






文集 移动端网页端爬虫
前言
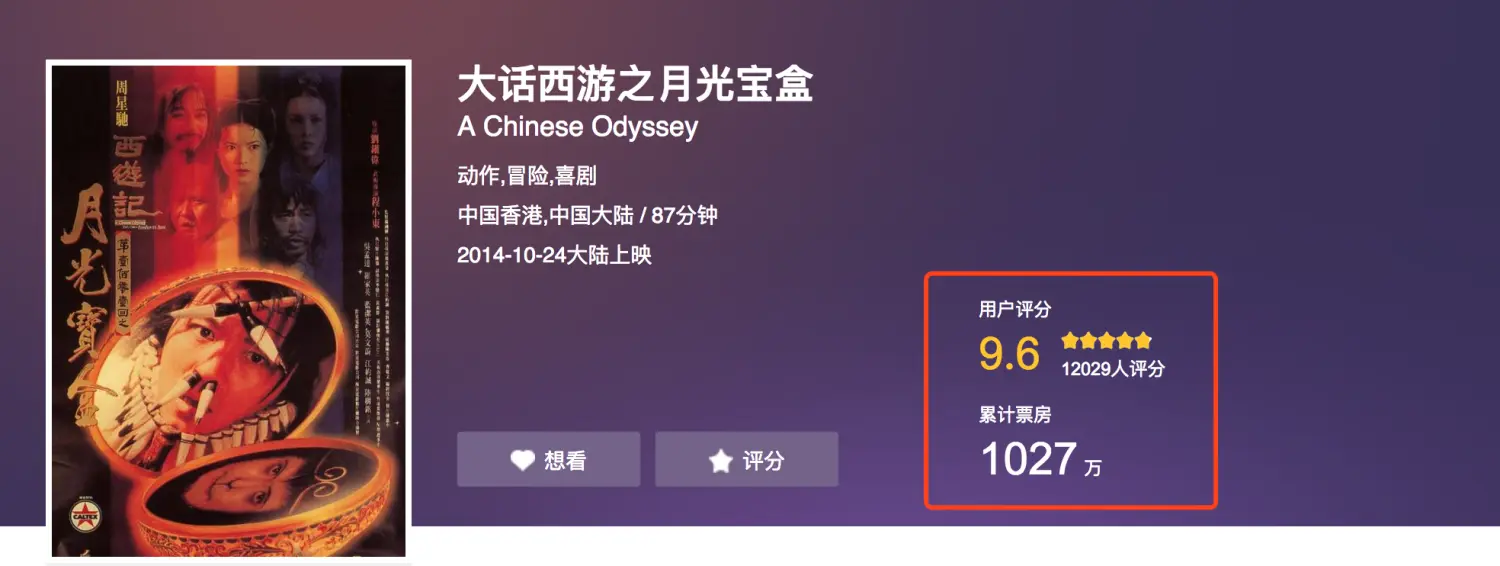
本来想通过网页端来抓取猫眼电影的一些票房数据,但是发现
maoyan1.png

maoyan2.png
小看了。下面将提供两种应对策略。编码集和图像识别
分析
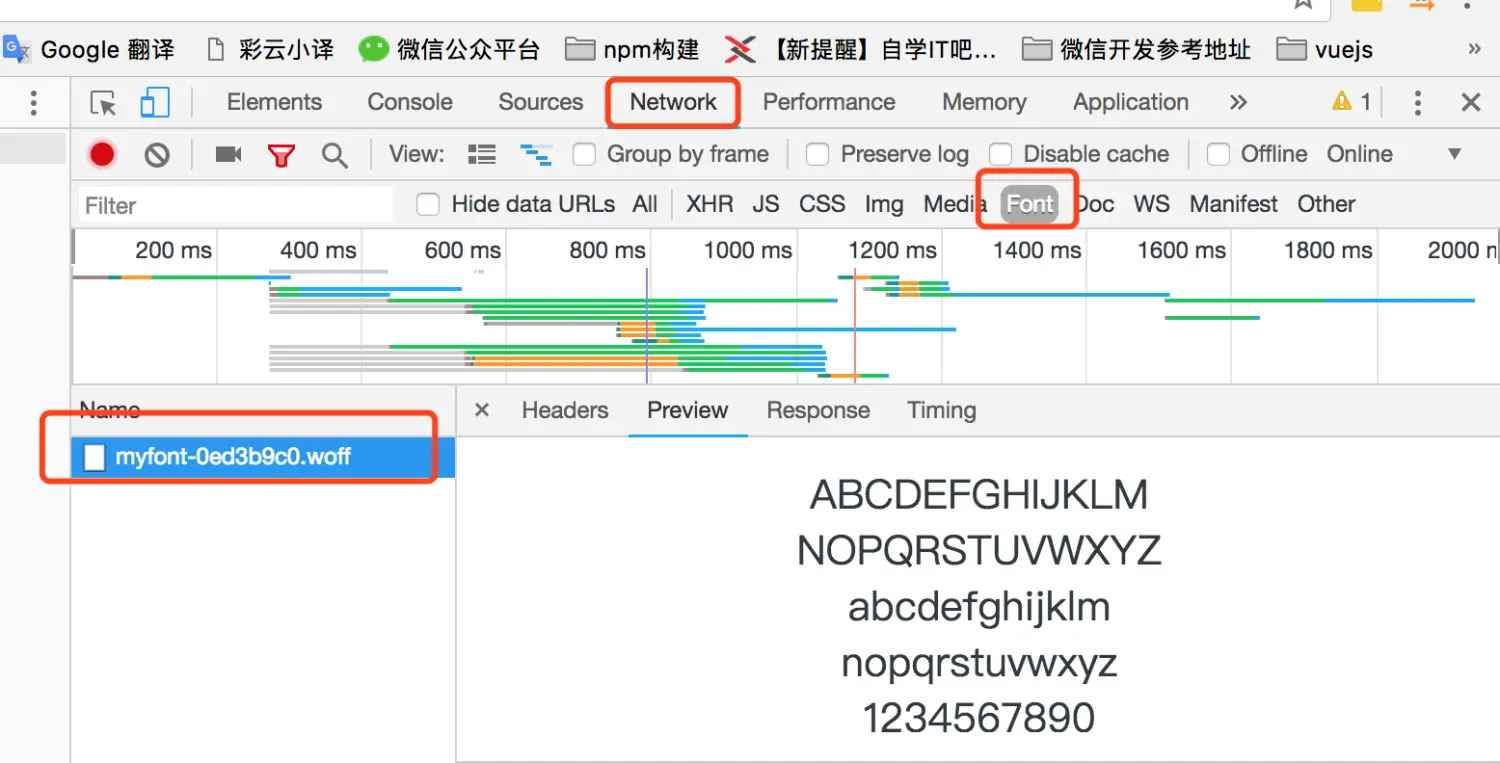
- F12 -> network -> font,可以看出.woff文件其实是一个自定义的字符子,它告诉浏览器怎样显示那些奇怪的编码成人类可以看懂的字符,所以我们要做的就是要找出这些 到 数字的映射关系
maoyan3.png
这是我提前准备的, &#x 换成 uni
self.manual_dict = {
