






posted on September5, 2012 by dbtube
In order to meet the challenges of Big Data, you must rethink data systems from the ground up. You will discover that some of the most basic ways people manage data in traditional systems like the relational database management system (RDBMS)is too complex for Big Data systems. The simpler, alternative approach is a new paradigm for Big Data. In this article based on chapter 1, author Nathan Marz shows you this approach he has dubbed the “lambda architecture.”
面对大数据的挑战,你不得不从头重新思考数据系统。你会发现,面对大数据,像关系型数据库管理系统(RDBMS)这样的传统系统人们管理数据的一些常用的基本方法太复杂。对大数据来说,一个相对简单,可选方式是一种新范式。这篇文章基于第一章,作者NathanMarz展示给你的这种方式被他称为“lambda架构”。
This article is based on Big Data, to be published in Fall 2012. This eBook is available through the Manning Early Access Program (MEAP). Download the eBook instantly from manning.com. All print book purchases include free digital formats (PDF, ePub and Kindle). Visit the book’s page for more information based on Big Data. This content is being reproduced here by permission from Manning Publications.
Author: Nathan Marz
Computing arbitrary functions on an arbitrary dataset in real time is a daunting problem. There is no single tool that provides a complete solution. Instead, you have to use a variety of tools and techniques to build a complete Big Data system.
在任意的数据集上实时任意计算是个令人望而却步的难题。没有提供一个完整解决方案的单一工具。因此,为了建立一个完整的大数据系统你不得不使用很多的工具和技术。
The lambda architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer.
Lambda架构解决在任意数据上实时任意计算的难题,是通过将问题分解成以下三个层次:批处理层,服务层,高速层。
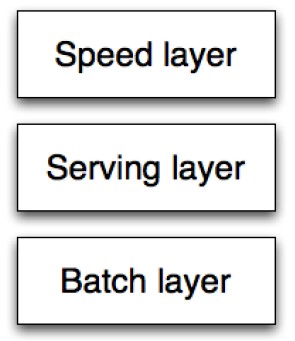
Figure 1 – Lambda Architecture
Everything starts from the “query = function(all data)”equation. Ideally, you could literally run your query functions on the fly on a complete dataset to get the results. Unfortunately, even if this were possible,it would take a huge amount of resources to do and would be unreasonably expensive.Imagine having to read a petabyte dataset every time you want to answer the query of someone’s current location.
一切都是从“query =function(all data)”公式开始的。理想情况下,你可以在完整的数据集上飞快的得到你的查询结果。不幸的是,即使这可能,也是通过使用非常多的资源来做并且花销极其昂贵。相像一下每次查询某人的当前位置都需要读取数T数据的情景。
The alternative approach is to precompute the query function. Let’s call the precomputed query function the batch view. Instead of computing the query on the fly, you read the results from the precomputed view. The precomputed viewis indexed so that it can be accessed quickly with random reads. This system looks like this:
一个可选的方式是提前计算这些查询,我们称这种提前计算的查询为批处理视图。从提前计算视图中读取结果,而不是在大数据集中实时计算。提前计算视图是索引好的,因此在随机读时可以很快的被访问。这个系统看起来是这样:
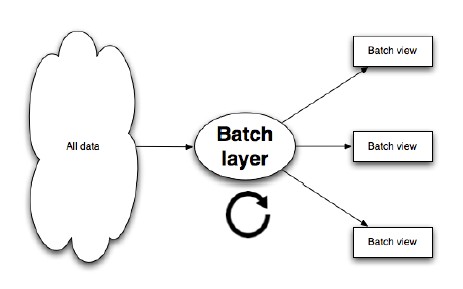
Figure 2 – Batch layer
In this system, you run a function on all of the data to get the batch view. Then, when you want to know the value for a query function,you use the precomputed results to complete the query rather than scan through all of the data. The batch view enables you to get the values you need from it very quickly because it’s indexed.
在这个系统中,你提前在所有数据上运行计算以得到批处理视图。然后,当你想从查询中得到值时,直接从预计算结果中完成查询而不是扫描所有的数据。因为批处理社图是提前索引好的,因此可以让你很快的得到结果。
Since this discussion is somewhat abstract,let’s ground it with an example.
因为这个讨论有点抽象,我们先用一个例子讲解一下。
Suppose you’re building a web analytics application and you want to query the number of pageviews for a URL on any range of days. If you were computing the query as a function of all the data, you would scan the dataset for pageviews for that URL within that time range and return the count of those results. This, of course, would be enormously expensive because you would have to look at all the pageview data for every query you do.
