







如何将视频转换成视频帧(视频图像序列)+ 如何制作自己的视频跟踪数据集
这次想在网上备注的知识是如何将视频转换成视频序列(即一帧一帧的图像)。有的时候大家或许希望从视频中得到其中的某一幅或者某几幅图像序列,而不是整个视频。在科研中,许多学者也希望将视频转化成视频序列以方便进行进一步的处理和研究。 目前其实有很多能够实现这一功能的软件,但经过多次尝试,本人还是比较喜欢绘声绘影这款软件,它是一个强大的视频处理软件。这里我将介绍使用绘声绘影软件+matlab来实现将视频转换成视频帧的方法。
首先,我们要装好相应的软件绘声绘影和matlab。这里我就默认大家已经装好了。
视频转换成视频帧
在这里我们首先将视频在绘声绘影中打开,然后按照以下步骤操作。
1. 点击share--》custom(下图是一个总体的步骤图)。
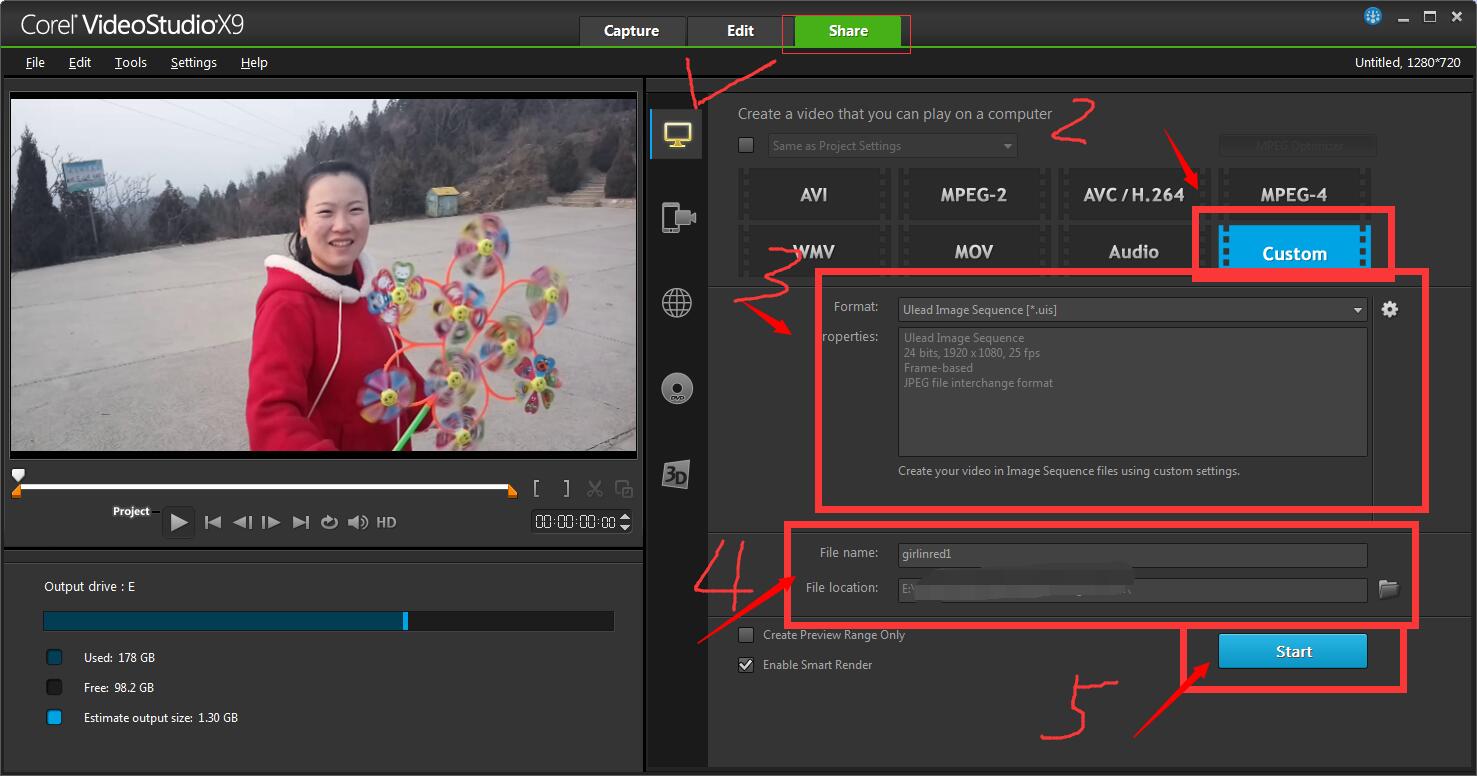
2. 在上图数字3处,选择Ulead ImagesSequence[*, uis],并点击旁边的设置按钮(齿轮)
3. 出现如下所示的两个图,并按照自己的需求对参数进行设置。特别需要注意的是一定要合理的设置这些参数。
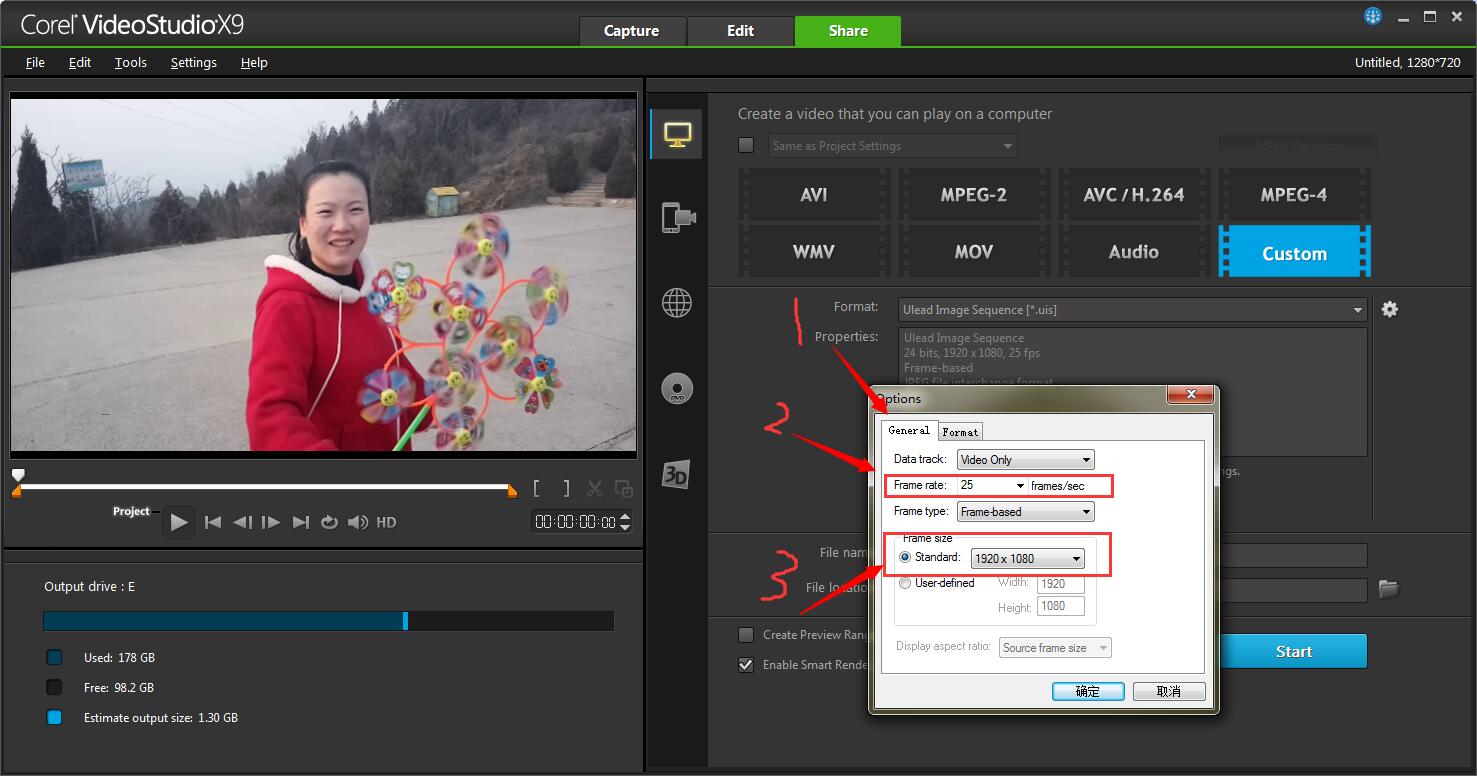
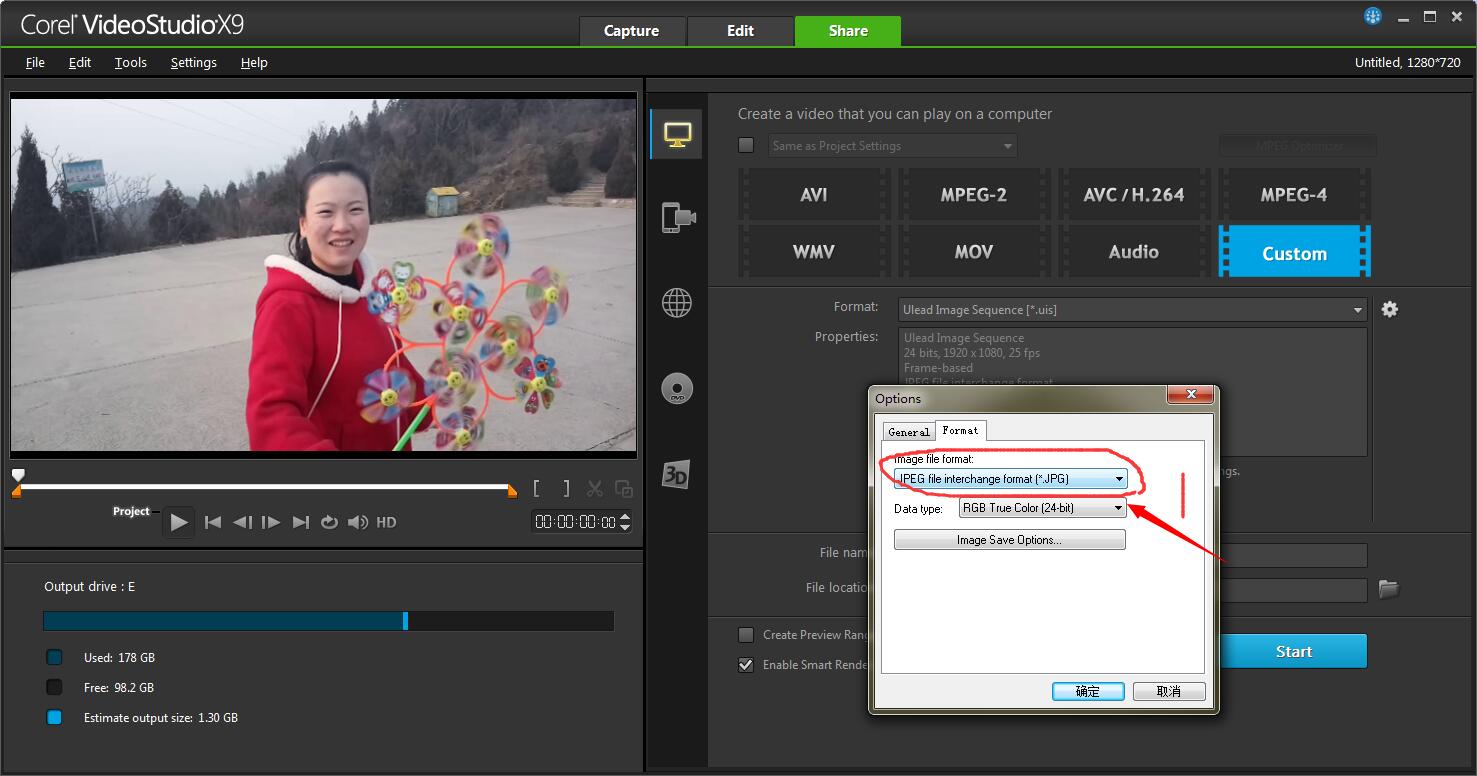
4. 上面左图,在General选项下,我们可以选择每秒要截取的帧数,也可以设置所要生成的视频序列的分辨率,(这一点比较重要,默认的图像序列的分辨率是很低的)。