






本博客对应的视频教程:
https://edu.csdn.net/course/detail/35238

Delta Lake自动验证正在写入的DataFrame的schema是否与表的schema兼容。Delta Lake使用以下规则来确定从DataFrame写入表是否兼容:
-
所有DataFrame列必须存在于目标表中。如果DataFrame中的列没有出现在表中,则会引发异常。在表中但不在DataFrame中的列被设置为空。
-
DataFrame列数据类型必须与目标表中的列数据类型匹配。如果它们不匹配,将引发异常。
-
DataFrame列名不能只是大小写不同。这意味着不能在同一个表中定义像“Foo”和“foo”这样的列。Spark可以区分大小写或不区分大小写(默认),而Parquet在存储和返回列信息时是区分大小写的。Delta Lake是保留大小写的,但在存储模式时不敏感,并且有这种限制以避免潜在的错误、数据损坏或丢失问题。---大小写敏感
Delta Lake支持DDL显式地添加新列,并能够自动更新模式。
更新表模式
Delta Lake允许更新表模式。支持以下类型的更改:
-
添加新列(在任意位置)
-
重新排序现有列
可以显式地使用DDL或隐式地使用DML进行这些更改。
| 重要提醒 当更新Delta表模式时,从该表读取的流将终止。如果希望流继续,必须重新启动它。 |
显式更新模式
可以使用下面的DDL显式地更改表的模式。
//添加列语法
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name], ...)
添加列实例1--向delta_events添加两列--col_add1,col_add2
//添加列:向delta_events添加两列--col_add1,col_add2
//显示添加列之前的schema
spark.sql("select * from delta_events").printSchema();
String add_column_sql = "ALTER TABLE delta_events ADD COLUMNS (col_add1 string COMMENT '测试添加列1' ,col_add2 date COMMENT '测试添加列2')";
spark.sql(add_column_sql);
//显示添加列之后的schema
spark.sql("select * from delta_events").printSchema();
代码执行结果:
root
|-- date: date (nullable = true)
|-- eventId: string (nullable = true)
|-- eventType: string (nullable = true)
|-- data: string (nullable = true)
root
|-- date: date (nullable = true)
|-- eventId: string (nullable = true)
|-- eventType: string (nullable = true)
|-- data: string (nullable = true)
|-- col_add1: string (nullable = true)
|-- col_add2: date (nullable = true)
添加列实例2--在指定位置添加列
//在指定位置添加列
//显示添加列之前的schema
spark.sql("select * from delta_events").printSchema();
String add_column_sql = "ALTER TABLE delta_events ADD COLUMNS (col_add11 string COMMENT '测试添加列11' after col_add1)";
spark.sql(add_column_sql);
//显示添加列之后的schema
spark.sql("select * from delta_events").printSchema();
root
|-- date: date (nullable = true)
|-- eventId: string (nullable = true)
|-- eventType: string (nullable = true)
|-- data: string (nullable = true)
|-- col_add1: string (nullable = true)
|-- col_add2: date (nullable = true)
root
|-- date: date (nullable = true)
|-- eventId: string (nullable = true)
|-- eventType: string (nullable = true)
|-- data: string (nullable = true)
|-- col_add1: string (nullable = true)
|-- col_add11: string (nullable = true)
|-- col_add2: date (nullable = true)
添加列实例3--添加嵌套列
//语法
ALTER TABLE table_name ADD COLUMNS (col_name.nested_col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name], ...)
| 注意 只支持在struct字段类型中添加嵌套列。不支持Arrays和maps类型中添加嵌套列。 |
第一步先添加struct类型列
//添加嵌套列,先添加一个struct类型的列
//显示添加列之前的schema
spark.sql("select * from delta_events").printSchema();
String add_column_sql = "ALTER TABLE delta_events ADD COLUMNS (col_add3 struct<col_add31:string> COMMENT 'struct类型列')";
spark.sql(add_column_sql);
//显示添加列之后的schema
spark.sql("select * from delta_events").printSchema();
第二步添加嵌套列
//添加嵌套列
//显示添加列之前的schema
spark.sql("select * from delta_events").printSchema();
String add_column_sql = "ALTER TABLE delta_events ADD COLUMNS (col_add3.col_add32 string COMMENT '添加嵌套列')";
spark.sql(add_column_sql);
//显示添加列之后的schema
spark.sql("select * from delta_events").printSchema();
spark.close();
root
|-- date: date (nullable = true)
|-- eventId: string (nullable = true)
|-- eventType: string (nullable = true)
|-- data: string (nullable = true)
|-- col_add1: string (nullable = true)
|-- col_add11: string (nullable = true)
|-- col_add2: date (nullable = true)
|-- col_add3: struct (nullable = true)
| |-- col_add31: string (nullable = true)
root
|-- date: date (nullable = true)
|-- eventId: string (nullable = true)
|-- eventType: string (nullable = true)
|-- data: string (nullable = true)
|-- col_add1: string (nullable = true)
|-- col_add11: string (nullable = true)
|-- col_add2: date (nullable = true)
|-- col_add3: struct (nullable = true)
| |-- col_add31: string (nullable = true)
| |-- col_add32: string (nullable = true)
查看表元数据
在前面代码中,我们添加了字段注释,但是printSchema()方法并没有显示出delta表的注释信息。查看delta表的注释信息,可以使用DESCRIBE TABLE语句----注意,这个命令只适用于metastore定义的表。
//显示表元数据
spark.sql("DESCRIBE TABLE delta_events").show();
//显示更详细的表元数据
spark.sql("DESCRIBE TABLE extended delta_events").show(false);

