






 CLIP是一种新型视觉模型,它利用互联网上的文本-图像对进行预训练,能够在多种视觉任务上实现zero-shot迁移,解决了传统视觉模型任务单一及泛化能力不足等问题。
CLIP是一种新型视觉模型,它利用互联网上的文本-图像对进行预训练,能够在多种视觉任务上实现zero-shot迁移,解决了传统视觉模型任务单一及泛化能力不足等问题。
前言
承接上一篇阅读笔记,本周阅读了CLIP的论文《Learning Transferable Visual Models From Natural Language 》。
论文地址:《Learning Transferable Visual Models From Natural Language 》
代码:https://github.com/openai
摘要
在构建计算机视觉模型时,只是为了某一个或某一组任务而构建数据集,往往需要大量的劳动力来进行数据标注,并且数据集的构建成本很高。而且,这些标准的计算机视觉模型擅长一类任务,甚至只擅长这一类任务。若是想要让模型适应新的任务需要花费大量的精力和成本。同时,一些训练时表现好的模型可能在测试中表现不佳。为了解决这些问题,CLIP诞生了。OpenAI从互联网收集了4亿(图像,文本)对的数据集,在预训练后,用自然语言描述所学习的视觉概念,类似于GPT-2 5和GPT-3的“zero-shot”功能。
方法
论文方法的核心是在自然语言的监督中学习。从自然语言中学习有几个潜在的好处:和用于图像分类的标准标记相比,扩展自然语言监督要更容易,因为不要求标注内容需要采用机器学习的兼容模式;自然语言可以在互联网上大量的文本中进行学习;自然语言学习不仅是学习一种表现,同时也将其和语言表示联系起来,灵活的实现“zero-shot”转移。
CLIP主要完成的任务是:给定一幅图像,在32768个随机抽取的文本片段中,找到能匹配的那个文本。为了完成这个任务,CLIP这个模型需要学习识别图像中各种视觉概念,并将视觉概念将图片关联,也因此,CLIP可以用于几乎任意视觉人类任务。例如,一个数据集的任务为区分猫和狗,则CLIP模型预测图像更匹配文字描述“一张狗的照片”还是“一张猫的照片”。
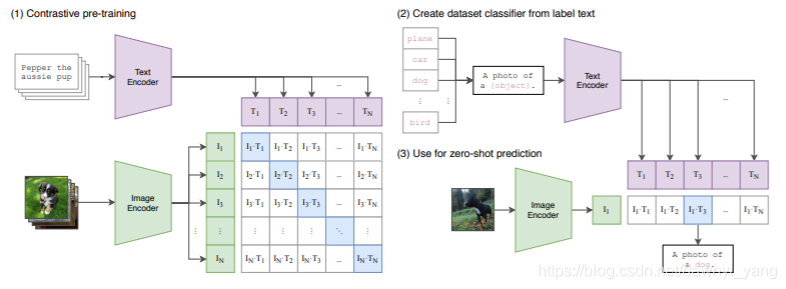
图1
CLIP的结构如图1所示,CLIP的工作流程是:预训练图像编码器和文本编码器,预测数据集中哪些图像与哪些文本匹配,然后将CLIP转换为“zero-shot”分类器。此外,将数据集所有的类转换为诸如“一条狗的照片”的标签,并预测最佳配对的图像。
图像编码器尝试了两种结构。
第一种是广泛应用和性能可靠的ResNet-50。使用ResNet-D来改进,和抗锯齿rect-2模糊池对原始版本进行了修改。将全局平均池层替换为注意池机制。注意池由一个单层的“transformer-style”多头QKV attentiion来实现,其中查询的条件是图像的全局平均池化表示。
第二种结构使用了Vision Transformer。
文本编码器使用了Transformer,使用了63M个参数、12层宽、有8个注意力头的模型。
数据集
论文使用了三个数据集:MS-COCO, Visual Genome ,和YFCC100M。
MS-COCO, Visual Genome是高质量的手工标注数据集,数量较小,约100000个。
YFCC100M有1亿张照片,每个图像质量不同,许多图像使用自动生成的文件名,例如e 20160716 113957.JPG作为名称或者描述。经过过滤后,只保留有正常标题或描述的图像,数据集缩小到1500万张照片。与ImageNet的数据集大小大致相同。
解决的问题
- 数据集成本巨大:ImageNet中1400万张图片的标注工程量巨大。而CLIP使用Internet上公开的文本-图像对。
- 任务单一:适用于各种视觉分类任务,而不用额外训练。
- 实用性不佳:CLIP可以不用在数据集上训练,直接在基准上评估,而不是仅优化其在基准性上的性能。
局限性
- 在一些更抽象或系统的任务和更复杂的任务上表现不佳。
- 对于不包含在其预训练数据集内的图像,模型泛化能力较差。
启发和思考
使用自然语言和图像结合的方式,为自然语言处理和计算机视觉的突破提供了动力。虽然目前还不是很广泛的应用,CLIP也是近一个月才发表的文章。但这种方法也给传统的计算机视觉模型的设计提供了新的思路。或许未来这种方法会得到大力发展,或者又有新的思路出现,但未来值得期待。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









