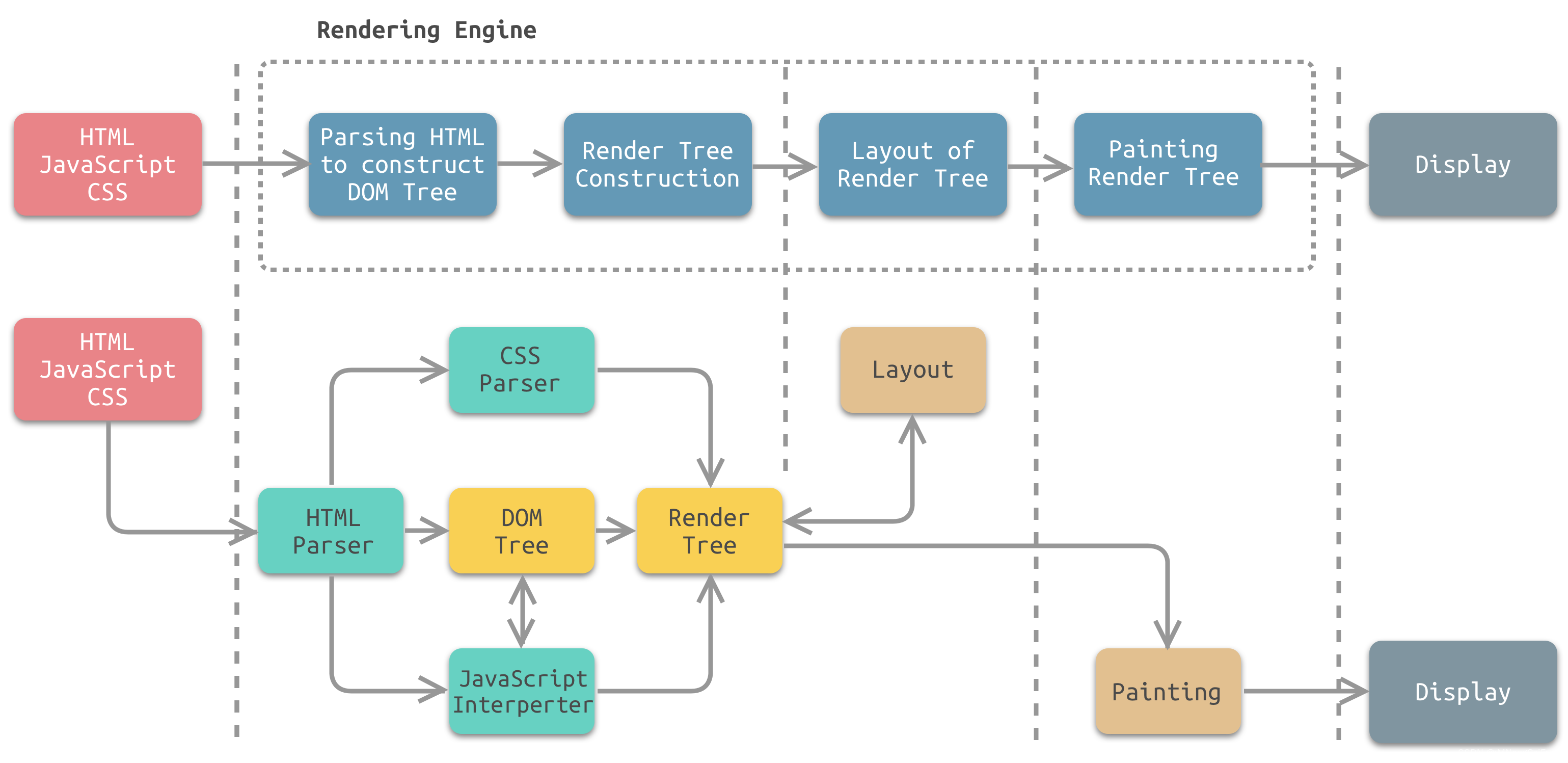
- HTML(XML)解析器
解析HTML(XML)文档,主要作用是将HTML(XML)文档转换成DOM树。 - CSS解析器
将DOM中的各个元素对象进行计算,获取样式信息,用于渲染树的构建。 - JavaScript解释器
使用JavaScript可以修改网页的内容、CSS规则等。JavaScript解释器能够解释JavaScript代码,并通过DOM接口和CSSOM接口来修改网页内容、样式规则,从而改变渲染结果。 - 布局
DOM创建之后,渲染引擎将其中的元素对象与样式规则进行结合,可以得到渲染树。布局则是针对渲染树,计算其各个元素的大小、位置等布局信息。 - 绘图
使用图形库将布局计算后的渲染树绘制成可视化的图像结果。
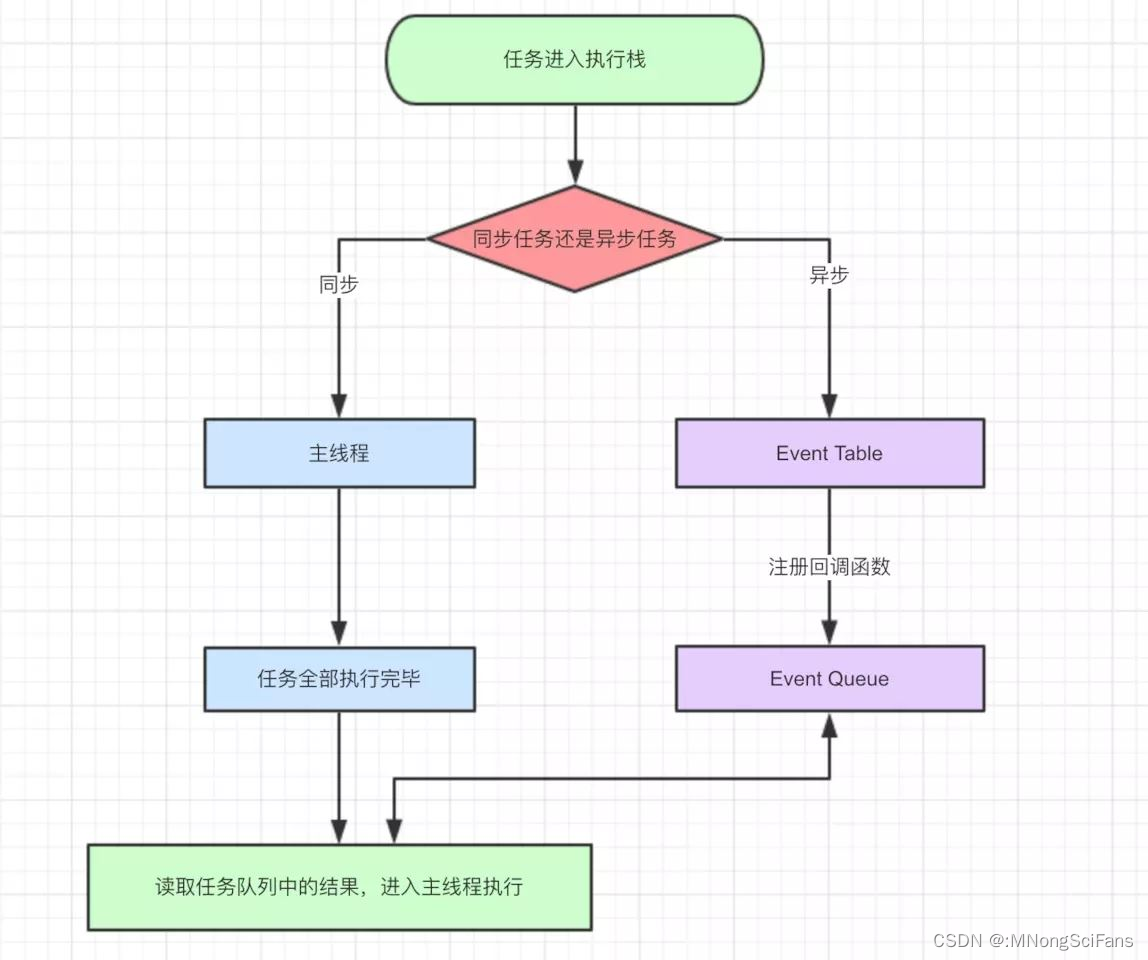
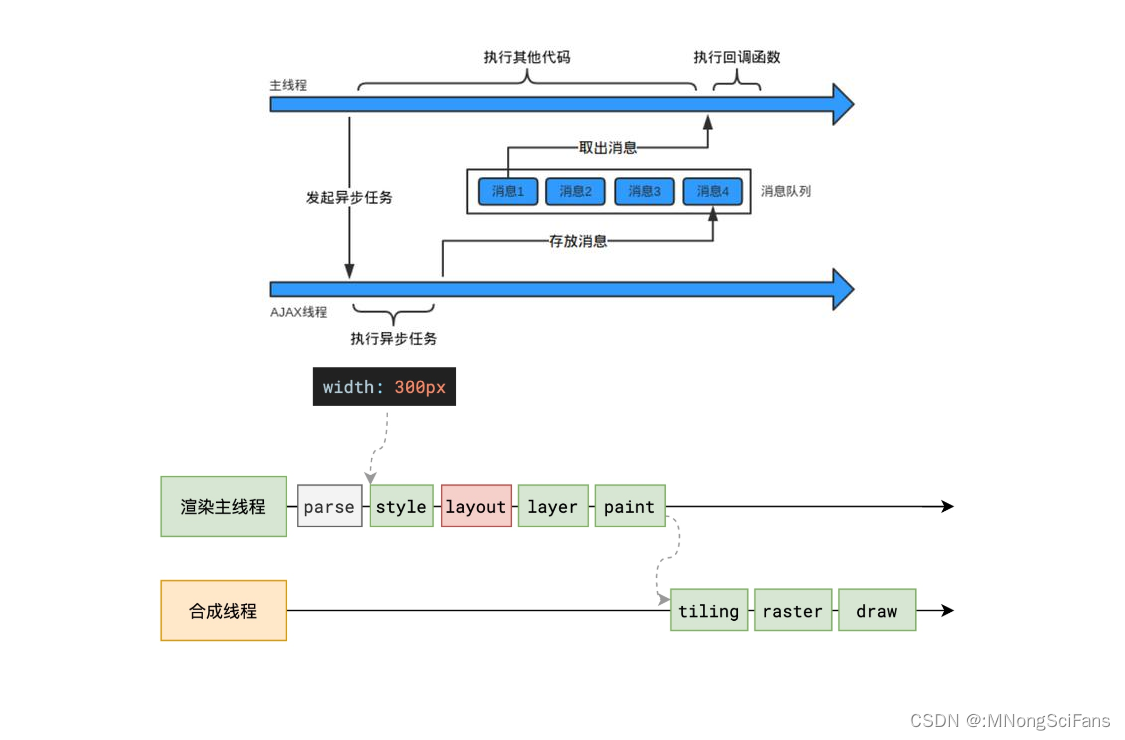
JavaScript 语言的一大特点就是单线程,同一个时间只能做一件事。单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。在最新的HTML5中提出了Web-Worker,但JavaScript 是单线程这一核心仍未改变。所以一切JavaScript 版的"多线程"都是用单线程模拟出来的。
JavaScript 语言的设计者意识到这个问题,将所有任务分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous),在所有同步任务执行完之前,任何的异步任务是不会执行的。
当我们打开网站时,网页的渲染过程就是一大堆同步任务,比如页面骨架和页面元素的渲染。
而像加载图片音乐之类占用资源大耗时久的任务,就是异步任务。
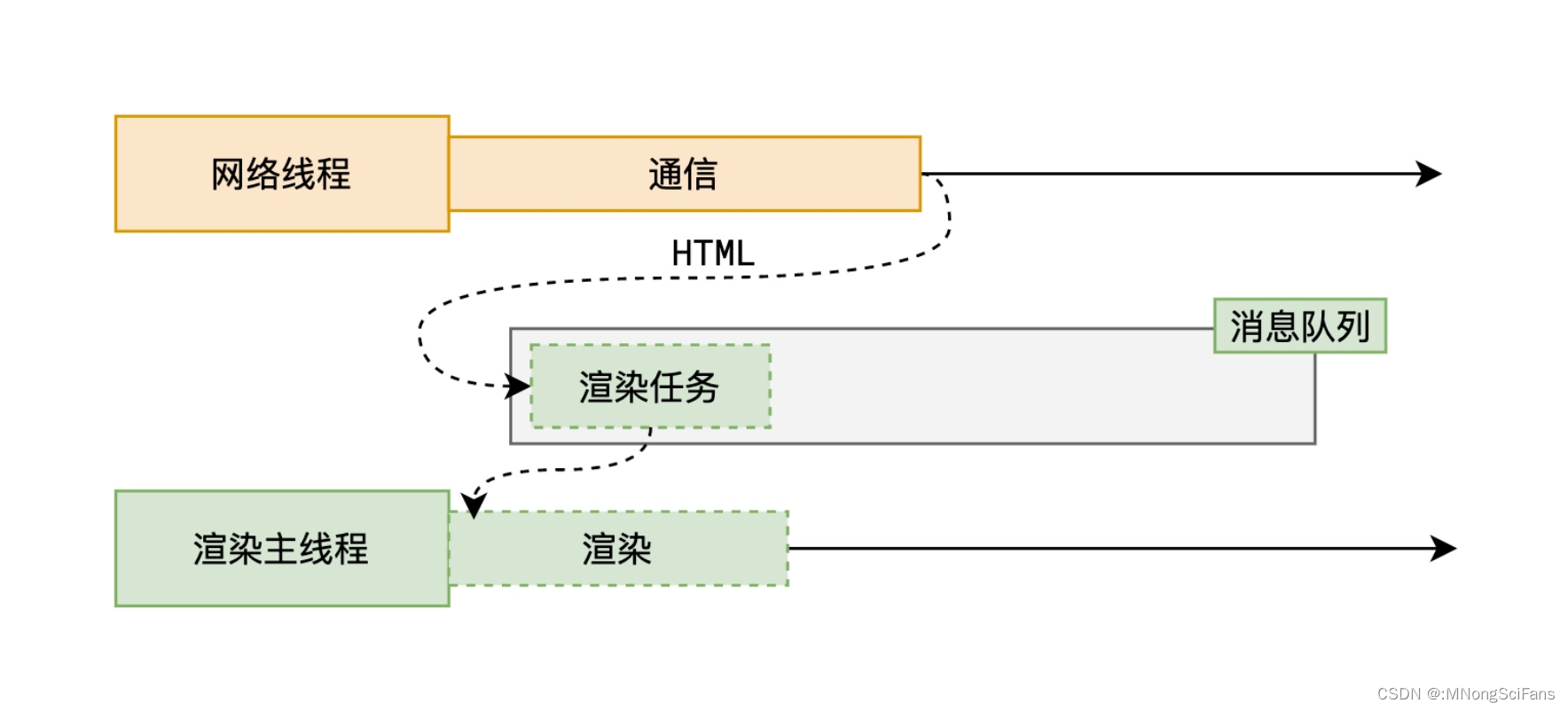
同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入 Event Table 并注册函数。当指定的事情完成时,Event Table 会将这个函数移入任务队列(Event Queue,机制为先进先出)。主线程内的任务执行完毕为空,会去 Event Queue 读取对应的函数,进入主线程执行。上述过程会不断重复,也就是常说的 Event Loop(事件循环)。