'uniF3C5': 8,
'uniEDEE': 6,
'uniF38E': 2,
'uniE824': 3,
'uniE829': 5,
'uniE851': 0,
'uniEBCF': 1,
'uniEE5A': 9,
'uniEFFE': 4,
'uniF35D': 7,
}
实践
-
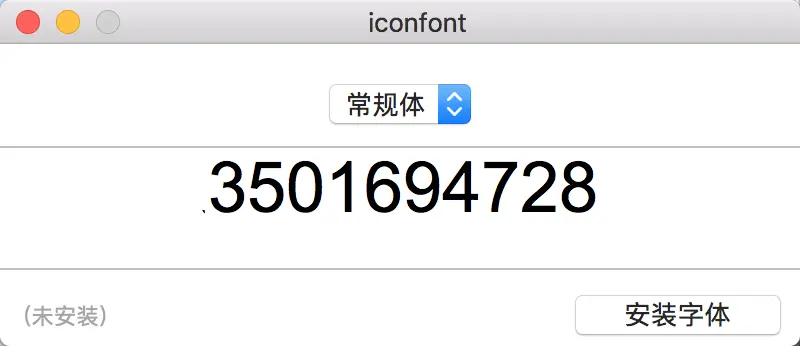
如何找出映射关系 这里给出mac 中文版上的方法
下载.woff文件
修改后缀为.ttf
双击打开,即可看到
ttf1.png
- 代码,生成xml文件
from fontTools.ttLib import TTFont