假如你建一个WEB分析应用,你想知道一个URL在一段时间内的页面访问量。如果你从所有数据中计算得到,你可能需要扫描这个URL在这段时间内的所有数据然后再返回结果。当然这种方式,非常的昂贵因为每次查询都需要查找所有相关数据。
The batch view approach instead runs a function on all the pageviews to precompute an index from a key of [url, day] to the count of the number of pageviews for that URL for that day. Then, to resolve the query,you retrieve all of the values from that view for all of the days within that time range and sum up the counts to get the result. The precomputed view indexes the data by URL, so you can quickly retrieve all of the data points you need to complete the query.
You might be thinking that there’s something missing from this approach as described so far. Creating the batch view is clearly going to be a high latency operation because it’s running a function on all of the data you have. By the time it finishes, a lot of new data that’s not represented in the batch views will have been collected, and the queries are going to be out of date by many hours. You’re right, but let’s ignore this issue for the moment because we’ll be able to fix it. Let’s pretend that it’s okay for queries to be out of date by a few hours and continue exploring this idea of precomputing a batch view by running a function on the complete dataset.
Batch layer
The portion of the lambda architecture that precomputesthe batch views is called the batch layer. The batch layer stores the master copy of the dataset and precomputes batch views on that master dataset. The master dataset can be thought of us a very large list of records.
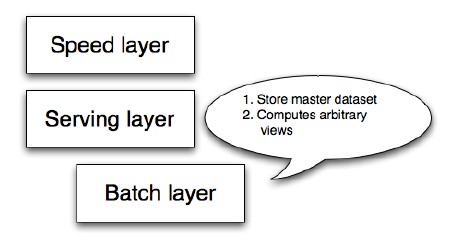
Figure 3 – Batch layer
The batch layer needs to be able to do two things to do its job: store an immutable, constantly growing master dataset, and compute arbitrary functions on that dataset. The key word here is arbitrary. If you’re going to precompute views on a dataset, you need to be able to do so for any view and any dataset. There’s a class of systems called batch processing systems that are built to do exactly what the batch layer requires. They are very good at storing immutable, constantly growing datasets, and theyexpose computational primitives to allow you to compute arbitrary functions onthose datasets. Hadoop is the canonical example of a batch processing system, and we will use Hadoop to demonstrate the concepts of the batch layer.
这里的关键字是任意。如果你在一个数据集上做预计算视图,那么你应该在任何数据集上都这样做。批处理层需要一种叫批处理的系统。他们非常擅长存储不可变、不断增长的数据集,并且可以在那些数据集上计算任意功能。Hadoop是批处理系统的典范,我们就用hadoop演示批处理层的概念。
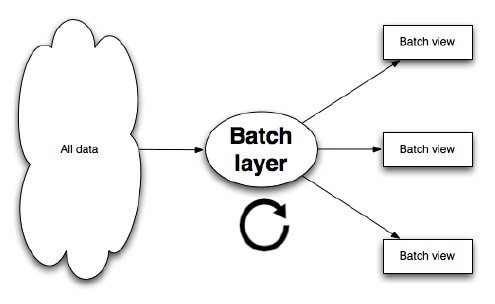
Figure 4 – Batch layer
The simplest form of the batch layer can be represented in pseudo-code like this:
最简单的批处理层可以用以下依代码表示:
function runBatchLayer():
while(true):
recomputeBatchViews()
The batch layer runs in a while(true) loop and continuously recomputes the batch views from scratch. In reality, the batch layer will be a little more involved. This is the best way to think about the batch layer for the purpose of this article.
批处理层从头开始运行一个while循环持续的计算批处理视图。事实上,批处理层会稍微多些介入,这篇文章的目的也是用最好的方式去思考批处理层。
The nice thing about the batch layer is that it’s so simple to use. Batch computations are written like single-threaded programs yet automatically parallelize across a cluster of machines. This implicit parallelization makes batch layer computations scale to datasets of any size.It’s easy to write robust, highly scalable computations on the batch layer.
批处理比较好的地方是它比较容易使用。批处理可以像单线程编程那样写,其后会在整个集群上自动的并行化。隐式的并行化使得批处理可以扩展到任意大小的数据集,在批处理层上可以容易的编写健壮、高伸缩的计算。
Here’s an example of a batch layer computation. Don’t worry about understanding this code; the point is to show what an inherently parallel program looks like.