怎么知道主线程执行栈为空?js 引擎存在 monitoring process 进程,会持续不断的检查主线程执行栈是否为空,一旦为空,就会去 Event Queue 那里检查是否有等待被调用的函数。主线程的执行过程:主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为 Event Loop(事件循环)。只要主线程空了,就会去读取"任务队列",这就是 JavaScript 的运行机制。
在网络浏览器中,事件循环(event loop)是一个核心的概念,在事件循环中,每进行一次循环操作称为tick,它负责处理各种异步事件,如用户输入、网络请求、定时器等。事件循环可以分为宏任务(macrotasks)和微任务(microtasks)。了解这两种任务对于理解JavaScript的异步编程非常重要。JS 异步中 宏任务(macrotasks)、微任务(microtasks)执行顺序。
JS 异步有一个机制,就是遇到宏任务,先执行宏任务,将宏任务放入 Event Queue,然后再执行微任务,将微任务放入 Event Queue,但是,这两个 Queue 不是一个 Queue。当你往外拿的时候先从微任务里拿这个回调函数,然后再从宏任务的 Queue 拿宏任务的回调函数。
我们知道setTimeout这个函数,是经过指定时间后,把要执行的任务(本例中为task())加入到Event Queue中,又因为是单线程任务要一个一个执行,如果前面的任务需要的时间太久,那么只能等着,导致真正的延迟时间远远大于设定的定时器时间。setTimeout(fn,0)这样的代码,0秒后执行又是什么意思呢?是不是可以立即执行呢?答案是不会的,setTimeout(fn,0)的含义是,指定某个任务在主线程最早可得的空闲时间执行,意思就是不用再等多少秒了,只要主线程执行栈内的同步任务全部执行完成,栈为空就马上执行。
setInterval是循环的执行。对于执行顺序来说,setInterval会每隔指定的时间将注册的函数置入Event Queue,如果前面的任务耗时太久,那么同样需要等待。
