







什么是TOAST呢?先抛出一个概念解释:TOAST是The Oversized-Attribute Storage Technique的缩写,直译比较难理解,我们这里叫行外存储技术。因为在PostgreSQL中,一条记录不能跨PAGE存储,毕竟默认一个PAGE只有8K,不能存储很大的值,所以存储大字段的值,就使用TOAST存储。它和原表的数据是分开存储的。TOAST存储的表并不能单独创建,只有当普通表包含了main,extended或external存储格式的字段时,系统会自动创建一个和普通表关联的TOAST表。当一行记录(tuple)存储的(包括压缩后的大小)大小超过TOAST_TUPLE_THRESHOLD(默认2K)时,会存储到TOAST表。
源码相关:
检查是否需要TOAST存储的函数在src/backend/catalog/toasting.c
/*
* Check to see whether the table needs a TOAST table. It does only if
* (1) there are any toastable attributes, and (2) the maximum length
* of a tuple could exceed TOAST_TUPLE_THRESHOLD. (We don't want to
* create a toast table for something like "f1 varchar(20)".)
* No need to create a TOAST table for partitioned tables.
*/
static bool
needs_toast_table(Relation rel)
{
int32 data_length = 0;
bool maxlength_unknown = false;
bool has_toastable_attrs = false;
TupleDesc tupdesc;
int32 tuple_length;
int i;
if (rel->rd_rel->relkind == RELKIND_PARTITIONED_TABLE)
return false;
tupdesc = rel->rd_att;
for (i = 0; i < tupdesc->natts; i++)
{
Form_pg_attribute att = TupleDescAttr(tupdesc, i);
if (att->attisdropped)
continue;
data_length = att_align_nominal(data_length, att->attalign);
if (att->attlen > 0)
{
/* Fixed-length types are never toastable */
data_length += att->attlen;
}
else
{
int32 maxlen = type_maximum_size(att->atttypid,
att->atttypmod);
if (maxlen < 0)
maxlength_unknown = true;
else
data_length += maxlen;
if (att->attstorage != 'p')
has_toastable_attrs = true;
}
}
if (!has_toastable_attrs)
return false; /* nothing to toast? */
if (maxlength_unknown)
return true; /* any unlimited-length attrs? */
tuple_length = MAXALIGN(SizeofHeapTupleHeader +
BITMAPLEN(tupdesc->natts)) +
MAXALIGN(data_length);
return (tuple_length > TOAST_TUPLE_THRESHOLD);
}
TOAST_TUPLE_THRESHOLD定义在src/include/access/tuptoaster.h,
#define TOAST_TUPLES_PER_PAGE 4
#define TOAST_TUPLE_THRESHOLD MaximumBytesPerTuple(TOAST_TUPLES_PER_PAGE)
#define TOAST_TUPLE_TARGET TOAST_TUPLE_THRESHOLD
#define
MaximumBytesPerTuple(tuplesPerPage) \
MAXALIGN_DOWN((BLCKSZ - \
MAXALIGN(SizeOfPageHeaderData + (tuplesPerPage) * sizeof(ItemIdData))) \
/ (tuplesPerPage))
#当BLCKSZ为8KB
MAXALIGN_DOWN((8192 - MAXALIGN(192 + (4) * 32)) / (4)) ~=2KB
#当数据库修改BLCKSZ为32KB
MAXALIGN_DOWN((32768 - MAXALIGN(192 + (4) * 32)) / (4)) ~= 8KB
对应存储类型的缩写定义在src/backend/commands/tablecmds.c
/*
* storage_name
* returns the name corresponding to a typstorage/attstorage enum value
*/
static const char *
storage_name(char c)
{
switch (c)
{
case 'p':
return "PLAIN";
case 'm':
return "MAIN";
case 'x':
return "EXTENDED";
case 'e':
return "EXTERNAL";
default:
