







前言
2024 年诺贝尔物理学奖授予了约翰·霍普菲尔德 (John Hopfield)和图灵奖得主、AI教父杰弗里·辛顿(Geoffrey Hinton),"以表彰他们利用人工神经网络进行机器学习的奠基性发现和发明"。

辛顿在接受电话采访时表示,我没有想到(I have no idea that will happen)。

被誉为“AI教父”的杰佛瑞·埃佛勒斯·辛顿(Geoffrey Everest Hinton,1947-),在70多岁时,成为图灵奖和诺贝尔物理学奖双料得主。
远在1986年,辛顿与David Rumelhart和Ronald Williams共同发表了一篇题为“通过反向传播误差来学习”(Learning representations by back-propagating errors)的论文。
[1]Home Page of Geoffrey Hinton,https://www.cs.toronto.edu/~hinton/
[2]David E. Rumelhart, Geoffrey E. Hinton und Ronald J. Williams. Learning representations by back-propagating errors., Nature (London) 323, S. 533-536,http://www.cs.utoronto.ca/~hinton/absps/naturebp.pdf
三位科学家,并不是第一个提出这种“反向传播”方法的人。但他们将反向传播算法应用于多层神经网络并且证明了这种方法对机器学习行之有效。他们的论文也证明了,神经网络中的多个隐藏层可以学习任何函数,从而解决了闵斯基等书中提出的单层感知机存在的问题。

同一时期,辛顿与 David Ackley 和 Terry Sejnowski 共同发明了玻尔兹曼机。辛顿1986年有关反向传播算法和波尔兹曼机的两篇重要文章,研究者们兴趣盎然,他们凭借自身的信念,排除嘈杂的干扰而自得其乐,江湖貌似平静但暗流涌动,为人工智能春天之到来做好了准备。正是应了一句名言:“大隐隐于市”。

Hinton在1986年提出的通过反向传播来训练深度网络理论,标志着深度学习发展的一大转机,为近年来人工智能的发展奠定了基础。更实际点说,今天谷歌中通过语音识别进行图片检索、在手机上把语音转化为文字的技术的实现,大部分功劳要归于Hinton博士的研究。他的研究,彻底改变了人工智能,乃至整个人类发展的轨迹。


《深度学习的数学》是一本介绍深度学习数学原理的书籍。本书由日本作者涌井良幸和涌井贞美合著,由杨瑞龙翻译成中文。

作者: [日]涌井良幸 / [日]涌井贞美
出版社: 人民邮电出版社 2019
出品方: 图灵教育
原作名: ディープラーニングがわかる数学入門
译者: 杨瑞龙
出版年: 2019-4
页数: 236
定价: 69.00元
装帧: 平装
丛书: 图灵程序设计丛书·程序员的数学
ISBN/ISSN:978-7-115-50934-5
载体形态:225页 :图 ;21cm
中图分类号:TP181
内容简介
《深度学习的数学》基于丰富的图示和具体示例,通俗易懂地介绍了深度学习相关的数学知识。本书主要分为四个部分:线性代数、微积分、概率论和信息论。每一部分都详细介绍了相关的数学知识,并结合深度学习的应用进行讲解。
在线性代数部分,本书讲解了向量、矩阵、线性变换等基本概念,以及它们在深度学习中的应用,如神经网络的表示和运算。
在微积分部分,本书讲解了导数、积分、链式法则等基本概念,以及它们在深度学习中的应用,如优化算法和反向传播算法。
在概率论部分,本书讲解了概率、随机变量、期望等基本概念,以及它们在深度学习中的应用,如概率图模型和贝叶斯推断。
在信息论部分,本书讲解了信息熵、互信息、条件熵等基本概念,以及它们在深度学习中的应用,如信息论视角下的优化和学习。
第1章介绍神经网络的概况;
第2章介绍理解神经网络所需的数学基础知识;
第3章介绍神经网络的最优化;
第4章介绍神经网络和误差反向传播法;
第5章介绍深度学习和卷积神经网络。
书中使用Excel进行理论验证,帮助读者直观地体验深度学习的原理。
作者和译者简介
涌井良幸
1950年生于东京,毕业于东京教育大学(现筑波大学)数学系,现为自由职业者。
著有《用Excel学深度学习》(合著)、《统计学有什么用?》等。
涌井贞美
1952年生于东京,完成东京大学理学系研究科硕士课程,现为自由职业者。
著有《用Excel学深度学习》(合著)、《图解贝叶斯统计入门》等。
译者简介:杨瑞龙
1982年生,2008年北京大学数学科学学院硕士毕业,软件开发者,从事软件行业10年。2013年~2016年赴日工作3年,从2016年开始在哆嗒数学网公众号发表《数学上下三万年》等多篇翻译作品。

