







逻辑回归学习总结(或对数回归)
算法描述
-
输入训练集
- 训练集:={(x_i,y_i )}, 样本个数为m, X∈R^n,Y∈{0,1},即X一共有n个属性,Y的值只有0或1,代表是分类“0”标签,还是分类“1”标签 输出
-
训练出参数向量θ ⃗,使输出预测构造函数
,对于给定数据集x代入h_θ(x),就可以得出分类预测构造函数
推导过程
求概率表达式并使样本归类最大化
g(z)函数是sigmod函数,这是一个平滑并且可导数据,函数值范围在(0,1),当x>0时y∋(0.5,1),x<0时,y∋(0,0.5)
对g(z)进行求导,可以发现很好的一个结果,后面推导会用到:
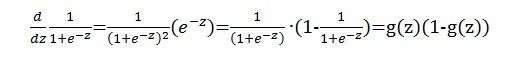
对输入x,h_θ(x)结果为1分类的条件概率,1-h_θ(x)为结果取0分类的概率的条件概率,参数为θ
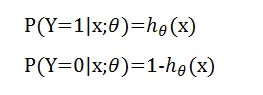
将两式合写在一起即:
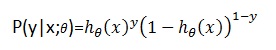
构造似然函数
目前是一共有m个训练样本的,构造似然函数
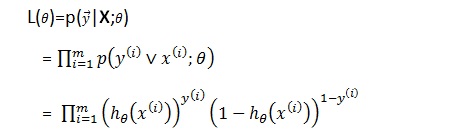
取对数:
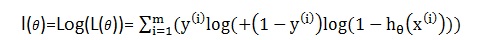
为了求该函数的最大化,可以用梯度向上法求最值,首先求θ的偏导数,先拿一条训练数据示例:
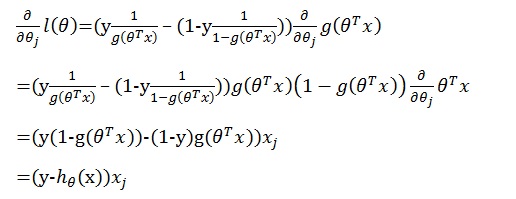
注: j是x的第j个属性,即第j个分量
梯度求解
为了求该式的最大值,也就是说将样本中各个X的值代到分类函数中得到的结果即标签值(1,或2)与样本中对应的y值的概率最大化,这里运用梯度上升算法,即延着方程的梯度方向通过迭代多次,每次步长为a寻找局部最大值,梯度是一个向量,决定走的方向,按此方向走可以达到局部最大值或最小值的速度最快,用偏导数对各个θj分别求偏导,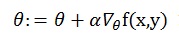
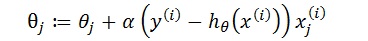
注意:这里的i表示的是样本编号,i∈(0,m], j是X的属性编号,假设有N个属性,则 j∈(0,N],x^((i) ) 代表第i个样本值,x_j^((i) )代表第i个样本,第j个属性,如果把X看成是一个矩阵用下标表示,应该是X_ij
化为矩阵描述
为方便运算,用矩阵表示将更清晰:
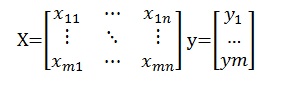
令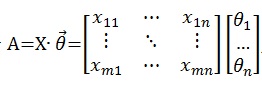
令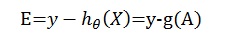
展开如下:
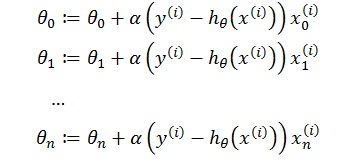
考虑i的范围为0<=i<=m,所以写成矩阵形式:
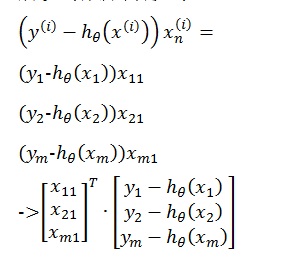
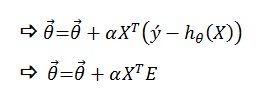
代码实现
示例数据
参考<<机器学习实战>>书中的示例,并用python实现<<机器学习实战>>中ch05中的例子,这里将X0设置为1,即常数即样本的一条数据x=(1,x_1,x_2,…x_n),一共n个属性
数据文件见<<机器学习实战>>书中的ch05 testSet.txt一文本,以下截取部分样例
| x1 | x2 | y |
|---|---|---|
| -0.017612 | 14.053064 | 0 |
| -1.395634 | 4.662541 | 1 |
| -0.752157 | 6.538620 | 0 |
| -1.322371 | 7.152853 | 0 |
| 0.423363 | 11.054677 | 0 |
| 0.406704 | 7.067335 | 1 |
| 0.667394 | 12.741452 | 0 |
train.py代码
from numpy import *
# 一共三个特殊,x0为了方便计算设置为1,[x0=1,x1,x2]
# #readFile
def loadDataSet():
dataSet = []
labelVector = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split();
dataSet.append([1.0,float(lineArr[0]),float(lineArr[1])])# mX3
labelVector.append(int(lineArr[2])) # 1Xm
fr.close()
return dataSet,labelVector
##sigmoid函数
def sigmoid(x):
return 1.0/(1+exp(-x))
def gradAsend(dataSet,labelVector):
dataSetMat=mat(dataSet)
labelVectorMat=mat(labelVector).transpose() #mX1
m,n=shape(dataSetMat)#m=m,n=3
weights=ones((n,1))#initial weights=[1,1,1] 3X1
alpha=0.001
maxIterators = 500
for i in range(maxIterators):
h=sigmoid(dataSetMat*weights)# mx3 multiply 3X1
error=(labelVectorMat-h)
weights=weights+alpha*dataSetMat.transpose()*error
return weights
#画图方法
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
程序入口:
init.py
import train
if __name__ == '__main__':
dataSet,labelVector= train.loadDataSet()
weights = train.gradAsend(dataSet,labelVector)
print(weights)
train.plotBestFit(weights.getA())运行结果
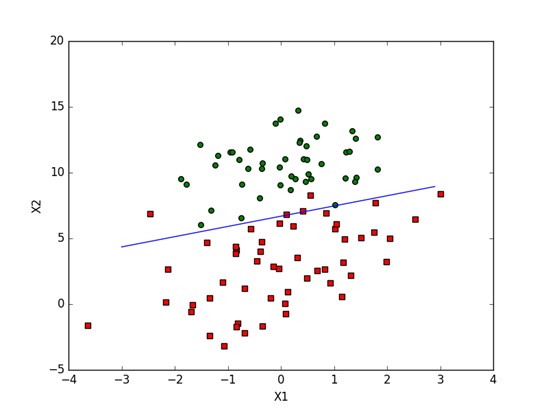















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