return "???";
}
}
--可以通过 select typname,typstorage from pg_type查看
存储策略如下:
- PLAIN
不允许压缩和线外存储。对于那些不能TOAST机制的数据类型,默认都是该策略,比如整数类型(INT,SMALLINT,BIGINT)、字符类型(CHAR)、布尔类型(BOOLEAN)等等。 - EXTENDED
允许线外存储和压缩。这是大多数可以使用TOAST机制的数据类型默认存储策略。它首先尝试压缩,如果这仍不能将数据放入页中,则使用线外存储。 - EXTERNAL
允许线外存储,但不允许压缩。该存储策略将使TEXT、BYTEA数据类型的列中字符串操作更快,其代价是牺牲存储空间。 - MAIN
允许压缩,但不能线外存储。然而在无法使列足够小以存入页时,它还是执行线外存储。所以它仍然是可以行外存储的,和EXTERNAL具有相似性。
存储策略PLAIN、EXTENDED、EXTERNAL和MAIN在PostgreSQL源码中分别被简写为p、x、e和m。通过storage_name函数,分别获取个存储策略所对应的名字。
举例说明:
创建表,并查看列存储策略
hank=> create table tbl_test_toast (id int primary key,name varchar(50),info text,age int);
CREATE TABLE
hank=> \d+ tbl_test_toast
Table "hank.tbl_test_toast"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | character varying(50) | | | | extended | |
info | text | | | | extended | |
age | integer | | | | plain | |
Indexes:
"tbl_test_toast_pkey" PRIMARY KEY, btree (id)
Access method: heap
#修改字段类型的存储策略
alter table tablename alter column {$column_name} set storage { PLAIN | MAIN | EXTERNAL | EXTENDED } ;
插入一行数据,查看是否使用TOAST存储
hank=> insert into hank.tbl_test_toast values (1,'hank','51.2. Index Access Method FunctionsThe index construction and maintenance functions that an index access method must provide are:IndexBuildResult *ambuild (Relation heapRelation, Relation indexRelation, IndexInfo *indexInfo);Build a new index. The index relation has been physically created, but is empty. It must be filled in with whatever fixed data the access method requires, plus entries for all tuples already existing in the table. Ordinarily the ambuild function will call IndexBuildHeapScan() to scan the table for existing tuples and compute the keys that need to be inserted into the index. The function must return a pallocd struct containing statistics about the new index.boolaminsert (Relation indexRelation, Datum *values, bool *isnull, ItemPointer heap_tid, Relation heapRelation, IndexUniqueCheck checkUnique);Insert a new tuple into an existing index. The values and isnull arrays give the key values to be indexed, and heap_tid is the TID to be indexed. If the access method supports unique indexes (its pg_am.amcanunique flag is true) then checkUnique indicates the type of uniqueness check to perform. This varies depending on whether the unique constraint is deferrable; see Section 51.5 for details. Normally the access method only needs the heapRelation parameter when performing uniqueness checking (since then it will have to look into the heap to verify tuple liveness).The functions Boolean result value is significant only when checkUnique is UNIQUE_CHECK_PARTIAL. In this case