






摘要
Detection Transformer(DETR)是Facebook AI的研究者提出的Transformer的视觉版本,用于目标检测和全景分割。这是第一个将Transformer成功整合为检测pipeline中心构建块的目标检测框架。
论文地址:End-to-End Object Detection with Transformers
源代码:DETR
论文结构
第一部分主要介绍了为了解决以前的目标检测方法的性能受后处理的影响,文章提出了一种端到端的方法(DETR)在目标检测中进行尝试。
第二部分介绍了集合预测、Transformers以及目标检测的相关工作。
第三部分介绍了模型的详细信息。首先介绍了该模型使用集合预测要如何定义目标检测集预测损失。随后详细的介绍了模型各部分的详细结构。
第四部分使用了COCO数据集与Faster R-CNN进行了比较。
方法
DETR包含三个主要组件:
- CNN骨干网
- 编码器-解码器transformer
- 一个简单的前馈网络
首先,CNN骨干网从输入图像生成特征图。
然后,将CNN骨干网的输出转换为一维特征图,并将其作为输入传递到Transformer编码器。该编码器的输出是N个固定长度的嵌入(向量),其中N是模型假设的图像中的对象数。
Transformer解码器借助自身和编码器-解码器注意机制将这些嵌入解码为边界框坐标。
最后,前馈神经网络预测边界框的标准化中心坐标,高度和宽度,而线性层使用softmax函数预测类别标签。
结构见图1。

图1
Backbone
传统的CNN主干会生成较低分辨率的激活图f∈R C×H×W。 DETR使用的典型值是C = 2048和H,W = H0 / 32,W0 / 32。
Transformer encoder
首先,使用1x1卷积将高级激活映射的特征图f的通道维从C减小到较小的d, 创建一个新的特征图z0∈R d×H×W。 编码器期望一个序列作为输入,因此DETR将z0的空间尺寸折叠为一个尺寸,从而生成d×HW特征图。 每个编码器层均具有标准体系结构,并包括一个多头自我关注模块**(self-attention module)和一个前馈网络(FFN)**。 由于转换器的体系结构是置换不变的,因此DETR用固定的位置编码对其进行补充,该编码被添加到每个关注层的输入中。
Transformer decoder
解码器遵循transformer 的标准体系结构,使用多头自编码器和编码器-解码器注意机制转换大小为d的N个嵌入。与原始转换器的不同之处在于,DETR模型在每个解码器层并行解码N个对象,而Vaswani等人 [47]则是使用自回归模型,一次预测一个元素的输出序列。
由于解码器也是置换不变的,因此N个输入嵌入必须不同才能产生不同的结果。 这些输入嵌入是学习的位置编码,我们将其称为对象查询,并且与编码器类似,我们将它们添加到每个关注层的输入中。 N个对象查询由解码器转换为嵌入的输出。 然后,它们通过前馈网络(在下一个小节中进行描述)独立地解码为框坐标和类标签,从而得出N个最终预测。
利用对这些嵌入的自编码器和解码器注意力,该模型使用它们之间的成对关系,全局地将所有对象归结在一起,同时能够将整个图像用作上下文。
Prediction feed-forward networks (FFNs)
最终预测是由具有ReLU激活功能且具有隐藏层的3层感知器和线性层计算的。 FFN预测框的标准化中心坐标,高度和宽度, 输入图像,然后线性层使用softmax函数预测类标签。 由于我们预测了一组固定大小的N个边界框,其中N通常比图像中感兴趣的对象的实际数量大得多,因此使用了一个额外的特殊类标签∅来表示在未检测到任何对象。 此类在标准对象检测方法中与“背景”类具有相似的作用。
Auxiliary decoding losses
作者发现在训练过程中在解码器中使用辅助损耗auxiliary losses很有帮助,特别是有助于模型输出正确数量的每个类的对象。DETR在每个解码器层之后添加预测FFN和Hungarian loss,所有预测FFN共享其参数。 我们使用附加的共享层范数来标准化来自不同解码器层的预测FFN的输入
更具体的结构
如图2,给出了DETR中使用的转换器的详细说明,并在每个关注层传递了位置编码。来自CNN主干的图像特征通过了转换器编码器,并将空间位置编码与添加到查询和键处的空间编码一起传递。 然后,解码器接收查询(最初设置为零),输出位置编码(对象查询)和编码器内存,并通过多个多头自我关注和解码器-编码器关注来生成最终的一组预测类标签和边界框。 可以跳过第一解码器层中的第一自我注意层。

图2
损失函数
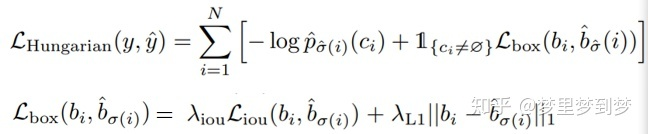
图3
实验
性能对比
与Faster RCNN有可比性,小目标要差一些。如图

图4 在COCO验证集上与使用ResNet-50和ResNet-101作为主干网络的Faster R-CNN 相比。
测试Encoder和Decoder要用多少层
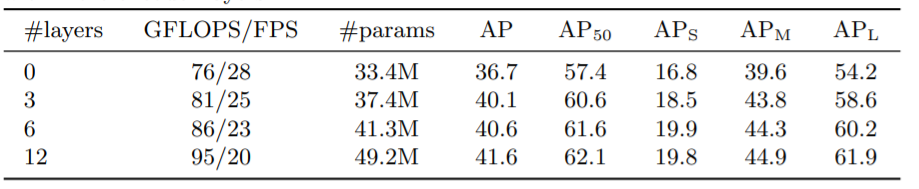
图5 编码器尺寸的影响

图6 解码器尺寸的影响
不同的Positional Encoding

图7
测试Loss

图8















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