这里有个批处理的例子。不用担心理解这段代码,它只是展示并行编程看起来是什么样的:
Pipe pipe= new Pipe(“counter”);
pipe = new GroupBy(pipe, new Fields(“url”));
pipe = new Every(
pipe,
new Count(new Fields(“count”)),
new Fields(“url”, “count”));
Flow flow = new FlowConnector().connect(
new Hfs(new TextLine(new Fields(“url”)), srcDir),
new StdoutTap(),
pipe);
flow.complete();
This code computes the number of pageviews for every URL, given an input dataset of raw pageviews.What’s interesting about this code is that all of the concurrencychallenges of scheduling work, merging results, and dealing with runtimefailures (such as machines going down) are done for you. Because the algorithm is written in this way, it can be automatically distributed on a MapReduce cluster, scaling to however many nodes you have available. So, if you have 10 nodes in your MapReduce cluster, the computation will finish about 10 times faster than if you only had one node! At the end of the computation, theo utput directory will contain a number of files with the results.
这段代码从给定原始页面访问量数据集中,计算出每个URL的页面访问量。这段代码比较有意思的是,像调度、合并结果集、处理运行时错误(像机器宕机)等的并发问题都处理好了。因为这样写的算法,可以自动在MapReduce集群上分布,可扩展至任意多的可用节点。因此,如果MapReduce集群上有10个节点,它可以比一个节点快10倍。计算的最后,输出目录会包括很多的结果文件。
Serving layer
The batch layer emits batch views as the result of its functions. The next step is to load the views somewhere so that they can be queried. This is where the serving layer comes in. For example, your batch layer may precompute a batch view containing the pageview count for every [url,hour] pair. That batch view is essentially just a set of flat files though:there’s no way to quickly get the value for a particular URL out of that output.
批处理层实现了功能的批处理视图,下一步就是把把数据加载到什么地方以供查询,这就是服务层的由来。比如,批处理层计算出了包含每个[url, hour]数的批处理视图,批处理视图本质上只是一些平面文件,没有办法从中很快得到特定URL的值。
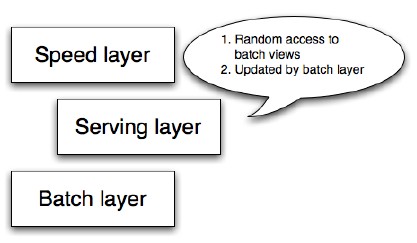
Figure 5 – Serving layer
The serving layer indexes the batch view and loads it up so it can be efficiently queried to get particular values out of the view. The serving layer is a specialized distributed database that loads in batch views,makes them queryable, and continuously swaps in new versions of a batch view as they’re computed by the batch layer. Since the batch layer usually takes at least a few hours to do an update, the serving layer is updated every few hours.
服务层索引了批处理视图所以可以从中非常高效的得到特定的值。服务层是实现了加载批处理视图,使它们可查询,并且在批处理视图新版本进入时持续切换的分布式数据库。批处理层通常需要几个小时做更新,因此服务层也是每隔几个小时更新一次。
A serving layer database only requires batch updates and random reads. Most notably, it does not need to support random writes. This is a very important point because random writes cause most of the complexity in databases. By not supporting random writes, serving layer databases can be very simple. That simplicity makes them robust, predictable, easy to configure, and easy to operate.ElephantDB, a serving layer database,is only a few thousand lines of code.
服务层数据库只需要满足批量自新和随机读,显然它不需要支持随机写,这是个非常重要的观点因为随机写导致了大部分数据库的复杂性。因此不支持随机写,服务层数据库可以非常简单。这些简单性使得它们健壮、可预测、配置简单、并且容易操作。ElephantDB,一个服务层数据库,只有仅仅几千行代码。
Batch and serving layers satisfy almost all properties
So far you’ve seen how the batch and serving layers can support arbitrary queries on an arbitrary dataset with the trade off that queries will be out of date by a few hours. The long update latency is due to the fact that new pieces of data take a few hours to propagate through the batch layer into the serving layer where it can be queried.
到目前为止,你知道批处理层和服务层如何支持在任意数据集上进行任意查询与查询过时数小时间进行折衷。高延迟是因为新数据从进入批处理层到查询的服务层需要花费数小时。
The important thing to notice is that, other than low latency updates, the batch and serving layers satisfy every property desired in a Big Data system. Let’s go through them one by one:
需要注意到的重要事是,除了低延迟的更新,批处理和服务层可以满足大数据系统的所有要求的特性。我们就一个个的过:
* Robust and fault tolerant: The batch layer handles failover when machines go down using replication and restarting computation tasks on other machines. The serving layer uses replication under the hood to ensure availability when servers go down. The batch and serving layers are also human fault tolerant,since, when a mistake is made, you can fix your algorithm or remove the bad data and recompute the views from scratch.