a TRUE result means the new entry is known unique, whereas FALSE means it might be non-unique (and a deferred uniqueness check must be scheduled). For other cases a constant FALSE result is recommended.Some indexes might not index all tuples. If the tuple is not to be indexed, aminsert should just return without doing anything.IndexBulkDeleteResult *ambulkdelete (IndexVacuumInfo *info, IndexBulkDeleteResult *stats, IndexBulkDeleteCallback callback, void *callback_state);Delete tuple(s) from the index. This is a "bulk delete" operation that is intended to be implemented by scanning the whole index and checking each entry to see if it should be deleted. The passed-in callback function must be called, in the style callback(TID, callback_state) returns bool, to determine whether any particular index entry, as identified by its referenced TID, is to be deleted. Must return either NULL or a pallocd struct containing statistics about the effects of the deletion operation. It is OK to return NULL if no information needs to be passed on to amvacuumcleanup.Because of limited maintenance_work_mem, ambulkdelete might need to be called more than once when many tuples are to be deleted. The stats argument is the result of the previous call for this index (it is NULL for the first call within a VACUUM operation). This allows the AM to accumulate statistics across the whole operation. Typically, ambulkdelete will modify and return the same struct if the passed stats is not null.IndexBulkDeleteResult *amvacuumcleanup (IndexVacuumInfo *info, IndexBulkDeleteResult *stats);Clean up after a VACUUM operation (zero or more ambulkdelete calls). This does not have to do anything beyond returning index statistics, but it might perform bulk cleanup such as reclaiming empty index pages. stats is whatever the last ambulkdelete call returned, or NULL if ambulkdelete was not called because no tuples needed to be deleted. If the result is not NULL it must be a pallocd struct. The statistics it contains will be used to update pg_class, and will be reported by VACUUM if VERBOSE is given. It is OK to return NULL if the index was not changed at all during the VACUUM operation, but otherwise correct stats should be returned.As of PostgreSQL 8.4, amvacuumcleanup will also be called at completion of an ANALYZE operation. In this case stats is always NULL and any return value will be ignored. This case can be distinguished by checking info->analyze_only. It is recommended that the access method do nothing except post-insert cleanup in such a call, and that only in an autovacuum worker process.voidamcostestimate (PlannerInfo *root, IndexOptInfo *index, List *indexQuals, RelOptInfo *outer_rel, Cost *indexStartupCost, Cost *indexTotalCost, Selectivity *indexSelectivity, double *indexCorrelation);Estimate the costs of an index scan. This function is described fully in Section 51.6, below.bytea *amoptions (ArrayType *reloptions, bool validate);',30);