唯一需要注意的一点是,对于setInterval(fn,ms)来说,我们已经知道不是每过ms秒会执行一次fn,而是每过ms秒,会有fn进入Event Queue。一旦setInterval的回调函数fn执行时间超过了延迟时间ms,那么就完全看不出来有时间间隔了。
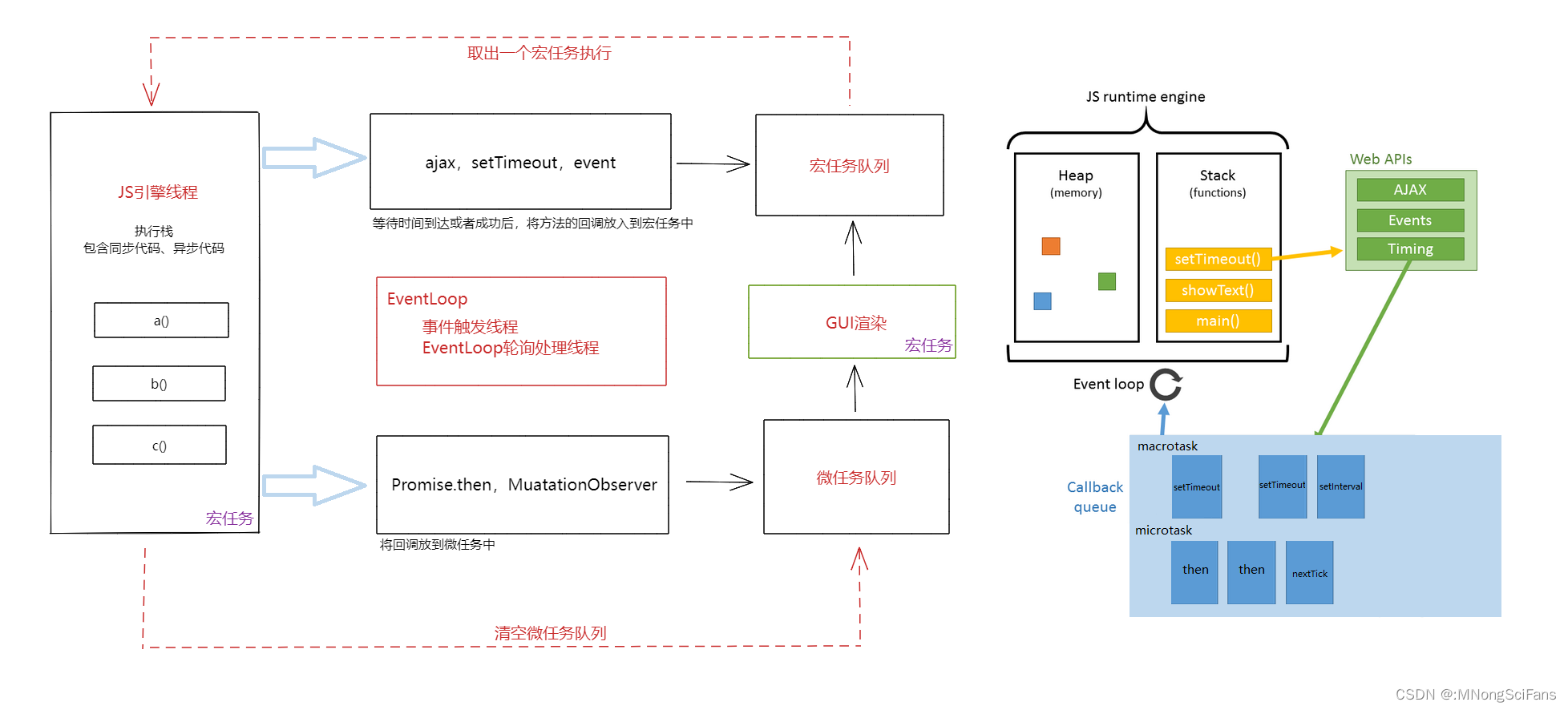
process.nextTick(callback)类似node.js版的"setTimeout",在事件循环的下一次循环中调用 callback 回调函数。除了广义的同步任务和异步任务,我们对任务有更精细的定义:
宏任务主要包含:script( 整体代码)、setTimeout、setInterval、I/O、UI 交互事件、setImmediate(Node.js 环境)
微任务主要包含:Promise、MutaionObserver、process.nextTick(Node.js 环境)
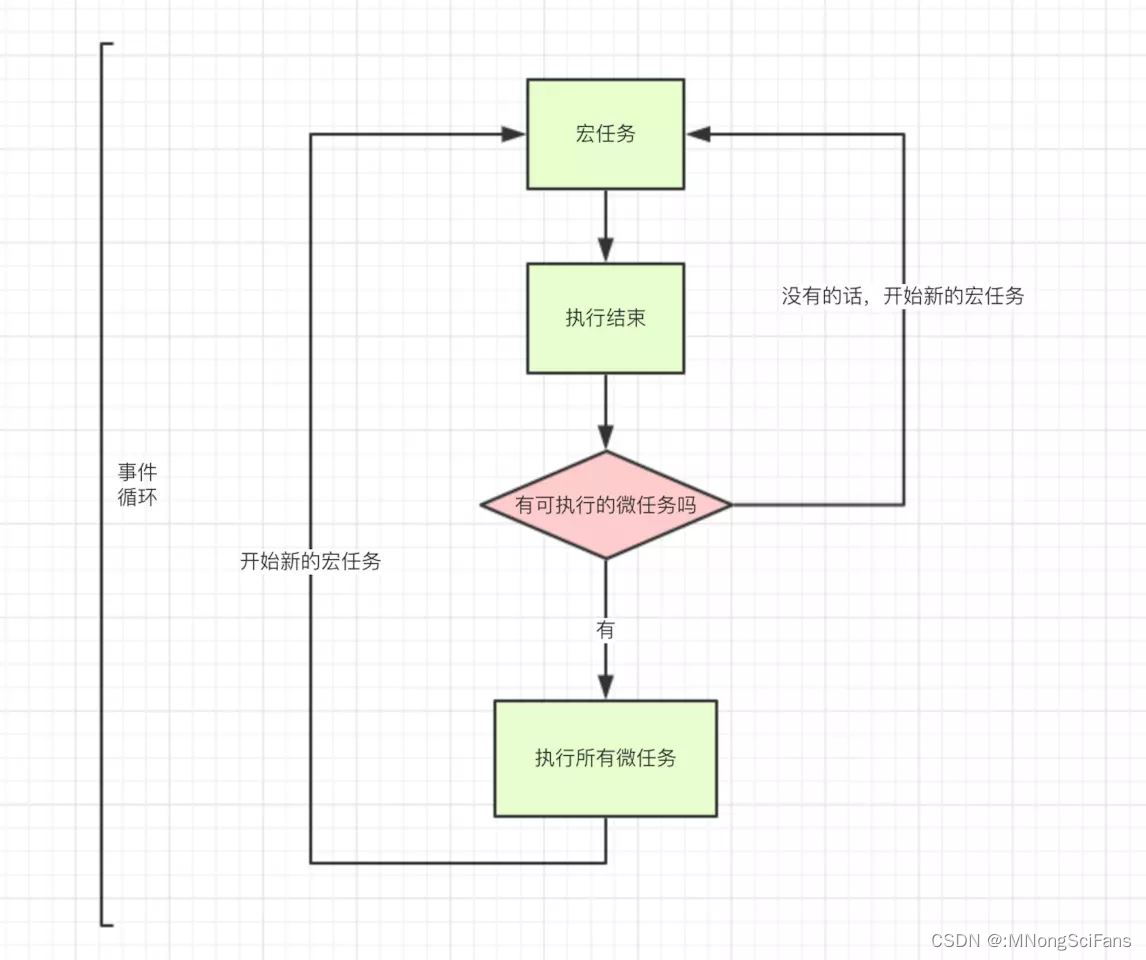
不同类型的任务会进入对应的Event Queue,比如setTimeout和setInterval会进入相同的Event Queue。事件循环的顺序,决定js代码的执行顺序。进入整体代码(宏任务)后,开始第一次循环。接着执行所有的微任务。然后再次从宏任务开始,找到其中一个任务队列执行完毕,再执行所有的微任务。
async 和 await 用了同步的方式去做异步,async 定义的函数的返回值都是 promise,await 后面的函数会先执行一遍,然后就会跳出整个 async 函数来执行后面js栈的代码。
宏任务(Macrotasks)
宏任务是指那些在浏览器事件循环中运行的长时间任务。它们通常由浏览器核心引擎(如JavaScript引擎)执行。宏任务包括以下几种:
-
script:这是最常见的宏任务,包括JavaScript代码。当页面加载时,HTML解析完成后,JavaScript代码会作为一个宏任务执行。
-
setTimeout:这是一个异步执行的宏任务,它在指定的毫秒数后执行。
-
setInterval:这也是一个异步执行的宏任务,与setTimeout类似,但它会在指定的时间间隔内重复执行。