目录
第1章 神经网络的思想
1 - 1 神经网络和深度学习 2
1 - 2 神经元工作的数学表示 6
1 - 3 激活函数:将神经元的工作一般化 12
1 - 4 什么是神经网络 18
1 - 5 用恶魔来讲解神经网络的结构 23
1 - 6 将恶魔的工作翻译为神经网络的语言 31
1 - 7 网络自学习的神经网络 36
第2章 神经网络的数学基础
2 - 1 神经网络所需的函数 40
2 - 2 有助于理解神经网络的数列和递推关系式 46
2 - 3 神经网络中经常用到的Σ符号 51
2 - 4 有助于理解神经网络的向量基础 53
2 - 5 有助于理解神经网络的矩阵基础 61
2 - 6 神经网络的导数基础 65
2 - 7 神经网络的偏导数基础 72
2 - 8 误差反向传播法必需的链式法则 76
2 - 9 梯度下降法的基础:多变量函数的近似公式 80
2 - 10 梯度下降法的含义与公式 83
2 - 11 用Excel 体验梯度下降法 91
2 - 12 最优化问题和回归分析 94
第3章 神经网络的最优化
3 - 1 神经网络的参数和变量 102
3 - 2 神经网络的变量的关系式 111
3 - 3 学习数据和正解 114
3 - 4 神经网络的代价函数 119
3 - 5 用Excel体验神经网络 127
第4章 神经网络和误差反向传播法
4 - 1 梯度下降法的回顾 134
4 - 2 神经单元误差 141
4 - 3 神经网络和误差反向传播法 146
4 - 4 用Excel体验神经网络的误差反向传播法 153
第5章 深度学习和卷积神经网络
5 - 1 小恶魔来讲解卷积神经网络的结构 168
5 - 2 将小恶魔的工作翻译为卷积神经网络的语言 174
5 - 3 卷积神经网络的变量关系式 180
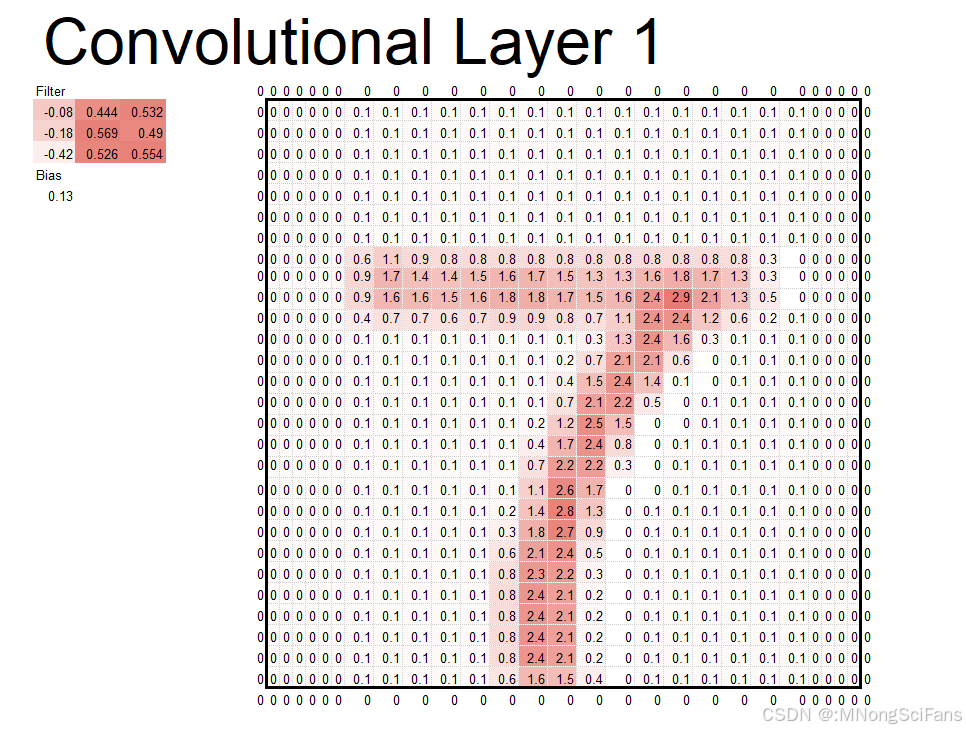
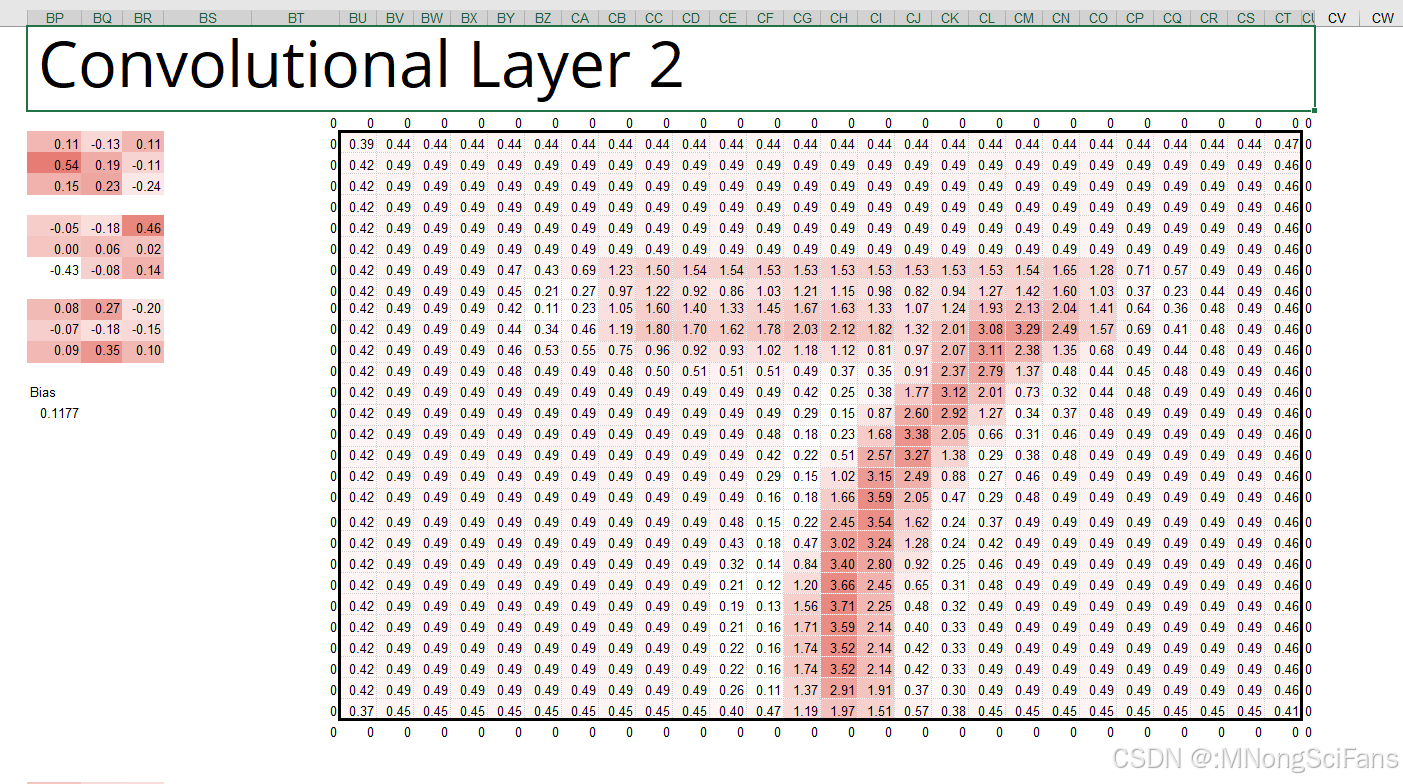
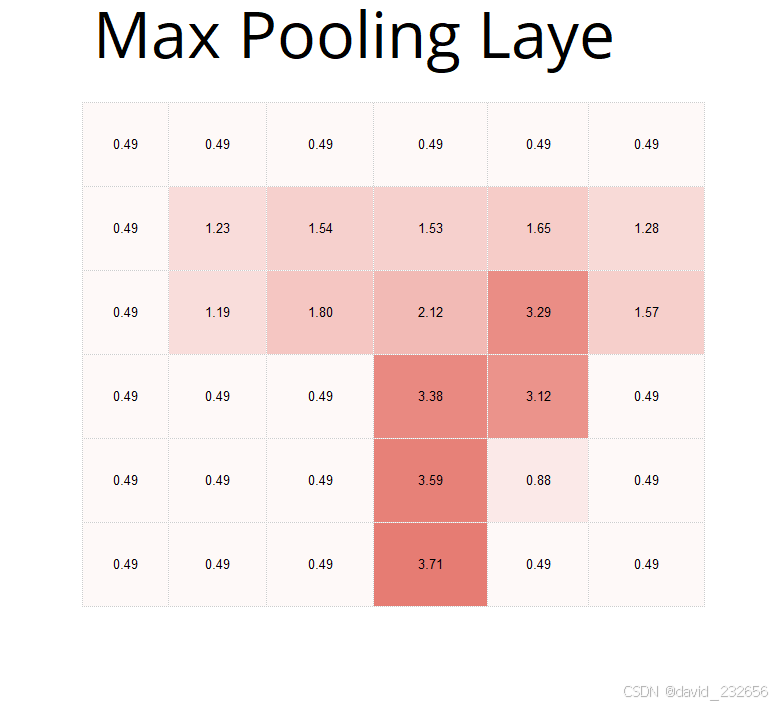
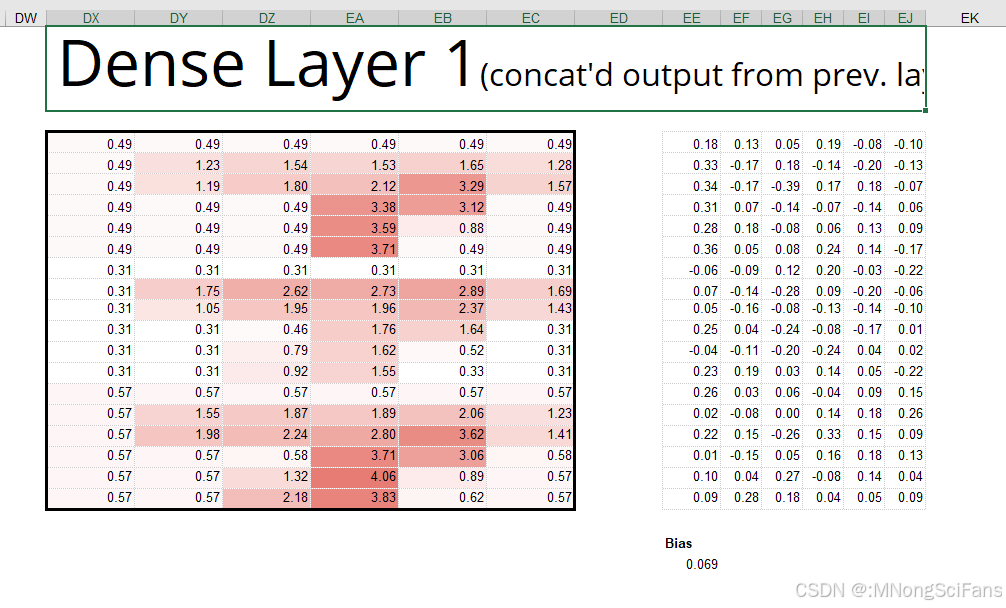
5 - 4 用Excel体验卷积神经网络 193
5 - 5 卷积神经网络和误差反向传播法 200
5 - 6 用Excel体验卷积神经网络的误差反向传播法 212



