







深度学习面经总结
- 距离度量方法
- 聚类算法
- kmeans聚的是特征还是样本?特征的距离如何计算?
- 为什么在高维空间中,欧式距离的度量逐渐失效?
- 怎么确定聚类数量K
- k-means的缺点,怎么解决
- dbscan和optics是怎么解决这些缺点的?
- 为什么在一些场景中要使用余弦相似度而不是欧式距离
- keamns, GMM, EM之间有什么关系
- 高斯混合模型的核心思想是什么?
- GMM是如何迭代计算的?
- 模型的loss function, metrics和optimizers
- ROC曲线和PR曲线的区别,适用场景,各自优缺点
- AUC的意义,AUC的计算公式
- 多分类auc怎么算
- 小目标、小样本检测
- 不平衡问题的解决方案
- Sigmoid与softmax
- Swish、Mish
- anchor based和anchor free
- 手撕代码篇
- yolo系列的区别
- 用过蒸馏吗
- 同步BN,异步BN
- 多卡GPU用过吗?梯度最后是如何更新的
- 数据增强的方法
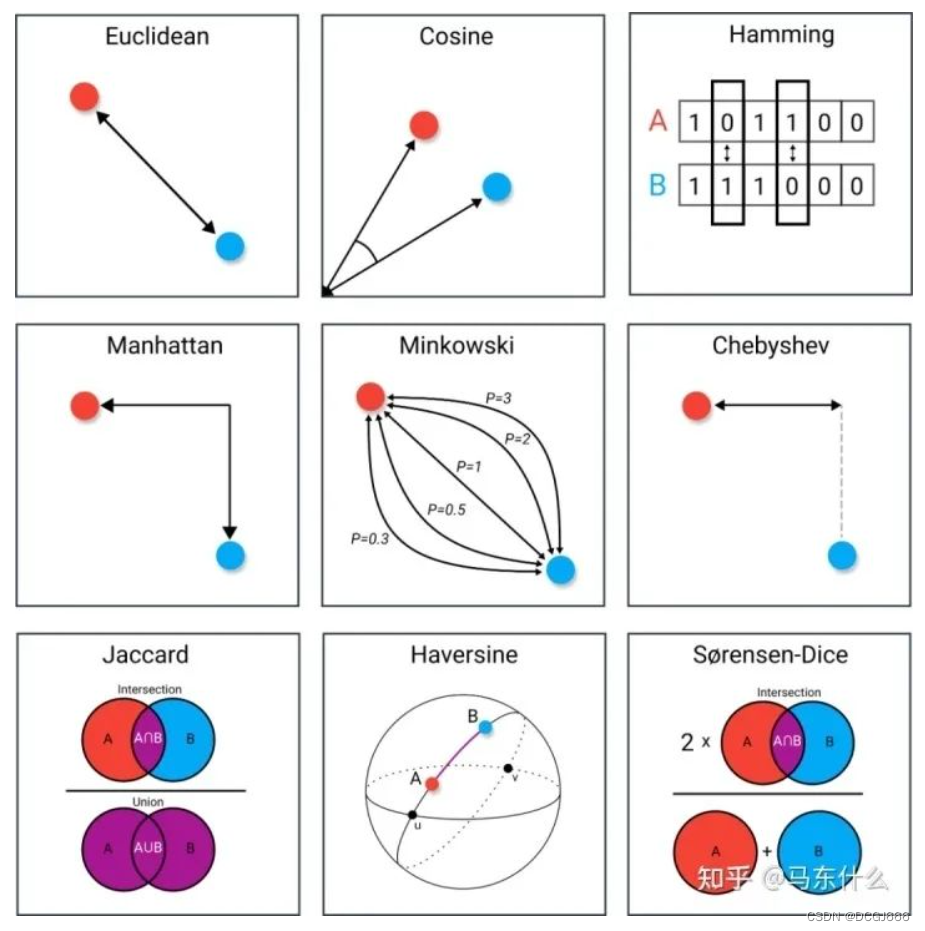
距离度量方法
- 欧式距离
- 余弦距离
- 汉明距离
- 曼哈顿距离
- 闵可夫斯基距离簇
- 切比雪夫距离
- Jaccard(Iou)距离
- Haversine距离
- S-Dice距离
聚类算法
简单回答,基于划分,基于密度,基于网络,层次聚类,除此之外聚类和其他领域也有很多的结合形成的交叉领域比如半监督聚类,深度聚类,集成聚类等等。
kmeans的原理
kmeans是一种基于划分的聚类,中心思想很简单,类内距离尽量小,类间距离尽量大,算法过程为:
- 初始化k个质心,作为初始的k个簇的中心点,k为人工设定的超参数;
- 所有样本点n分别计算和k个质心的距离,这里的距离也是人工定义的可以是不同的距离计算方法,每个样本点和k个质心中最近的质心划分为1类簇;
- 重新计算质心,方法是针对簇进行聚合计算,kmeans中使用简单平均的方法进行聚合计算法,也可以使用中位数等方式进行计算;
- 重复上述过程直到达到预定的迭代次数或质心不再发生明显变化
kmeans的损失函数
S
S
E
=
∑
k
=
1
K
∑
p
∈
C
k
∣
p
−
m
k
∣
2
SSE=\sum_{k=1}^K\sum_{p\in{C_k}}|p-m_k|^2
SSE=k=1∑Kp∈Ck∑∣p−mk∣2
其中,K是聚类数量,p是样本,
m
k
m_k
mk是第k个聚类的中心点。SSE越小,说明样本聚合程度越高。
kmeans的初始点怎么选择?不同的初始点选择策略有哪些缺陷?