-
I/O:这包括所有与输入/输出相关的任务,如文件读写、网络请求等。
-
UI rendering:这涉及浏览器渲染界面和响应用户输入,如点击、滚动等。
-
postMessage:这是一个允许跨源通信的API,当一个源向另一个源发送消息时,它会产生一个宏任务。
微任务(Microtasks)
微任务是指那些在浏览器事件循环中快速执行的任务。它们通常用于处理JavaScript引擎内部的操作,如Promise的解决和拒绝。微任务包括以下几种:
-
Promise:当Promise状态改变时,它们会被添加到微任务队列中。
-
MutationObserver:这是一个API,用于监听DOM的变动,当DOM发生变化时,它会产生一个微任务。
-
Observer:这是一个旧版本的MutationObserver,现在已经不推荐使用。
-
Async/Await:当使用async/await语法执行Promise时,它们会添加到微任务队列中。
-
IntersectionObserver:这是一个API,用于检测目标元素是否进入视口,如果进入,它会产生一个微任务。
事件循环的工作原理
当一个新的任务被添加到事件循环中时,它会按照以下顺序执行:
- 执行当前宏任务队列中的任务。
- 执行当前微任务队列中的所有任务。
- 重复步骤1和2,直到宏任务和微任务队列都为空。
这个过程会持续进行,直到所有任务都执行完毕。微任务通常在宏任务之后立即执行,但有时它们也可能在某些情况下提前执行。
了解宏任务和微任务对于编写高效的JavaScript代码非常重要,尤其是在处理异步操作时。通过合理地使用这两种任务,可以优化代码的执行顺序和性能。
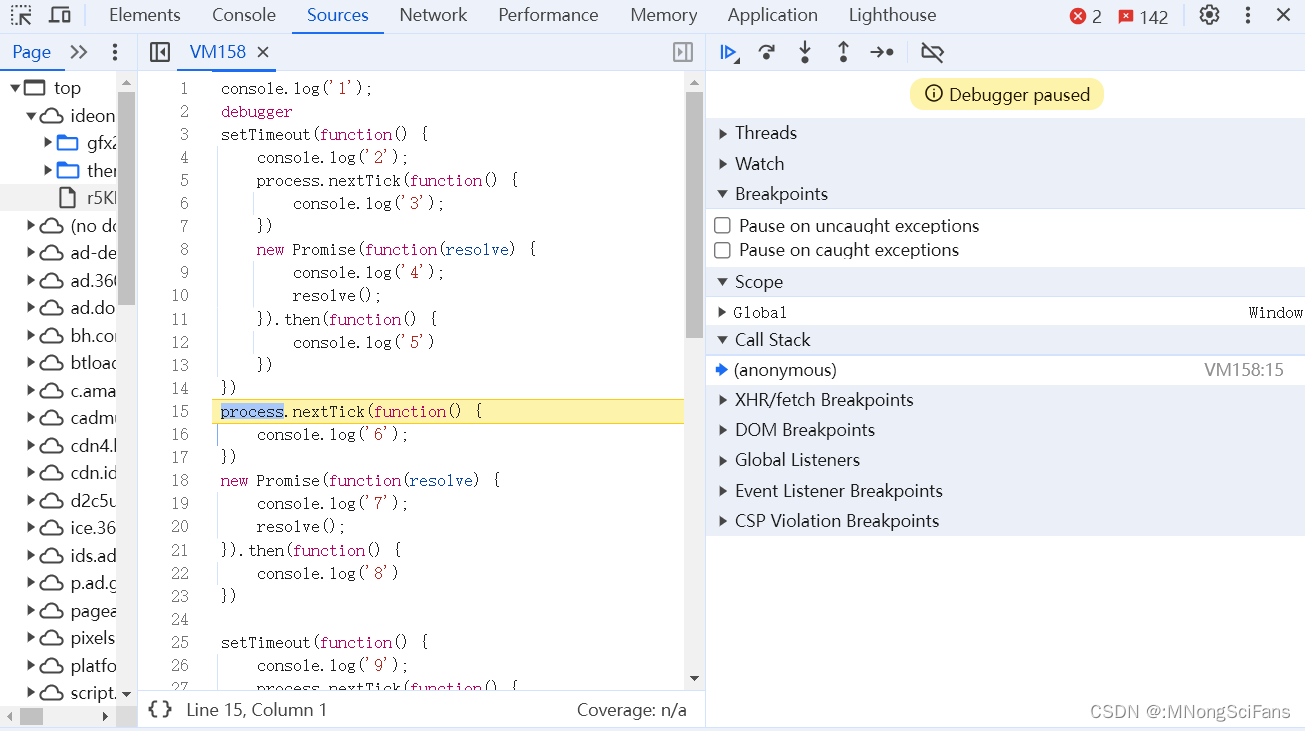
分析一段较复杂的代码,检验看官们掌握的js执行机制:
console.log('1');
setTimeout(function() {
console.log('2');
process.nextTick(function() {
console.log('3');
})
new Promise(function(resolve) {
console.log('4');
resolve();
}).then(function() {