附录
A 训练数据(1) 222
B 训练数据(2) 223
C 用数学式表示模式的相似度 225
小试牛刀
使用清华镜像开源获取anaconda安装软件
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2024.06-1-Windows-x86_64.exe
安装成功后,打开Prompt,配置环境

因为TensorFlow可能需要使用某些特定版本的库,而这些库与您的系统上的其他应用程序可能存在冲突,使用虚拟环境可以隔离TensorFlow和其他应用程序之间的库,从而避免冲突,所以先为TensorFlow创建一个虚拟环境。

在Anaconda Prompt终端中,运行以下命令以创建名为“py39tf210_env”的虚拟环境:
conda create --name py39tf210_env
激活虚拟环境
在创建虚拟环境之后,您需要激活该虚拟环境。在Anaconda Prompt终端中,运行以下命令:
conda activate py39tf210_env
查看当前已有环境,激活的环境
conda env list
安装TensorFlow,打开anaconda prompt,然后输入在里面输入以下命令:
conda install pip
更新
python -m pip install --upgrade pip
nvidia显卡驱动下载
https://www.nvidia.cn/content/DriverDownloads/confirmation.php?url=/Windows/460.89/460.89-desktop-win10-64bit-international-dch-whql.exe&lang=cn&type=GeForce

cuda下载
https://developer.nvidia.com/cuda-toolkit
https://developer.nvidia.com/cuda-11.2.0-download-archive

cudnn下载
https://developer.nvidia.com/rdp/cudnn-archive

下载的cudnn文件夹,将bin、include、lib合并到CUDA对应版本文件夹


在文件夹NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\demo_suite CMD命令窗口,检查CUDA安装是否成功
执行bandwidthTest.exe

Microsoft Windows [版本 10.0.19045.5011]
(c) Microsoft Corporation。保留所有权利。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\demo_suite>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA GeForce GTX 1660 Ti
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 6315.2
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 6322.3
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 249160.5
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
执行deviceQuery.exe
Microsoft Windows [版本 10.0.19045.5011]
(c) Microsoft Corporation。保留所有权利。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\demo_suite>deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce GTX 1660 Ti"
CUDA Driver Version / Runtime Version 12.0 / 11.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 6144 MBytes (6442123264 bytes)
(24) Multiprocessors, ( 64) CUDA Cores/MP: 1536 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.0, CUDA Runtime Version = 11.2, NumDevs = 1, Device0 = NVIDIA GeForce GTX 1660 Ti
Result = PASS
NVIDIA的nvidia-smi(系统管理接口,监控GPU状态)提供GPU实时性能数据和管理功能
NVIDIA的nvcc-V(CUDA编译器版本信息获取工具)主要用于检查编译器兼容
在CMD窗口使用指令nvidia-smi 查看
Microsoft Windows [版本 10.0.19045.5011]
(c) Microsoft Corporation。保留所有权利。
C:\Users\admin>nvidia-smi
Fri Oct 11 15:19:13 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 528.79 Driver Version: 528.79 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... WDDM | 00000000:01:00.0 Off | N/A |
| N/A 59C P0 24W / 80W | 0MiB / 6144MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
在CMD窗口使用指令nvcc -V 查看
Microsoft Windows [版本 10.0.19045.5011]
(c) Microsoft Corporation。保留所有权利。
C:\Users\admin>nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Mon_Nov_30_19:15:10_Pacific_Standard_Time_2020
Cuda compilation tools, release 11.2, V11.2.67
Build cuda_11.2.r11.2/compiler.29373293_0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==2.10.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow-gpu==2.10.1
注意:本机 Windows 上的 GPU 支持仅适用于 2.10 或更早版本,从 TF 2.11 开始,Windows 不支持 CUDA 构建。要在 Windows 上使用 TensorFlow GPU,您需要在 WSL2 中构建/安装 TensorFlow 或将 tensorflow-cpu 与 TensorFlow-DirectML-Plugin 一起使用。
CPU版本和GPU版本的区别主要在于运行速度,GPU版本运行速度更快,所以如果电脑显卡支持cuda,推荐安装gpu版本的。CPU版本,无需额外准备,CPU版本一般电脑都可以安装,无需额外准备显卡的内容。GPU版本,需要提前下载 cuda 和 cuDNN。
安装前 一定 要查看自己电脑的环境配置,然后查询
Tensorflow-gpu、Python、cuda、cuDNN版本关系,要 一 一对应。