font = TTFont('/Users/apple/test/dolphin/opt/fonts/2c8d9a8f5031f26f4e9fe924263e31ce2076.woff')
font.saveXML('/Users/apple/test/dolphin/opt/fonts/2c8d9a8f5031f26f4e9fe924263e31ce2076.xml')
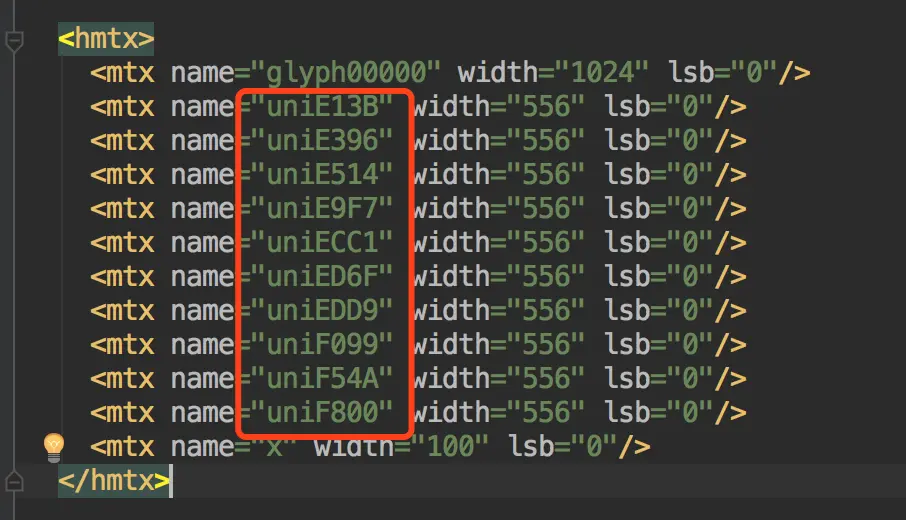
- xml文件的htmx节点的顺序与‘3501694728’顺序一致
woff1.png
到此,得到了我们想要的映射关系,以后所有猫眼的网页只要拿到编码就能得到对应的数字了。No,猫眼网页每次返回的woff文件是不同的所以映射关系也不同。怎么办!