console.log('5')
})
})
process.nextTick(function() {
console.log('6');
})
new Promise(function(resolve) {
console.log('7');
resolve();
}).then(function() {
console.log('8')
})
setTimeout(function() {
console.log('9');
process.nextTick(function() {
console.log('10');
})
new Promise(function(resolve) {
console.log('11');
resolve();
}).then(function() {
console.log('12')
})
})
第一轮事件循环流程分析如下:
- 整体script作为第一个宏任务进入主线程,遇到
console.log,输出1。 - 遇到
setTimeout,其回调函数被分发到宏任务Event Queue中。我们暂且记为setTimeout1。 - 遇到
process.nextTick(),其回调函数被分发到微任务Event Queue中。我们记为process1。 - 遇到
Promise,new Promise直接执行,输出7。then被分发到微任务Event Queue中。我们记为then1。 - 又遇到了
setTimeout,其回调函数被分发到宏任务Event Queue中,我们记为setTimeout2。
| 宏任务Event Queue | 微任务Event Queue |
|---|---|
| setTimeout1 | process1 |
| setTimeout2 | then1 |
-
上表是第一轮事件循环宏任务结束时各Event Queue的情况,此时已经输出了1和7。
-
我们发现了
process1和then1两个微任务。 -
执行
process1,输出6。 -
执行
then1,输出8。
好了,第一轮事件循环正式结束,这一轮的结果是输出1,7,6,8。那么第二轮时间循环从setTimeout1宏任务开始:
- 首先输出2。接下来遇到了