tensorflow版本从2.x开始不再区分CPU版和GPU版,因此在软件配置正确的情况下,是可以找到GPU设备的。Tensorflow 2.10是最后一个在本地windows上支持GPU的版本。从2.11版本开始,需要在windows WLS2(适用于 Linux 的 Windows 子系统)上安装才能使用GPU。所以要在native-windows上使用GPU,就只能安装2.10.0版本及以下的版本,或者安装老版的tensorflow-gpu。
tensorflow gpu cuda cudnn对应表格
https://tensorflow.google.cn/install/source_windows?hl=en#gpu
tensorflow:支持 CPU 和 GPU 的最新稳定版(适用于 Ubuntu 和 Windows)
tf-nightly:预览 build(不稳定)。Ubuntu 和 Windows 均包含 GPU 支持。
旧版 TensorFlow
对于 TensorFlow 1.x,CPU 和 GPU 软件包是分开的:tensorflow==1.15:仅支持 CPU 的版本
tensorflow-gpu==1.15:支持 GPU 的版本(适用于 Ubuntu 和 Windows)
系统要求
Python 3.6–3.9
若要支持 Python 3.9,需要使用 TensorFlow 2.5 或更高版本。
若要支持 Python 3.8,需要使用 TensorFlow 2.2 或更高版本。
pip 19.0 或更高版本(需要 manylinux2010 支持)
Ubuntu 16.04 或更高版本(64 位)
macOS 10.12.6 (Sierra) 或更高版本(64 位)(不支持 GPU)
macOS 要求使用 pip 20.3 或更高版本
Windows 7 或更高版本(64 位)
适用于 Visual Studio 2015、2017 和 2019 的 Microsoft Visual C++ 可再发行软件包
GPU 支持需要使用支持 CUDA® 的卡(适用于 Ubuntu 和 Windows)
注意:必须使用最新版本的 pip,才能安装 TensorFlow 2。
硬件要求
从 TensorFlow 1.6 开始,二进制文件使用 AVX 指令,这些指令可能无法在旧版 CPU 上运行。
安装numpy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==1.20.3安装pytorch
Commands for Versions >= 1.0.0
v2.4.0
Conda
OSX
# conda
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 -c pytorch
Linux and Windows
# CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
# CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 cpuonly -c pytorch
(base) C:\Users\>conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): done
Solving environment: -
The environment is inconsistent, please check the package plan carefully
The following packages are causing the inconsistency:
- defaults/win-64::anaconda==2021.11=py39_0
- defaults/win-64::astropy==4.3.1=py39hc7d831d_0
- defaults/win-64::bkcharts==0.2=py39haa95532_0测试配置
import tensorflow as tf
from tensorflow.keras import layers, models
import torch
import os
#将TF_ENABLE_ONEDNN_OPTS设置成1或以上。0代表显示所有信息,1表示不显示info,2表示不显示warning,3表示不显示error。
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
print('TensorFlow版本',tf.__version__)
# 查看torch当前版本号
print('torch当前版本号',torch.__version__)
# 编译当前版本的torch使用的cuda版本号
print('torch使用的cuda版本号',torch.version.cuda)
# 查看当前cuda是否有可用的Torch,如果输出True,则表示存在/成功安装
print('当前cuda是否有可用的Torch',torch.cuda.is_available())
# 获取TensorFlow的构建信息
build = tf.sysconfig.get_build_info()
# 打印CUDA的版本号(如果已安装)
print(build['cuda_version'])
# 打印cuDNN的版本号(如果已安装)
print(build['cudnn_version'])
print('GPU:是否已经编译了CUDA支持', tf.test.is_built_with_cuda())
print('GPU:当前GPU设备名称', tf.test.gpu_device_name())
# 输出可用的GPU数量
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
print("Num CPUs Available: ", len(tf.config.list_physical_devices('CPU')))
#默认情况下,TensorFlow 会映射进程可见的所有 GPU(取决于 CUDA_VISIBLE_DEVICES)的几乎全部内存。
#这是为了减少内存碎片,更有效地利用设备上相对宝贵的 GPU 内存资源
gpus = tf.config.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only allocate 1GB of memory on the first GPU
try:
tf.config.set_logical_device_configuration(
gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024*6)])
logical_gpus = tf.config.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Virtual devices must be set before GPUs have been initialized
print(e)
import timeit
#指定在cpu上运行
def cpu_run():
with tf.device('/cpu:0'):
cpu_a = tf.random.normal([10000, 1000])
cpu_b = tf.random.normal([1000, 2000])
c = tf.matmul(cpu_a, cpu_b)
return c
#指定在gpu上运行
def gpu_run():
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([10000, 1000])
gpu_b = tf.random.normal([1000, 2000])
c = tf.matmul(gpu_a, gpu_b)
return c
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print("cpu:", cpu_time, " gpu:", gpu_time)