在右图中,我们可以设置想要转化的视频序列的格式,这里我选的是jpeg的格式(默认是BMP的格式)。
5. 然后就按照最上面图的‘4’对图像序列进行命名并设置一个保存的位置。
6. 最后点击start就可以自动的生成jpeg的视频图像序列了。结果如下图所示:

批量重命名视频帧
在完成图像序列的生成之后我们就可以看到一帧一帧的视频图像序列了,这组图像序列的命名是有着一定的规律的,但是有时候我们还是需要对这个视频数据集进行重命名,以符合某些数据集的图像序列的命名标准。比如将上例中的视频序列都命名成‘0001.jpg,0002.jpg,......’等形式。
这里我使用matlab写了一个批量命名文件的脚本,此脚本可以在 http://download.csdn.net/download/davidsmith8/10266199
下载到。 当你下载了这个脚本后,你只需要将其解压,并将上面两个.m文件保存到视频序列文件夹下,最后使用matlab运行这个脚本,就能自动的为上面的视频序列进行重命名了。其结果如下图所示:
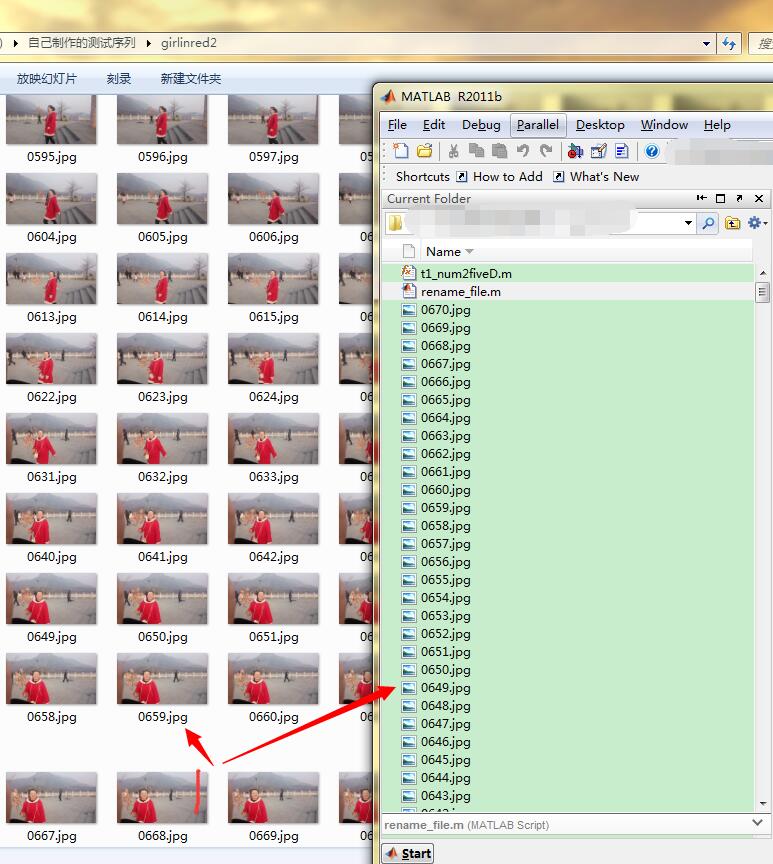
到这里!我们就成功的完成了视频转换成视频帧,并实现了批量重命名的过程。这篇博客一是为了自己的备忘,二是,也希望大家能够有所收获!















 4152
4152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