process.nextTick(),同样将其分发到微任务Event Queue中,记为process2。new Promise立即执行输出4,then也分发到微任务Event Queue中,记为then2。
| 宏任务Event Queue | 微任务Event Queue |
|---|---|
| setTimeout2 | process2 |
| then2 |
- 第二轮事件循环宏任务结束,我们发现有
process2和then2两个微任务可以执行。 - 输出3。
- 输出5。
- 第二轮事件循环结束,第二轮输出2,4,3,5。
- 第三轮事件循环开始,此时只剩setTimeout2了,执行。
- 直接输出9。
- 将
process.nextTick()分发到微任务Event Queue中。记为process3。 - 直接执行
new Promise,输出11。 - 将
then分发到微任务Event Queue中,记为then3。
| 宏任务Event Queue | 微任务Event Queue |
|---|---|
| process3 | |
| then3 |
- 第三轮事件循环宏任务执行结束,执行两个微任务
process3和then3。 - 输出10。
- 输出12。
- 第三轮事件循环结束,第三轮输出9,11,10,12。
整段代码,共进行了三次事件循环,完整的输出为1,7,6,8,2,4,3,5,9,11,10,12。
事件循环Event Loop是js实现异步的一种方法,也是js的执行机制。js执行和运行有很大的区别,js在不同的环境下,比如node,浏览器,Ringo等等,执行方式是不同的。而运行大多指js解析引擎,是统一的。微任务和宏任务还有很多种类,比如setImmediate等等,和setInterval、setTimeout执行都是有其共同点的,需要在实践中注意甄别。
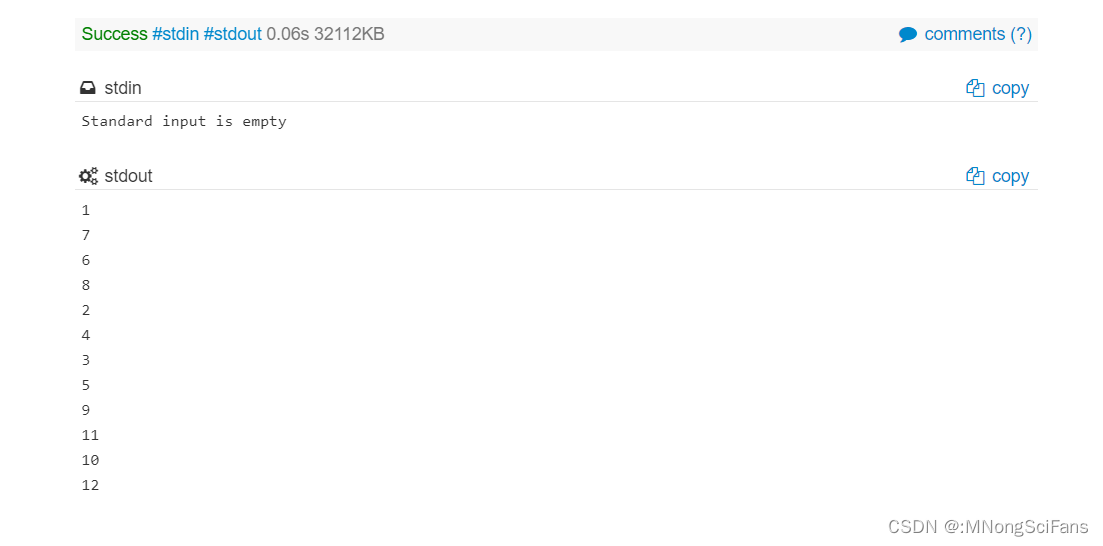
Promise.resolve().then(()=>{console.log(0);return Promise.resolve(4);}).then((res)=>{console.log(res)})
