







自然语言处理(NLP)领域中,高质量的句子嵌入模型扮演着至关重要的角色,它们能够将复杂语言概念转化为易于机器处理的向量形式。paraphrase-multilingual-MiniLM-L12-v2。它是sentence-transformers库中的一员,擅长于多语言环境下的句子相似性检测和文本分析
适用范围
该模型适用于各种NLP任务,其中包括:
- 语义搜索:通过语义相似度快速找到相关文本。
- 文本聚类:自动将相似的句子或段落分组。
- 句子相似性比较:用于比较两个句子的相似度。
安装及验证
import os from sentence_transformers import SentenceTransformer # 方案1:使用镜像 os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" try: model = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2") print("模型加载成功!") except Exception as e: print(f"错误: {e}") print("请检查网络或尝试手动下载模型。")# 方案二:下载本地
git clone https://hf-mirror.com/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
import os from sentence_transformers import SentenceTransformer try: model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2") print("模型加载成功!") except Exception as e: print(f"错误: {e}") print("请检查网络或尝试手动下载模型。")
使用:
from sentence_transformers import SentenceTransformer
import numpy as np
# 或在 Python 代码中设置
class TextEncoder:
def __init__(self, model_name='paraphrase-multilingual-MiniLM-L12-v2'):
self.model = SentenceTransformer(model_name)
def encode(self, texts):
return self.model.encode(texts, convert_to_numpy=True)
from utils.encoder import TextEncoder from sklearn.metrics.pairwise import cosine_similarity question = ['Python中如何读取文件?'] user_question = ['如何用Python打开文件'] encoder = TextEncoder() q_vector = encoder.encode(question) user_q_vector = encoder.encode(user_question) # 计算相似性 sim_scores = cosine_similarity(q_vector, user_q_vector) print(sim_scores)
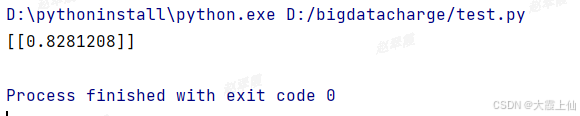
通过阈值 判断是否通过
if sim_scores[0][0] >= 0.8:
print("通过")
else:
print("不通过")
注sim_scores 是二位数组,取值需要[0][0],该值要序列化的话,需要转成float ,通过
sim_scores[0][0].item() 实现

















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