主程序

输出概率
Softmax
线性层
加法和归一化
前馈网络
残差连接与层归一化
加权和归一化
多头注意力
编码器自注意力:标记互相看
查询、键、值由编码器的状态计算得出
位置编码
输入嵌入
输入
前馈网络:在获取其他标记的信息后,花点时间思考和加工这些信息
编码器自注意力:目标标记查看源查询——来自解码器的状态;键和值来自编码器的状态
解码器自注意力(掩蔽):标记查看前面的标记
查询、键、值由解码器的状态计算得出
位置编码
输出嵌入
输出(右移)

Torch和TensorFlow是两个流行的深度学习框架,都可以用于构建和训练神经网络模型。它们都提供了强大的计算图和自动求导功能,以及一系列工具和库来简化深度学习模型的开发和训练过程。Torch的计算图是动态的,这意味着可以在运行时进行修改和调整。而TensorFlow的计算图是静态的,需要在构建之后才能执行。这使得Torch更适合于动态的计算流程和实验性的研究,而TensorFlow更适合于大规模的生产环境和优化计算性能。Torch在早期得到了广泛的应用和支持,而TensorFlow则在谷歌的大力推动下逐渐成为了业界的主流深度学习框架之一。这也导致了它们在生态系统和社区支持方面的差异。
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
y=sin(x) 神经网络的设计与训练
"""
import torch
from torch import nn
from matplotlib import pyplot as plt
import numpy as np
#神经网络类 network,继承nn.Module类
class Network(nn.Module):
#类的初始化函数
#init函数传入1个参数m,m代表了隐藏层神经元的数量
def __init__(self,m):
super().__init__()
#layer1 是输入层与隐藏层之间的线性层,大小是1*m
self.layer1 = nn.Linear(1,m)
#layer2 是隐藏层与输出层之间的线性层,大小是m*1
self.layer2 = nn.Linear(m,1)
#前向传播计算函数,函数传入输入数据x
def forward(self,x):
x = self.layer1(x) #先进入layer1层,计算结果
x = torch.sigmoid(x) #使用sigmoid激活函数
return self.layer2(x) #返回layer2层的计算结果
# 在main函数中实现模型的测试代码
if __name__ == '__main__':
'''
model = Network(6) #创建模型,隐藏层个数传入6
print(model) #打印model,可以看到模型的结果
#接着使用循环,遍历模型中的参数
for name,param in model.named_parameters():
#打印参数名name和参数的尺寸param.data.shape
print(f"{name}:{param.data.shape}")
#定义一个100*1大小的张量
#代表了100个输入数据,每个数据包括1个特征值,也就是sin(x)中的x
x = torch.zeros([100,1])
h = model(x) #将x输入至模型model,得到预测结果h,h即为sin(x)
print(f"x:{x.shape}")
print(f"h:{h.shape}")
'''
#神经网络模拟正弦函数,是一个回归任务
#训练使用的数据,可以直接使用正弦函数进行构造
#数据的生成代码
#使用np.arrange 生成一个从0到1,步长为0.01
# 含有100个数据点的数组,作为正弦函数的输入数据
x = np.arange(0.0, 1.0, 0.01)
# 将0到1的x,乘以2倍PI,从单位间隔转换为弧度值
# 将x映射到正弦函数的一个完整周期上,并计算正弦值
y = np.sin(2*np.pi*x)
# 将x和y通过reshape函数转为100乘以1的数组
# 也就是100个(x,y)坐标,代表100个训练数据
x = x.reshape(100,1)
y = y.reshape(100,1)
#将(x,y)组成的数据点,画在画板上
plt.scatter(x,y)
x = torch.Tensor(x) # 训练前将数据x和y转化为tensor张量
y = torch.Tensor(y)
model = Network(3) # 定义神经网络
# 隐藏层的神经元数量,可以尝试6 、 10 、 32 等数据,观察实验结果
criterion = nn.MSELoss() # 创建均方误差损失函数
# Adam优化器optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 完成这些必要的变量声明后,就可以进入神经网络的循环迭代
#神经网络训练代码
# 使用批量梯度下降算法
# 每次迭代,都会基于全部样本计算损失值,执行梯度下降
# 循环的轮数定为1万,就可以使模型达到收敛
for epoch in range(1000):
# 在循环中,包括了5个步骤:
h = model(x) #1.计算模型的预测值h
loss=criterion(h,y) #2.计算预测h和标签y之间的损失loss
loss.backward() #3.使用backward计算梯度
optimizer.step() #4.使用optimizer.step更新参数
optimizer.zero_grad() #5.将梯度清零
#这5个步骤,是使用pytorch框架训练模型的定式
#每迭代1000次,就打印一次模型的损失,用于观察训练的过程
if epoch % 1000 == 0:
#其中loss.item是损失的标量值
print(f"After { epoch } iterations, the loss is {loss.item()}")
h = model(x) # 完成训练后,使用模型预测输入x,得到预测结果h
x = x.data.numpy()
h = h.data.numpy()
plt.scatter(x,h) # 将预测点(x,h)打印在屏幕
plt.show()