Promise.resolve().then(()=>{console.log(1)}).then(()=>{console.log(2)}).then(()=>{console.log(3)}).then(()=>{console.log(5)}).then(()=>{console.log(6)})
Promise.resolve().then(()=>{console.log(0);return Promise.resolve(5);}).then((res)=>{console.log(res)})
Promise.resolve().then(()=>{console.log(1)}).then(()=>{console.log(2)}).then(()=>{console.log(3)}).then(()=>{console.log(4)}).then(()=>{console.log(6)})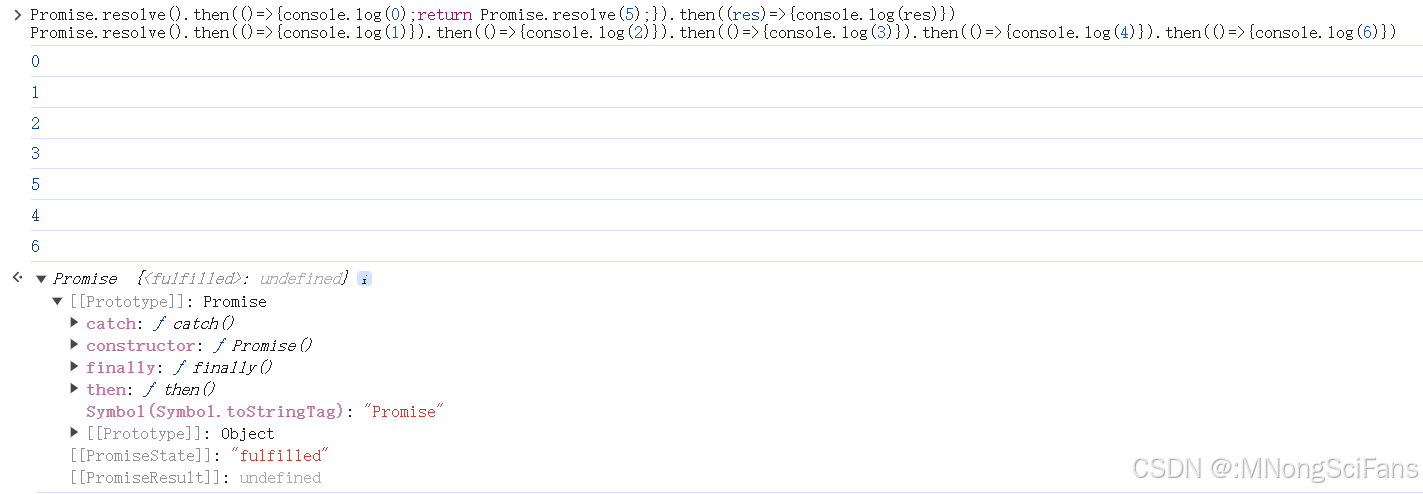
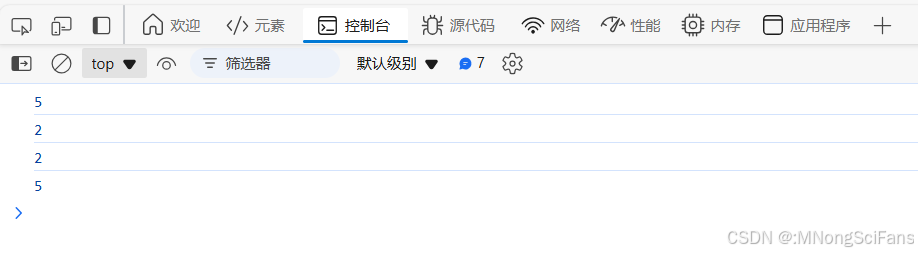
//thenable 在 JavaScript 中, thenable 是一个具有then()功能。 所有的 Promise 都是 //thenable,但并不是所有的 thenable 都是 Promise。许多 Promise 模式,例如:链接
//和async/await,都适用于任何 thenable。
//1、完成,所有注册的thenable进队列
//2、调用then,如果已完成,直接进队列
new Promise((resolve, reject)=>{
resolve(2)
new Promise((resolve, reject)=>{
resolve(5)
}).then(v=>console.log(v))
}).then(v=>console.log(v))
// 5
// 2
new Promise((resolve, reject)=>{
setTimeout(()=>{
resolve(2)
new Promise((resolve, reject)=>{
resolve(5)
}).then(v=>console.log(v))
},0)
}).then(v=>console.log(v))
// 2
