







1.内存模型
-
堆
共享数据,存放我们new的对象。
-
栈
线程私有,存放我们的局部变量表、操作数栈、方法出口等信息。
-
方法区(元数据空间)
共享数据,存放我们常量、类信息、静态变量。
-
计数器
线程私有,记录每个线程的计算位置。
2.类加载过程
加载–》校验 --》准备 --》解析 --》初始化
-
加载
根据查找路径找到对应的class文件,然后导入。
-
校验
校验class文件的正确性
-
准备
给类中的静态变量分配内存空间
-
解析
将常量池中的符号引用转换为直接指向内存地址的直接引用
-
初始化
静态变量和静态代码块执行初始化工作
3.垃圾收集算法
3.1 对象是否可回收
-
引用计数
为每个对象创建一个引用计数,有对象引用时计数器+1,引用被释放时计数器-1,当计数器为0时就可以被回收。注意:该算法存在一个问题,不能解决循环引用的问题。
-
可达性分析
从GC Roots开始进行搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链相连接时,证明此对象时可以被回收的。
3.2 回收算法
-
标记清除
标记无用对象,然后进行清除回收。缺点:效率不高,无法清除垃圾碎片。
-
标记整理
标记无用对象,把存活对象移动到一端。直接清除到存活对象以外的内存。
-
复制算法
内存划分两个大小的内存区域,当一块用完时将活着的对象复制到另一块内存,并将该内存清空。缺点:内存使用率低。
-
分带算法
根据对象的存活周期的不同将内存划分为几块,一般是新生代和老年代,新生代基本采用复制算法,老年代算法采用标记整理算法。
4.垃圾收集器
-
Serial
最早的单线程串行垃圾回收器
-
Serial Old
Serial垃圾收集器的老年代版本。可以作为CMS垃圾收集器的备选方案。
-
ParNew
Serial的多线程版本
-
Parallel
和ParNew收集器类似,多线程。但,其是吞吐量优先的收集器。牺牲等待时间换取系统的吞吐量。
-
Parallel Old
Parallel的老年代版本,Parallel使用的是复制算法,Parallel Old使用标记整理算法。
-
CMS
获取短暂停顿时间为目标的收集器。
CMS 使用的是标记-清除的算法实现的,所以在 gc 的时候回产生大量的内存碎片,当剩余内存不能满足程序运行要求时,系统将会出现 Concurrent Mode Failure,临时 CMS 会采用 Serial Old 回收器进行垃圾清除,此时的性能将会被降低。
-
G1
兼容了吞吐量和停顿时间的GC实现
5.问题定位和优化
-
调优工具
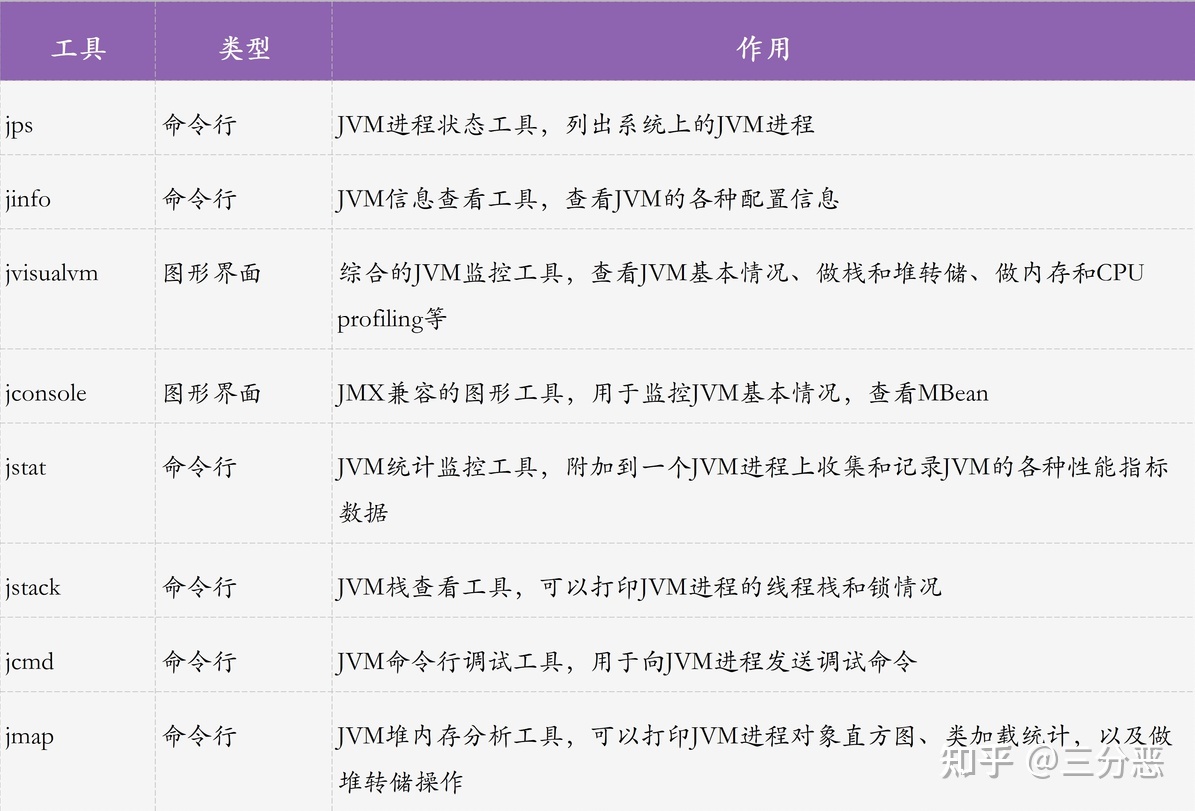
第三方工具Arthas
-
常用参数
-
-Xms
s为strating,表示堆内存起始大小
-
-Xmx
x为max,表示最大的堆内存
一般-Xms和-Xmx的设置为相同大小,因为当heap自动扩容时,会发生内存抖动,影响程序的稳定性
-
-Xmn
n为new,表示新生代大小
-
-Xss
规定了每个线程虚拟机栈(堆栈)的大小
-
-XX:SurvivorRator=8
表示堆内存中新生代、老年代和永久代的比为8:1:1
-
-XX:PretenureSizeThreshold=3145728
当创建(new)的对象大于3M的时候直接进入老年代
-
-XX:MaxTenuringThreshold=15
当对象的存活的年龄(minor gc一次加1)大于多少时,进入老年代
-
-XX:-DisableExplicirGC
是否(+表示是,-表示否)打开GC日志
-















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