-
看来上面的方法得到的只是一个临时的映射关系,下面分析如何得到永久有效的映射关系
- 继续观察生成的xml文件(glyf节点)。正好对应是个数字
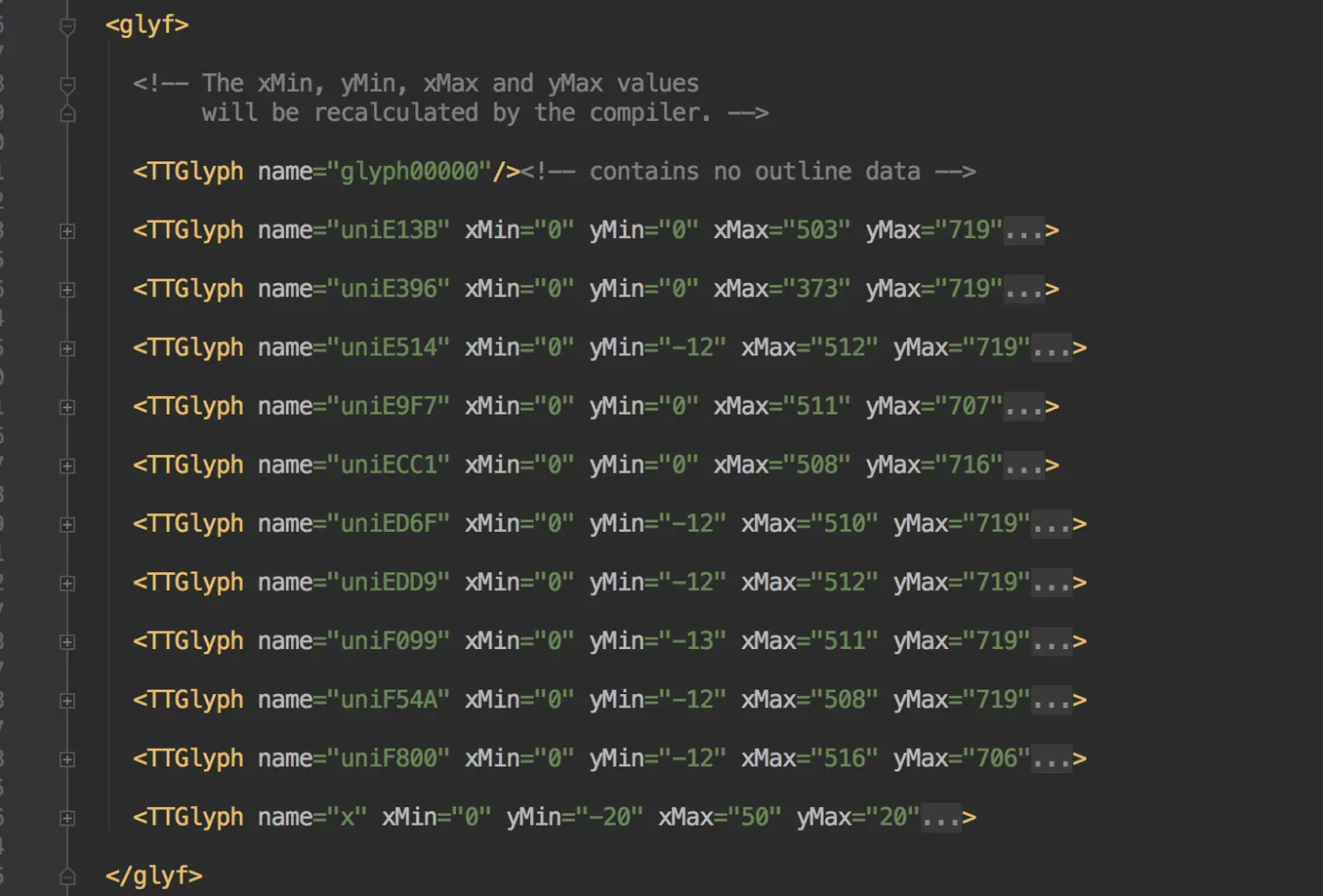
woff2.png
-
每个TTGlyph节点都是xy点,看着这个xy矩阵才是真正决定编码“画成”什么图形的关键
 woff3.png
woff3.png -
试想,如果我们把上面得到的 “编码到数字”映射关系换成“xy矩阵到数字”的映射关系会怎样!没错,每当我们请求网页的时候拿到woff文件
woff文件 —> xml文件 —> 通过编码()得到xy的矩阵 —> 查找“xy矩阵到数字”映射表得到数字
ok一切完成。
源码
# -*- coding: utf-8 -*-
import os
from utils.log import logging
from utils.requestshelper import RequestsHelper
from fontTools.ttLib import TTFont
# pip install Pillow
from PIL import Image, ImageEnhance
from pytesseract import *
logger = logging.getLogger(__name__)
class WebFont(object):
def _init_font_map(self):
"""
初始化猫眼的字符集模版,只在倒入模块时有构造方法调用一次
"""
font_file = self.__save_font_file(self.url)
font = TTFont(font_file)
glyph_set = font.getGlyphSet()
glyph_dict = glyph_set._glyphs.glyphs
for k, v in self.manual_dict.items():
self.font_dict[glyph_dict[k].data] = v
def __save_font_file(self, url):
filename = url.split('/')[-1]
font_dir = "%s/%s" % (os.path.dirname(__file__), '../opt/fonts')
# 判断文件是否存在
if not os.path.exists("%s/%s" % (font_dir, filename)):
if not os.path.exists(font_dir):
os.mkdir(font_dir)
try:
response = RequestsHelper.get(url)
except Exception:
raise Exception()
with open("%s/%s" % (font_dir, filename), 'wb') as fw:
fw.write(response.content)
return "%s/%s" % (font_dir, filename)
def convert_to_num(self, series, url):
"""
获取unicode的对应的数字, woff编码文件必须是编码所用的文件
:param series: int 编码对应的十六进制数
:param url: woff编码集文件的地址
:return: int,series对应数字
"""
font_file = self.__save_font_file(url)
font = TTFont(font_file)
cmap = font.getBestCmap()
num = cmap.get(series)
glyph_set = font.getGlyphSet()
return self.font_dict[glyph_set._glyphs.glyphs[num].data]
class MaoYanWebFont(WebFont):
def __init__(self):
self.url = 'https://vfile.meituan.net/colorstone/2c8d9a8f5031f26f4e9fe924263e31ce2076.woff'