- 随机初始化:随机选择k个样本点作为初始质心,缺陷在于如果选择到的质心距离很接近落早同一个簇内,则迭代的结果可能比较差,因为最终迭代出来的质心点会落在簇间
- 随机分取初始化:即将所有样本点随机赋予1个簇的编号,则所有样本点最后会有k个编号,然后进行组平均,即对于同一个簇的样本进行平均得到初始化质心。相对于随机初始化,初始的质心会更鲁棒一些,但是仍然存在随机初始化的缺陷,仅仅是缓解
- kmeans++: 首先从数据集中随机选取一个样本点作为第一个初始聚类中心
c
i
c_i
ci;接着计算每个样本与当前已有聚类中心之间的最短距离,用
D
(
x
)
D(x)
D(x)表示;然后计算每个样本带你被选为下一个聚类中心的概率
P
(
x
)
P(x)
P(x), 最后选择最大概率值所对应的样本点作为下一簇中心;
P ( x ) = D ( x ) 2 ∑ x ∈ X D ( x ) 2 P(x)=\frac{D(x)^2}{\sum_{x\in\mathcal{X}}D(x)^2} P(x)=∑x∈XD(x)2D(x)2
其实就是选择最短距离最大的样本点作为下一个初始化聚类中心点;
重复第2步,直到选择出k个聚类中心;
kmeans聚的是特征还是样本?特征的距离如何计算?
一般情况下是对样本聚类,如果对特征聚类则处理方式也简单,对原始的输入进行转置,其目的其实和做相关系数类似,如果两个特征高度相关,例如收入和资产水平,则两个特征的距离相对较小,但是一般不可行,因为转置之后,维度往往是非常高的,例如有100万个样本则有100万的维度,计算上不现实,高维数据的距离度量也是无效的,不如直接计算相关系数。
为什么在高维空间中,欧式距离的度量逐渐失效?
维度d趋于无穷大时,高维空间中任意两个样本点的最大距离和最小距离趋于相等,距离度量失效。
怎么确定聚类数量K
和评估分类或回归的方式一样,选择某个metric或某些metrics下最好的k,例如sse(其实就是kmeans的损失函数),轮廓系数,兰德系数,互信息;
如果聚类本身是为了有监督任务服务的,则可以直接根据下游任务的metrics进行评估更好;
k-means如何调优
- 初始化调参
- k的大小调参,手工方法,手肘法为代表
- 数据归一化和异常样本的处理
k-means的缺点,怎么解决
- 对异常样本很敏感,簇心会因为异常样本被拉得很远
这里的异常样本指的仅仅是在某些特征维度上取值特别大或者特别小的样本,是异常检测中定义的异常样本的一个子集,因为欧式距离的计算不考虑不同变量之间的联合分布,默认所有特征是相互独立的,所以kmeans中会对结果产生影响的异常样本特指简单的异常样本,即某些特征维度存在异常值的样本,这类异常样本通过简单的统计就可以得到。 - 只能拟合球性簇,对于流形簇等不规则的簇或是存在簇重叠问题的复杂情况等,效果较差
- 无法处理离散特征,缺失特征
- 无法保证全局最优
dbscan和optics是怎么解决这些缺点的?
