









1.PyTorch vs TensorFlow
tensorflow是静态图,需要你把啥都准备好,然后它像个傻子一样执行,tensorflow,目前业界更适合部署,毕竟是静态图,infer的时候速度快。
pytorch,它会在执行的时候,跟你唠嗑,哪哪需要改不,哦,不改昂,那我执行了,pytorch更适合学术界,因为它更开发、调试更人性化。
(人工智能核心算法的底层还是由C/C++编写,python实际上实现API调用功能)
2.logit函数
该函数可以将输入范围在[0,1]之间的数值p映射到[−∞,∞][−∞,∞]
如果p=0.5,则函数值为0,p<0.5,则函数值为负值;如果p>0.5,则函数值为正值。
PyTorch(tensorflow类似)的损失函数中,有一个(类)损失函数名字中带了with_logits.。而这里的logits指的是,该损失函数已经内部自带了计算logit的操作,无需在传入给这个loss函数之前手动使用sigmoid/softmax将之前网络的输入映射到[0,1]之间。
不管是二分类,还是多分类问题,其实在计算损失函数的过程都经历了三个步骤:
(1)激活函数。通过激活函数sigmoid或者是softmax将输出值缩放到[0,1]之间;
(2)求对数。计算缩放之后的向量的对数值,即所谓的logy的值,求对数之后的值在[-infinite,0]之间;
(3)累加求和。根据损失函数的定义,将标签和输出值逐元素相乘再求和,最后再添加一个负号求相反数,得到一个正数损失。
不管什么样的实现方式,都会经历这三个步骤,不同的是,可能有的函数会将其中的一个或者是几个步骤封装在一起。
例如:
(1)BCELoss:需要先将最后一层经过sigmoid进行缩放然后再通过该函数;
(2)BCEWithLogitsLoss:BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步,不再需要在最后经过sigmoid进行缩放,直接对最后得到的logits进行处理。
注意:logits,指的是还没有经过sigmoid和softmax缩放的结果
补充:
三维tensor(C,H,W),dim=0,1,2,-1(可理解为维度索引),其中2与-1等价,相同效果:
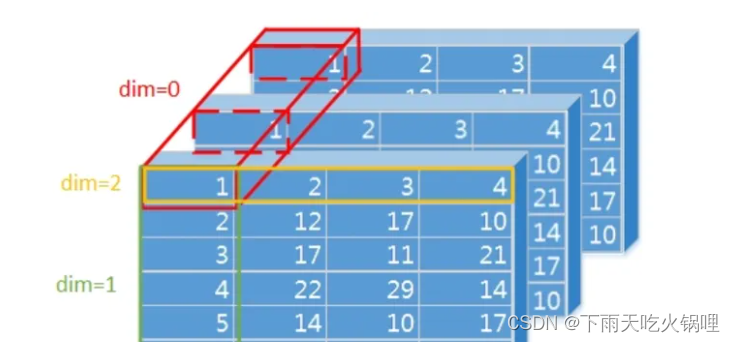
当dim=0时, 是对每一维度相同位置的数值进行softmax运算,和为1
当dim=1时, 是对某一维度的列进行softmax运算,和为1
当dim=2时, 是对某一维度的行进行softmax运算,和为1
同样的,四维tensor(B,C,H,W)dim取值0,1,2,3,-1,三维tensor也可以看成是batchsize=1的四维tensor,只是dim的索引需要加1。















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