健壮性和容错性:批处理层通过复制和在其他服务器上重启计算任务来处理机器宕机。服务层通过复制确保服务器宕机时可用。批处理和服务层也是人类行为容错的,当一个错误发生时,可以通过修改算法或者移除坏数据然后从头重新计算解决。
* Scalable—Both the batch layer and serving layers are easily scalable. They can both be implemented as fully distributed systems, where upon scaling them is as easy as just adding new machines.
可扩展性:批处理层和服务都可以很简单的扩展,他们都是完全实现的分布式系统,仅仅通过简单的增加机器即可扩展。
* General—The architecture described is as general as it gets. You can compute and update arbitrary views of an arbitrary dataset.
通用性:描述的架构就像刚提到的那样通用,你可以计算并在任意数据上更新任意视图
* Extensible—Adding a new view is as easy as adding a new function of the master dataset. Since the master dataset can contain arbitrary data, new types of data can be easily added. If you want to tweak a view, you don’t have to worry about supporting multiple versions of the view in the application. You can simply recompute the entire view from scratch.
可扩充性:添加一个新的视图就像在原始数据上添加一个函数一样简单。因为原始数据包括任意的数据,新的数据类型可以容易的添加。如果你想更改一个视图,不用担心在程序中实现此视图的多版本,你可以简单的从头计算整个视图。
* Allows ad hoc queries—The batch layer supports ad-hoc queries innately. All of the data is conveniently available in one location and you’re able to run any function you want on that data.
允许即席查询:批处理层天生支持即席查询。所有的数据在一个地点方便可用,你可以在那些数据上执行任意你想执行的函数。
* Minimal maintenance—The batch and serving layers consist of very few pieces,yet they generalize arbitrarily. So, you only have to maintain a few pieces fora huge number of applications. As explained before, the serving layer databases are simple because they don’t do random writes. Since a serving layer database has so few moving parts, there’s lots less that can go wrong. As a consequence,it’s much less likely that anything will go wrong with a serving layer database, so they are easier to maintain.
最少维护:批处理层和服务层只有很少的部分组成,以此类推。因此很多的应用也只需要维护一小部分。像前面解释的那样,服务器数据库因为没有随机写而非常简单。服务层数据库几乎没有可移动部分,也就很少出错,结果是服务层数据库没有东西会出错,因此非常容易维护。
* Debuggable—You will always have the inputs and outputs of computations run on the batch layer. In a traditional database, an output can replace the original input—for example, when incrementing a value. In the batch and serving layers,the input is the master dataset and the output is the views. Likewise, you have the inputs and outputs for all of the intermediate steps. Having the inputs and outputs gives you all the information you need to debug when something goes wrong.
可调试:在批处理层上的计算总是同时拥有输入和输出。在传统的数据库中,输出可能覆盖输入,比如一个值自增。在批处理层和服务层,输入是主数据集输出是视图。同样的,所有的中间步骤数据也是有的。有输入与输出,当出错时你就拥有足够的信息去调试。
The beauty of the batch and serving layers is that they satisfy almost all of the properties you want with a simple and easy to understand approach. There are no concurrency issues to deal with, and it scales trivially. The only property missing is low latency updates. The final layer, the speed layer, fixes this problem.
批处理层和服务层非常好的地方是你想要的所有的特性都以一种简单、容易理解的方式满足了,没有并发性需要处理,并且没有扩展细节。唯一缺失的地方是低延迟更新,在最后一层,即高速层,解决这个问题。
Speed layer
The serving layer updates whenever the batch layer finishes precomputing a batch view. This means that the only data not represented in the batch views is the data that came in while the precomputation was running. All that’s left to do to have a fully realtime data system—that is, arbitrary functions computed on arbitrary data in real time—is to compensate for those last few hours of data. This is the purpose of the speed layer.