# -*- coding: utf-8 -*-
"""
Created on Tue Oct 15 17:57:10 2024
"""
import tensorflow as tf
print(tf.__file__)
#https://github.com/tensorflow/tensorflow
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
print ( ' 输入数据:', mnist.train.images)
print ( ' 输入数据打shape :', mnist.train.images.shape)
import pylab
im = mnist.train.images[1]
im = im.reshape(-1 ,28)
pylab.imshow(im)
pylab.show()
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 15 17:51:23 2024
"""
#coding: utf-8
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from PIL import Image
'''
函数功能:按照bmp格式提取mnist数据集中的图片
参数介绍:
mnist_dir mnist数据集存储的路径
save_dir 提取结果存储的目录
'''
def extract_mnist(mnist_dir, save_dir):
rows = 28
cols = 28
# 加载mnist数据集
# one_hot = True为默认打开"独热编码"
mnist = input_data.read_data_sets(mnist_dir, one_hot=False)
# 获取训练图片数量
shape = mnist.train.images.shape
images_train_count = shape[0]
pixels_count_per_image = shape[1]
# 获取训练标签数量=训练图片数量
# 关闭"独热编码"后,labels的类型为[7 3 4 ... 5 6 8]
labels = mnist.train.labels
labels_train_count = labels.shape[0]
if (images_train_count == labels_train_count):
print("训练集共包含%d张图片,%d个标签" % (images_train_count, labels_train_count))
print("每张图片包含%d个像素" % (pixels_count_per_image))
print("数据类型为", mnist.train.images.dtype)
# mnist图像数值的范围为[0,1], 需将其转换为[0,255]
for current_image_id in range(images_train_count):
for i in range(pixels_count_per_image):
if mnist.train.images[current_image_id][i] != 0:
mnist.train.images[current_image_id][i] = 255
if ((current_image_id + 1) % 50) == 0:
print("已转换%d张,共需转换%d张" %
(current_image_id + 1, images_train_count))
# 创建train images的保存目录, 按标签保存
for i in range(10):
dir = "%s/%s" % (save_dir, i)
print(dir)
if not os.path.exists(dir):
os.mkdir(dir)
# indices = [0, 0, 0, ..., 0]用来记录每个标签对应的图片数量
indices = [0 for x in range(0, 10)]
for i in range(images_train_count):
new_image = Image.new("L", (cols, rows))
# 遍历new_image 进行赋值
for r in range(rows):
for c in range(cols):
new_image.putpixel(
(r, c), int(mnist.train.images[i][c + r * cols]))
# 获取第i张训练图片对应的标签
label = labels[i]
image_save_path = "%s/%s/%s.bmp" % (save_dir, label,
indices[label])
indices[label] += 1
new_image.save(image_save_path)
# 打印保存进度
if ((i + 1) % 50) == 0:
print("图片保存进度: 已保存%d张,共需保存%d张" % (i + 1, images_train_count))
else:
print("图片数量与标签数量不一致!")
if __name__ == '__main__':
mnist_dir = "./mnist_Data"
save_dir = "./mnist_Data_TrainImages"
extract_mnist(mnist_dir, save_dir)
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 15 15:30:10 2024
设计、实现标准前馈神经网络
输入层 隐藏层 输出层 sofrmax p0+p1+...+pn=1
神经网络的设计和实现
训练数据的准备和处理
模型的训练和测试流程
MNIST是一个手写体数字的图片数据集,该数据集来由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。
该数据集的收集目的是希望通过算法,实现对手写数字的识别。
1998年,Yan LeCun 等人发表了论文《Gradient-Based Learning Applied to Document Recognition》,
首次提出了LeNet-5 网络,利用上述数据集实现了手写字体的识别。
https://yann.lecun.com/exdb/mnist/
在PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它识别手写数字。 MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。
图像是灰度(即通道数为1),28x28像素,并且居中的,以减少预处理和加快运行。
PyTorch是一个非常流行的深度学习框架。但是与其他框架不同的是,PyTorch具有动态执行图,意味着计算图是动态创建的。
"""
import torch
from torch import nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
# 定义神经网络Network
class Network(nn.Module):
def __init__(self):
super().__init__()
# 线性层1,输入层和隐藏层之间的线性层
self.layer1 = nn.Linear(784,256)
# 线性层2,隐藏层和输出层之间的线性层
self.layer2 = nn.Linear(256,10)