self.plat_name = 'maoyan'
self.font_dict = dict()
# 手动一次整理出 "编码-数字"映射关系,程序自动获得 "xy矩阵-数字"映射关系
self.manual_dict = {
'uniF3C5': 8,
'uniEDEE': 6,
'uniF38E': 2,
'uniE824': 3,
'uniE829': 5,
'uniE851': 0,
'uniEBCF': 1,
'uniEE5A': 9,
'uniEFFE': 4,
'uniF35D': 7,
}
self._init_font_map()
class FontManager(object):
def __init__(self):
self.fonts = dict()
def add_font(self, webfont):
"""
倒入该模块时调用此方法初始化字符集模版
:param webfont: WebFont
"""
if webfont.plat_name == 'maoyan':
self.fonts['maoyan'] = webfont
elif webfont.plat_name == 'douyin':
pass
else:
raise Exception('平台:%s 暂不支持' % webfont.plat_name)
def get_font(self, plat_name):
try:
return self.fonts[plat_name]
except KeyError:
raise Exception('请先调用get_font()来添加平台%s的字符集' % plat_name)
def convert_to_num_ocr(self, fp):
"""
获取unicode的对应的数字
:param fp: 图片文件的路径或文件对象(必须byte方式打开)
:return: 图片对应的数字, 如果不符合数字格式,则返回图片上的文本
"""
im = Image.open(fp)
enhancer = ImageEnhance.Contrast(im)
image_enhancer = enhancer.enhance(4)
im_orig = image_enhancer.resize((image_enhancer.size[0]*2, image_enhancer.size[1]*2), Image.BILINEAR)
text = image_to_string(im_orig)
try:
return int(text)
except ValueError:
return text
fm = FontManager()
fm.add_font(MaoYanWebFont())
maoyan_font = fm.get_font('maoyan')
#########################
# 通过woff文件
#########################
# 任意一次打开猫眼网页,给定编码对应的十六进制数和编码所用的woff文件,自动分析出数字
logger.info(maoyan_font.convert_to_num(0xf8c3, 'https://vfile.meituan.net/colorstone/7986a5279399aeee3ef19fe37989a00d2088.woff'))
#########################
# 通过 ocr
#########################
fp = open('/Users/apple/test/dolphin/opt/WX20180607-172930@2x.png', 'rb')
print(fm.convert_to_num_ocr(fp))
备注:无论如何都需要手动整理一次woff的映射关系,上面给出了mac上的方面,至于windows,思路:1.根据xml文件得到所有的编码;2. 仿照原网页写个简单的页面,包含所有的编码,就能看到编码对应的数字















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