当批处理层完成批处理视图后才更新服务层,这也意味着在批处理层唯一不能展现的是正在计算部分。剩下的就交给实时数据系统了,它可以在任意数据集上实时的执行任意计算,它正好弥补最后几小时的数据。这也正是高速层的目的。
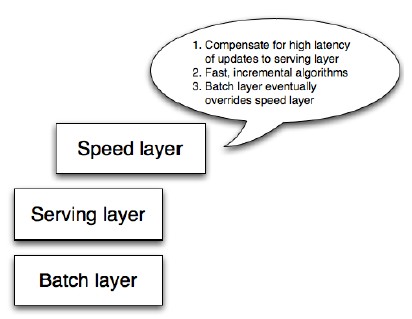
Figure 6 – Speed layer
You can think of the speed layer as similar to the batch layer in that it produces views based on data it receives. There are some key differences, though. One big difference is that, in order to achieve the fastest latencies possible, the speed layer doesn’t look at all the new data at once. Instead, it updates the realtime view as it receives new data instead of recomputing them like the batch layer does. This is called incremental updates as opposed to recomputation updates. Another big difference is that the speed layer only produces views on recent data, whereas the batch layer produces views on the entire dataset.
你可以认为高速层跟批处理层类似也是数据来了生成视图。他们之间也有一些关键点不同,其中一个不同的是,为了尽可能低的延迟得到数据,高速层不会查找所有的新数据,而是当新数据平时更新实时视图,而不是像批处理层那样计算,与重新计算更新相反这是增量更新。另一个很大不同点是高速层只在最近的数据生成视图,而处理层是在所有数据上生成视图。
Let’s continue the example of computing the number of pageviews for a URL over a range of time. The speed layer needs to compensate for pageviews that haven’t been incorporated in the batch views, which will bea few hours of pageviews. Like the batch layer, the speed layer maintains a view from a key [url, hour] to a pageview count. Unlike the batch layer, which recomputes that mapping from scratch each time, the speed layer modifies its view as it receives new data.
我们继续以计算一个URL的PV数为例。高速层需要用几个小时的PV数并入进来来弥补批处理层。同批处理层一样,高速层维护一个[url,hour]PV数的视图,不同的是,批处理层每次都是从头映射,而高速层则接收到新数据后更新视图。
When it receives a new pageview, it increments the count for the corresponding[url, hour]in the database.
当接收到新PV,则增加数据库中对应的[url,hour]数。
The speed layer requires databases that support random reads and random writes. Because these databases support random writes, they are orders of magnitude more complex than the databases you use in the serving layer, both in terms of implementation and operation.
高速层需要支持随机读和随机写的数据数据库。因为数据库支持随机写,无论是实现还是操作他们都比服务层用的数据库复杂几个数量级。
The beauty of the lambda architecture is that, once datamakes it through the batch layer into the serving layer, the correspondingresults in the realtime views. Thismeans you can discard pieces of the are no longer needed realtime view asthey’re no longer needed. This is a wonderful result, since the speed layer isway more complex than the batch and serving layers. This property of the lambdaarchitecture is called complexity isolation, meaning that complexity is pushedinto a layer whose results are only temporary. If anything ever goes wrong, youcan discard the state for entire speed layer and everything will be back tonormal within a few hours. This property greatly limits the potential negativeimpact of the complexity of the speed layer.
Lambda架构优美的地方在于,一旦数据通过批处理层进到服务层,与实时视图的结果是一致的,也就意味着当实时视图不需要时可以随时丢弃。这是个极好的结果,因为高速层处理方式比批处理层和服务层复杂得多。Lambda架构的这个特别被为复杂隔离,也就是复杂性放在一层而且他的结果是临时的。如果有任何异常,你可以丢弃整个高速层并且任何事都可以在几小时内回归正常。这个特性极大的限制性了高速层复杂性的副面影响。
The last piece of the lambda architecture is merging theresults from the batch and realtime views to quickly compute query functions.For the pageview example, you get the count values for as many of the hours inthe range from the batch view as possible. Then, you query the realtime view toget the count values for the remaining hours. You then sum up all theindividual counts to get the total number of pageviews over that range. There’sa little work that needs to be done to get the synchronization right betweenthe batch and realtime views. The pattern of merging results from the batch andrealtime views is shown in figure 7.
Lambda架构的最后一点是把批处理层和实时层视图快速查询的结果进行合并。以pv为例,你尽可能的从批处理视图得到更多区间小时数的次数,然后你从实时视图中得到其余小时的次数。然后你汇总所有单独的次数得到一段区间内的pv数。需要做一点工作以使批处理视图和实时视图同步。从批处理和实时视图同步的示意图如figure 7.
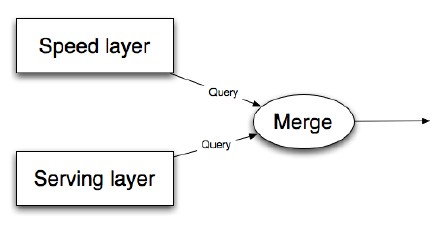
Figure 7 – Satisfying application queries
We’ve covered a lot of material in the past few sections.Let’s do a quick summary of the lambda architecture to nail down how it works.
