







一 什么是KNN
KNN是最常见的机器学习的方法。KNN就是k个最近的邻居的意思,也就是说每个样本都可以用最近的k个邻居来代表。用句老话说就是“近朱者赤,近墨者黑”。
KNN可以用于分类,也可以用于回归。用于分类时,使用少数服从多数的原则;用于回归时,则采用平均的方法。
二 KNN的距离计算方法
计算两个样本间的距离方法,最常见的是欧式距离/直线距离,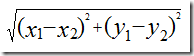
或者是曼哈顿距离/街区距离。![]()
当然还有余弦距离等。
三 KNN中近邻的查找算法
近邻查找算法是找到某个样本的最近的K个邻居时使用的算法。sklearn支持暴力求解、K-D Tree和ball Tree的方法。这个算法的选取直接影响到KNN的耗时。
蛮力破解是最简单的算法,只要计算预测样本与训练集中全部样本的距离,然后得到最小的K的样本,根据投票原则,得到结果。这个算法在实际场景中,如果样本特征比较多,样本集也比较大时,得到结果需要大量运算,耗时太长。
KD tree算法。注意这里的KD是K维的意思,不是NBA的KD,:-D。另外这里的K指K维,KDD里的K指的是K个近邻,两个K不一样。kd tree实际上是一个平衡二叉树,首先先构建一颗树,然后在预测时只要搜索这棵树,最后投票。这篇博客里介绍了详细的KD树,大家可以移步去看。https://blog.csdn.net/miscclp/article/details/8568665

KD树有个缺点,就如上图所示,KD树在搜索近邻时,如果圆圈把一个矩形只圈进来一个小角,这时这个矩形也需要被加进来计算,其实这个矩形基本上是没用的。球树最大的改进是分隔时,不使用KD-Tree的矩形,而是使用球型。:-D,这也是Ball Tree名字的由来。其他的类似KD树。
题外话,上面提到的算法不仅仅是KNN中使用,其他的需要计算距离的地方,如K均值,DBScan等一样通用。
四 KNN的优缺点
KNN方法在构建阶段非常迅速,因为不需要学习什么。但在做分类或者回归时,如果特征非常多,数据集非常大,这个阶段会非常耗时。
K值小时,容易发生过拟合,估计误差变大;K值大时,则相反。但K值取多大,并没有通用的经验值,:-( 一般先取一个小值,然后再经过测试调整。
KD树,球树因为需要建立一棵二叉树,这棵树需要存储全部的训练样本(每个样本有成百上千的特征),对内存的要求还是挺大的。
KNN还有一个缺点,如果样本类别不均衡,对稀有类别的预测不好。















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