INSERT 0 1
hank=> SELECT relname FROM pg_class WHERE oid = (SELECT reltoastrelid FROM pg_class WHERE relname = 'tbl_test_toast');
relname
----------------
pg_toast_57272
hank=# select oid,relname,reltoastrelid from pg_class where relname='tbl_test_toast';
oid | relname | reltoastrelid
-------+----------------+---------------
57272 | tbl_test_toast | 57275
hank=# select pg_column_size(info) from hank.tbl_test_toast;
pg_column_size
----------------
2485
#注意这里是存储策略是EXTENDED,所以会压缩,压缩后,如果大小还是超过2KB,才会存储到toast,所以做实验的时候可以修改存储策略为EXTERNAL,这样可以更容易的达到实验目的,如修改为EXTERNAL,直接插入repeat('a', 2100)大小的值,就会启用TOAST,因为2104已经大于TOAST_TUPLE_THRESHOLD(2KB)。
select pg_column_size(repeat('a', 2100));
pg_column_size
----------------
2104
(1 row)
对于TOAST表的命名,规则是:pg_toast_$(oid)。其中oid是该TOAST表所属表的oid值,比如数据表tbl_test_toast在系统表pg_class中的oid是57272,所以与之关联的TOAST的表名字是pg_toast_57272。
如下图示:info字段使用TOAST存储
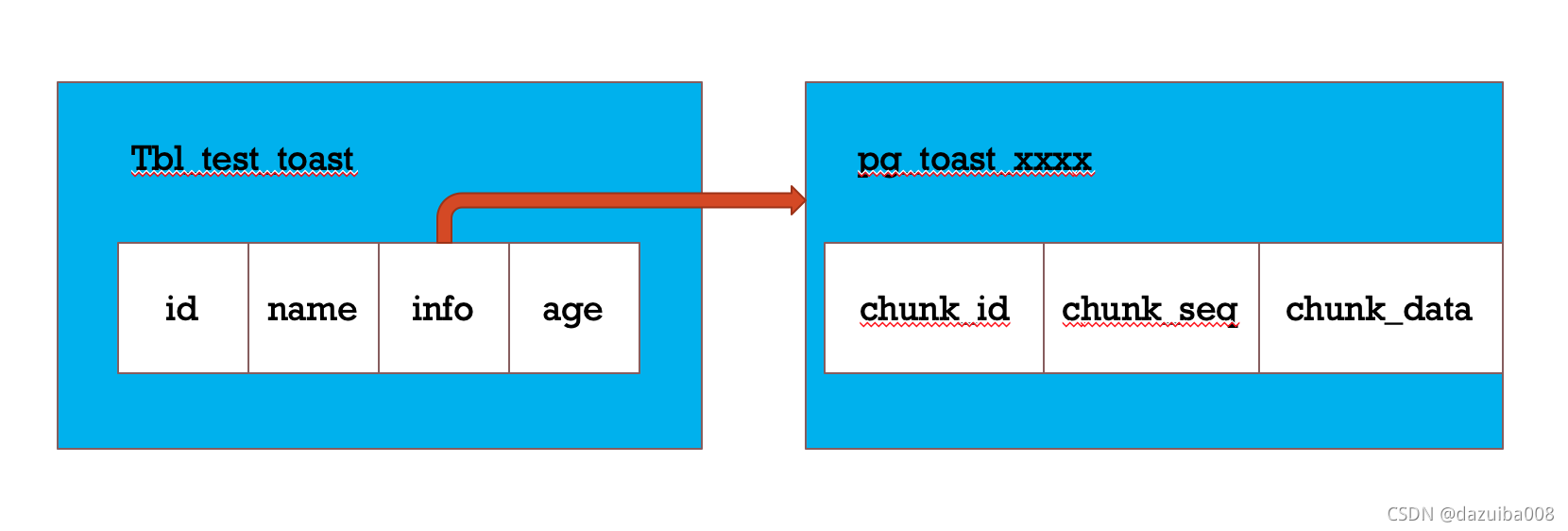
#可见chunk_id, chunk_seq组成了主键
hank=# \d pg_toast.pg_toast_57272
TOAST table "pg_toast.pg_toast_57272"
Column | Type
------------+---------
chunk_id | oid
chunk_seq | integer
chunk_data | bytea
Owning table: "hank.tbl_test_toast"
Indexes:
"pg_toast_57272_index" PRIMARY KEY, btree (chunk_id, chunk_seq)
chunk_id: 该toast表所分配的oid
chunk_seq: chunk的序列号
chunk_data: chunk中的数据
hank=# SELECT chunk_id, COUNT(*) as chunks, pg_size_pretty(sum(octet_length(chunk_data)::bigint))FROM pg_toast.pg_toast_57272 GROUP BY 1 ORDER BY 1;
chunk_id | chunks | pg_size_pretty
----------+--------+----------------
57284 | 2 | 2485 bytes
#因为这个值太大了,不能放在一行中,所以PostgreSQL把它分成了两个块存放。
使用TOAST的好处如下:
-
UPDATE一个普通表时,当该表的TOAST表存储的列没有修改时,TOAST表不需要更新,这样更新效率得到提升
-
由于TOAST在物理存储上和普通表分开,所以当SELECT时没有查询被TOAST的列数据时,不需要把这些TOAST的PAGE加载到内存,从而加快了检索速度并且节约了使用空间。
-
在排序时,由于TOAST和普通表存储分开,当针对非TOAST字段排序时大大提高了排序速度。
使用TOAST存储格式注意事项:
-
当变长字段上需要使用索引时,权衡CPU和存储的开销,考虑是否需要压缩或非压缩存储。(压缩节约磁盘空间,但是带来CPU的开销)
-
对于经常要查询或UPDATE的变长字段,如果字段长度不是太大,可以考虑使用MAIN存储。
-
在超长字段,或者将来会插入超长值的字段上建索引的话需要注意,因为索引最大不能超过三分之一的PAGE,所以超长字段上可能建索引不成功,或者有索引的情况下,超长字段插入值将不成功。解决办法一般可以使用MD5值来建,当然看你的需求了。
参考:
https://hakibenita.com/sql-medium-text-performance
https://github.com/digoal/blog/blob/master/201103/20110329_01.md
https://www.postgresql.org/docs/13/storage-toast.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