过去几章我们列举了很多特性。我们快速总结下lamdba架构是如何工作的。
Summary
The complete lambda architecture is represented in figure8.
完整的lambda架构如figure 8所示
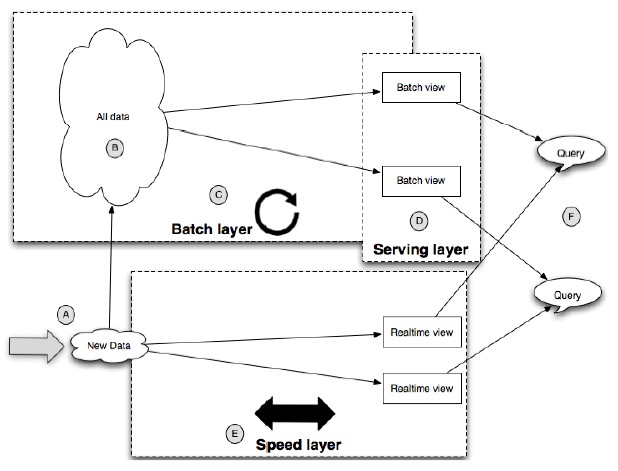
Figure 8 – Lambda architecture diagram
Let’s go through the diagram piece by piece.
我们逐步讲解示意图
* (A)—All new data is sent to both the batch layer and the speed layer. In thebatch layer, new data is appended to the master dataset. In the speed layer,the new data is consumed to do incremental updates of the realtime views.
* (A)—所有新数据都同时发送到批处理层和高速层。批处理层中,新数据被追加到原始数据集中,而在高速层中,新数据被实时视图的增量更新所消耗。
* (B)—The master dataset is an immutable, append-only set of data. The masterdataset only contains the rawest information that is not derived from any otherinformation you have.
* (B)—原始数据集是稳定的、只追加的数据集。原始数据集只包含了没有经过任何加工的原始信息。
* (C)—The batch layer precomputes query functions from scratch. The results ofthe batch layer are called batch views. The batch layer runs in a while(true)loop and continuously recomputes the batch views from scratch. The strength ofthe batch layer is its ability to compute arbitrary functions on arbitrarydata. This gives it the power to support any application.
* (C)—批处理层从头重新计算查询功能,批处理层的结果叫批处理视图。批处理层运行一个while(true)循环持续从头计算批处理视图。批处理层的长处在于它有能力从任意数据集中进行任意的计算,因此它有能力支持任何应用。
* (D)—The serving layer indexes the batch views produced by the batch layer andmakes it possible to get particular values out of a batch view very quickly.The serving layer is a scalable database that swaps in new batch views asthey’re made available. Because of the latency of the batch layer, the resultsavailable from the serving layer are always out of date by a few hours.
* (D)—服务层索引批处理层产生的批处理视图使得可以非常迅速的从批处理视图中得到特定的值。服务层是个可以在新的批处理视图可用时进行交换的可扩展数据库。因为批处理的高时延,从服务层得到的结果总是几个小时前的数据。
* (E)—The speed layer compensates for the high latency of updates to theserving layer. It uses fast incremental algorithms and read/write databases toproduce realtime views that are always up to date. The speed layer only dealswith recent data, because any data older than that has been absorbed into thebatch layer and accounted for in the serving layer. The speed layer issignificantly more complex than the batch and serving layers, but thatcomplexity is compensated by the fact that the realtime views can becontinuously discarded as data makes its way through the batch and servinglayers. So, the potential negative impact of that complexity is greatlylimited.
* (E)—高速层做为服务导高延迟更新的补充,它使用快速增量算法和读写数据库以生成实时视图。高速层中处理最近的数据,因为老的数据都入了批处理层可以计算生成服务层。高速层比批处理和服务层都明显复杂,但是当批处理和服务层数据可用时高速层视图可以被丢弃从而减少了其复杂性。因此,其潜在的副面影响大大的减少了。
* (F)—Queries are resolved by getting results from both the batch and realtimeviews and merging them together.
* (F)—查询结果由批处理和实时视图合并得到。
Related Content:
- From Big Data to Big Information
- Introduction to Hadoop Big Data
- Manage Large Datasets with Python and HDF5















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