// 5
JavaScript是一门单线程语言,不管是什么新框架新语法糖实现的所谓异步,其实都是用同步的方法去模拟的,牢牢把握住单线程,万变不离其宗。
Chromium 软件工程师 Steve Kobes 的一篇名为“Life of a Pixel”的 PPT总结到:浏览器内核将 Web 页面内容转为像素点,这个流程我们通常称之为“渲染”。
渲染流程
解析
HTML 标签将文档赋予了层次结构。例如一个 div 标签中有两个子 P 标签,每个 P 标签中都有自己的文本内容。因此第一步是解析标签,构建反应这个层次结构的对象模型,也就是文档对象模型(Document Object Model - 即 DOM)。
DOM 是树形模型,树中的节点有父亲节点,孩子节点,兄弟节点。DOM 不但是 Blink 内核中的表示页面的内部数据结构,同样其 API 会暴露给 JavaScript,用于 JavaScript 中的查询或修改。JavaScript 引擎(V8)使用一个名为“bindings”的系统,将 DOM 树简单封装后暴露其 DOM web API。
样式表
构建 DOM 树后,下一步是处理 CSS 样式。CSS 选择器将属性声明应用到指定的 DOM 元素上。Web 开发者通过样式属性影响 DOM 元素的呈现效果,现在已有数百种样式属性。不过,确定一个元素应用了哪些样式并非易事,元素可以被多个样式规则命中,而这其中可能会有冲突的样式规则。
CSS 解析器构建样式规则模型,这些样式规则以多种方式排列,以便进行更高效的查询。样式解析从文档中有效样式表中获取全部已解析的样式规则,结合浏览器缺省的规则,最终为每一个 DOM 元素计算出每一条样式属性的值。最终结果会保存在一个名为 ComputedStyle 对象中,该对象是一个庞大的 map,存储样式属性以及对应的值。通过开发者工具你可以看到任意一个 DOM 元素的计算后的样式结果。该结果同样会暴露给 JavaScript,这个机制也是基于 Blink 的 ComputedStyle 对象。
排版
在构建 DOM 树并完成计算全部样式后,接下来的步骤是为所有元素决定其显示位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