修改列备注及列顺序
//语法
ALTER TABLE table_name CHANGE [COLUMN] col_name col_name data_type [COMMENT col_comment] [FIRST|AFTER colA_name]
//修改列注释及顺序
//修改前schema信息
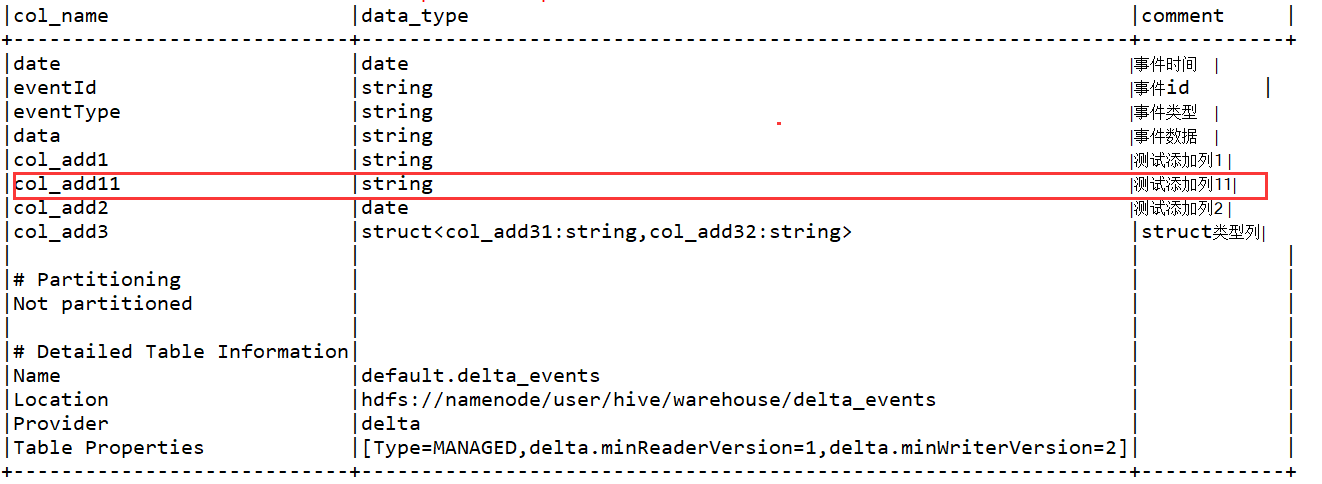
spark.sql("DESCRIBE TABLE extended delta_events").show(false);
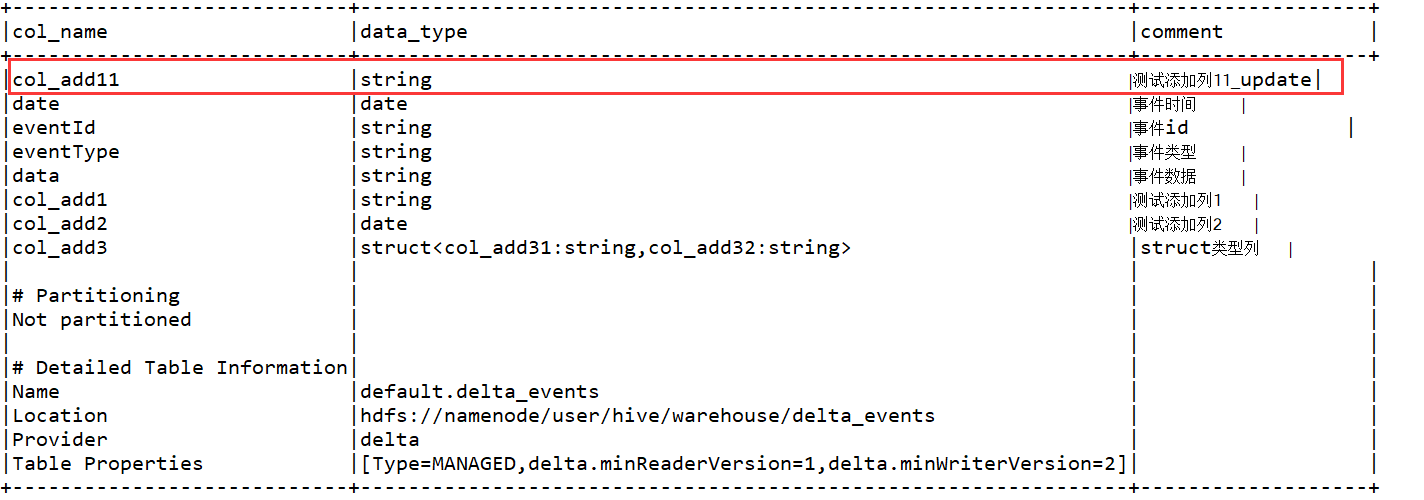
//修改col_add11的列备注,并将其移到第一列
spark.sql("ALTER TABLE delta_events change column col_add11 col_add11 string comment '测试添加列11_update' first ");
//修改后schema信息
spark.sql("DESCRIBE TABLE extended delta_events").show(false);
| 注意 不能使用此方式更改列类型或者删除列: ALTER TABLE delta_events change column col_add11 col_add11 date 报错: Cannot update default.delta_events field col_add11: string cannot be cast to date; line 1 pos 0; |
自动模式更新
Delta Lake可以以DML事务的一部分自动更新表模式(append或overwrite),并使模式与正在写入的数据兼容。
本博客对应的视频教程:
https://edu.csdn.net/course/detail/35238
















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