# 在前向传播,forward函数中,输入为图像x
def forward(self,x):
x = x.view(-1, 28*28) #使用 view函数,将x展平
x = self.layer1(x) # 将x输入至layer1
x = torch.relu(x) # 使用relu激活
return self.layer2(x) # 输入至layer2计算结果
# 这里我们没有直接定义softmax层
# 这是因为后面会使用CrossRntropyLoss损失函数
# 在这个损失函数中,会实现softmax的计算
#训练数据的准备和处理
#MNIST数据集,可以从torchvision.datasets中获取
#TFDS 存在于两个软件包中:
#pip install tensorflow-datasets:稳定版,数月发行一次。
#pip install tfds-nightly:每天发行,包含最近版本的数据集。
#https://tensorflow.google.cn/datasets/overview?hl=zh-cn
#https://tensorflow.google.cn/datasets/catalog/overview
#train_dataset = datasets.MNIST(root='./MNIST',train=True,transform=data_tf,download=True)
#train 60000个数据,用作训练
#tesst 10000个数据,用作测试
#一共4个文件,训练集、训练集标签、测试集、测试集标签
#文件名称 大小 内容
#train-labels-idx1-ubyte.gz 9,681 kb 55000张训练集,5000张验证集
#train-labels-idx1-ubyte.gz 29 kb 训练集图片对应的标签
#t10k-images-idx3-ubyte.gz 1,611 kb 10000张测试集
#t10k-labels-idx1-ubyte.gz 5 kb 测试集图片对应的标签
#如果直接下载该数据集的话,下载下来的是.gz格式的数据
#手动提取Mnist数据集中的图片,并把它按照常用的格式存储 在代码中用到了两个第三方的包,分别为tensorflow、PIL
#conda install tensorflow-gpu
#conda install Pillow
#https://github.com/tensorflow/tensorflow 压缩包解压,把里面的tensorflow下的examples文件夹直接复制过来
# 数据处理流程
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(torch.cuda.device_count(),torch.cuda.get_device_name(0),torch.cuda.current_device())
#optimizer加载参数时,tensor默认在CPU上,当你使用GPU训练时就会报以上错误。
# 实现图像的预处理pipeline
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), #转换为单通道灰度图
transforms.ToTensor() # 转换为张量
])
# 使用ImageFolder函数,读取数据文件夹,构建数据集dataset
# 这个函数会将保存数据的文件夹的名字,作为数据的标签,组织数据
# 例如:对于名字为“3”的文件夹
# 会将“3”作为文件夹中图像数据的标签,和图像匹配,用于后续的训练,使用起来非常的方便
train_dataset = datasets.ImageFolder(root="./mint_image/train", transform=transform)
#读取测试数据集
test_dataset = datasets.ImageFolder(root="./mint_image/test", transform=transform)
# 打印他们的长度
print("train_dataset length:", len(train_dataset))
print("test_dataset length:", len(test_dataset))
#使用train_loader,实现小批量的数据读取
#这里设置小批量的大小,batch_size=64,也就是每个批次,包括64个数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
#打印train_loader的长度
print("train_loader length:", len(train_loader))
#60000个训练数据,如果每个小批量,读入64个样本,那么60000个数据会被分割成938组数据
#计算938*64=60032,这说明最后一个组,会不够64个数据
# 循环遍历train_loader
# 每一次循环,都会取出64个图像数据,作为一个小批量batch
for batch_idx, (data, label) in enumerate(train_loader):
if batch_idx == 2: #打印前2个batch观察
break
print("batch_idx:",batch_idx)
print("data.shape:", data.shape) # 数据尺寸 torch.Size([64, 1, 28, 28]) 每组数据包括64个图像,每个图像有1个灰色通道,图像的尺寸是28*28
print("label:", label.shape) #图像中的数字
print(label)
#模型的训练和测试
#在使用pytorch训练模型时,需要创建三个对象
model = Network() #1. 模型本身,它就是我们设计的神经网络
#整个模型的参数、缓存、依赖的模块 放入device
model.to(device)
optimizer = optim.Adam(model.parameters()) #2. 优化器,优化模型中的参数
criterion = nn.CrossEntropyLoss() #3. 损失函数,分类问题,使用交叉熵损失误差
#进入模型的循环迭代
for epoch in range(10): #外层循环,代表整个训练数据集的遍历次数
#整个训练集要循环多少轮,是10次、20次或者100次都是可能的
#内循环使用train_loader,进行小批量的数据读取
for batch_idx, (inputs, target) in enumerate(train_loader):
#内层每循环一次,就会进行一次梯度下降算法
#包括5个步骤:
#inputs, target = data
inputs, target = inputs.to(device), target.to(device)
# forward + backward + update
outputs = model(inputs) #1.计算神经网络的前向传播结果
loss = criterion(outputs, target) #2. 计算output和标签label之间的损失loss
loss.backward() #3. 使用backward计算梯 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2795
2795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











