







Standalone模式下Spark 中通信机制的源码分析
索引
- 前提要求
- 粗略概要
- 详细实现
- 资料获取
- 总结
正文
前提要求
看本博文前要掌握scala基础语言,这个网上有很多免费下载的资料。应该很容易获取。再就是需要有spark内部架构,机制的理解。链接:[(http://blog.sina.com.cn/s/blog_4d1426660102v5u2.html)]粗略概要
首先,spark内的通信机制是使用akka完成的,该框架是一个用 Scala 编写的库,用于简化编写容错的、高可伸缩性的 Java 和 Scala 的 Actor 模型应用。Standalone模式下存在的角色:
Client:负责提交作业到Master。
Master:接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
Worker:负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,比如启动Driver和Executor。
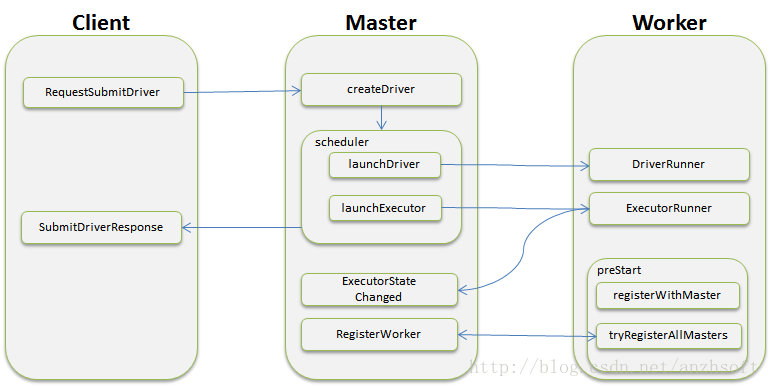
原理图如下:
然而:事实上,Master和Worker要处理的消息要比这多得多,本图只是反映了集群启动和向集群提交运算时候的主要消息处理。- 详细实现
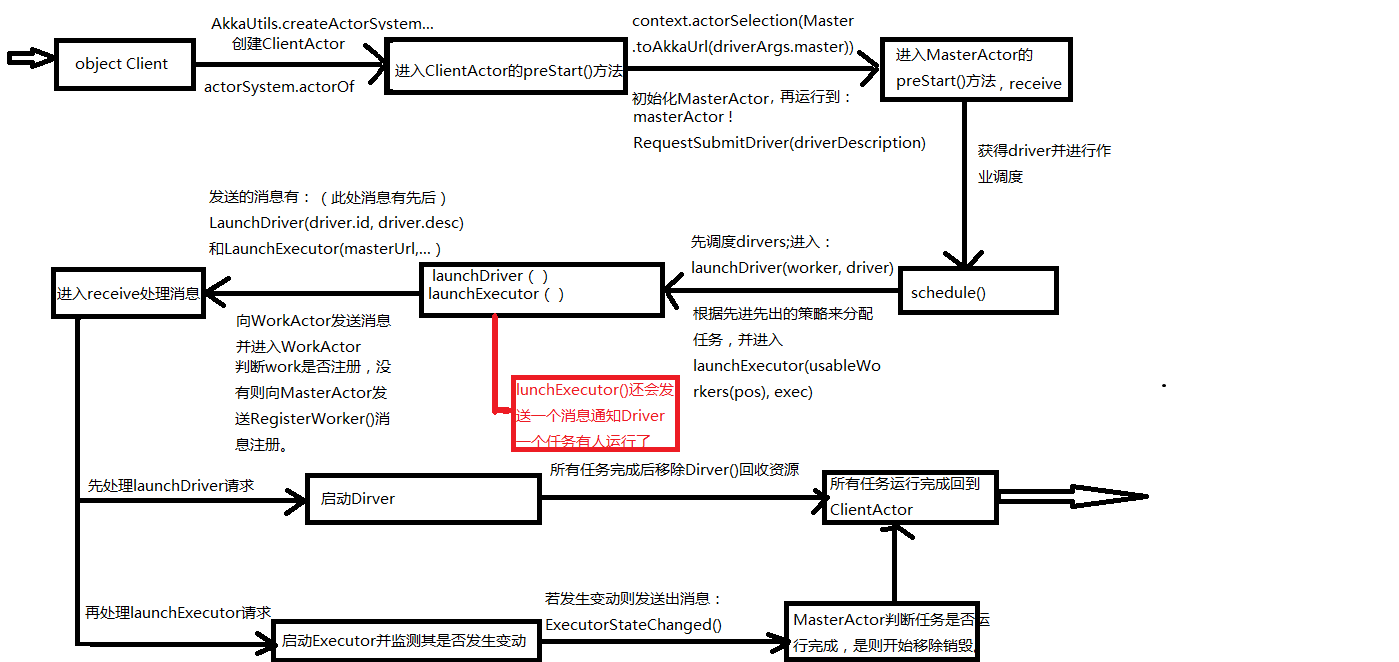
源码位置:spark-1.0.0\core\src\main\scala\org\apache\spark\deploy。主要涉及的类:Client.scala, Master.scala和Worker.scala。程序从client进入后的详细走向:
注:该图最好配合着源码分析,且在最后销毁Executor和Dirver的过程没有详细给出。
主要有:
ClientActor:主要做了设置master的连接地址,最后提交了一个RequestSubmitDriver的信息。在receive方法里面,就是等待接受回应了,有两个Response分别对应着这里的launch和kill。
MasterActor:更改自身的状态(RecoveryState),作业调度schedule()(
调度器是这样的,先调度Driver程序,然后再调度App,调度App的方式是从各个worker的里面和App进行匹配,看需要分配多少个cpu)
WorkActor:注册Work(注册成功后开始适时的发送心跳),启动Dirver和Executor 资料获取
这篇博文的写出主要靠以下资料:总结
这些东西看了后自己理一下,写写博客确实有收获啊!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