dbscan和optics是基于密度的聚类
- kmeans对异常样本很敏感,簇心会因为异常样本被拉得很远
dbscan和optics定义了密度的计算方式,不涉及到任何的平均这种鲁棒性较差的计算方式,对异常样本不敏感,还能检测异常样本 - k值需要事先指定,有时候难以确定
dbscan和optics不需要指定簇的数量;算法迭代过程中自然而然产生最优的k个聚类簇; - 只能拟合球形簇,对于流形簇等不规则的簇或是存在簇重叠问题的复杂情况等,效果较差
基于密度的聚类可以拟合任意形状的簇,这也归功于密度的计算方式,基于密度的聚类本身不对聚类簇的形状有任何的假设
dbscan
设置一个搜索半径,以及最小的满足点,搜索过的点标记为已搜索,避免其他簇抢走该点。如果搜索半径内点的个数小于最小点阈值,则该点为噪声点。
optics
dbscan在不同超参数定义下得到的聚类结果差异很大,主要原因在于:不同簇的密度大小可能是不一样的,dbscan直接给定了半径eplison和min_points,实际上直接定义了最小密度,则密度较小的簇最终会被忽略掉了。
相对于dbscan多定义了核心距离和可达距离,核心距离就是核心点与第min_points个点的距离;可达距离就是样本点与核心点之间的距离。
如果该点的可达距离小于等于人工设定的半径R,则该点属于当前聚类簇;
如果该点的可达距离大于人工设定的半径R,则
- 如果该点的核心距离大于给定的半径R,则为噪声点;
- 如果该点的核心距离小于等于给定的半径R,则为新的聚类簇
为什么在一些场景中要使用余弦相似度而不是欧式距离
我们关注向量数值绝对差异,应当使用欧式距离,如果关心的是向量方向上的相对差异,则应当使用余弦距离。
keamns, GMM, EM之间有什么关系
kmeans是基于划分的聚类算法,GMM是基于模型的聚类算法,EM是估计GMM的参数使用的优化算法;
- kmeans可以看作是GMM的一种特例,于协方差为单位矩阵,故kmeans聚类的形状是球性的,而GMM是椭球型的
- kmeans使用hard EM求解,GMM使用soft EM求解
高斯混合模型的核心思想是什么?
GMM就是多个相关多元高斯分布的加权求和
GMM是如何迭代计算的?
首先需要了解EM算法,EM算法和梯度下降法一样,都可以用来优化极大似然函数,当极大似然函数中存在隐变量时,EM算法是一种常用的优化算法;
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以EM算法被称为EM算法。
模型的loss function, metrics和optimizers
无监督metrics:
S
S
E
=
∑
i
=
1
n
∑
j
=
1
m
w
(
i
,
j
)
=
∣
∣
x
(
i
)
−
μ
(
j
)
∣
∣
2
2
SSE=\sum_{i=1}^n\sum_{j=1}^mw^(i,j)=||x^{(i)}-\mu^{(j)}||^2_2
SSE=i=1∑nj=1∑mw(i,j)=∣∣x(i)−μ(j)∣∣22
μ
(
j
)
\mu^{(j)}
μ(j)表示j簇的中心。
轮廓系数:
轮廓系数是为每个样本定义的,由两个分数组成:
- a: 样本与同一cluster中所有其他点之间的平均距离。
- b: 样本与下一个最近cluster中的所有其他点之间的平均距离。
对于单个样本而言,轮廓系数的计算公式如下:
s = b − a m a x ( a , b ) s=\frac{b-a}{max(a,b)} s=max(a,b)b−a
对于模型评估而言,取所有样本的轮廓系数的均值作为模型聚类效果的评估指标。
有监督metrics:
准确率的局限性是什么? - 不同分类阈值下准确率会发生变化,评估起来比较麻烦;
- 对样本不均衡问题特别敏感,例如当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率;
- 公式:分类正确的样本数/总样本数
ROC曲线和PR曲线的区别,适用场景,各自优缺点
ROC曲线是纵坐标为准确率,横坐标为误检率
PR曲线是纵坐标为准确率,横坐标为召回率
ROC曲线对于正负样本比例不敏感,改变了标签中类别的分布之后,预测正确的正样本/预测正样本的样本数量 也会发生同向的变化,即roc的横坐标的计算结果是独立的,分别是针对正样本和针对负样本独立计算的,两个坐标的计算不会发生互相影响,因此类别比例发生变化的情况下,roc也不会产生剧烈的变动。
PR曲线的横纵坐标的计算结果是存在相互关系的,他们都是针对正样本进行计算,两个坐标的计算发生互相影响,从而使得PR曲线对类别的变化很敏感;
ROC聚焦于二分类模型整体对正负样本的预测能力,所以适用于评估模型整体的性能;如果主要关注正样本的预测能力而不care负样本的预测能力,则pr曲线更合适。
AUC的意义,AUC的计算公式
- auc是roc的曲线下面积,但是auc的实际意义仅仅从roc的曲线下面积不好理解,这里可以先了解一下auc的计算公式:
直接根据roc曲线进行计算,计算roc曲线下面积,缺点是计算误差较大。 - auc的实际意义:正负样本对中预测结果的rank值的比较,假设正样本有x1个,负样本有x0个,则统计正样本负样本的样本对中,正样本的预测概率大于负样本的预测概率的样本数量z,然后用z/x0x1就可以得到auc了。
多分类auc怎么算
多分类问题中,在二分类指标的基础上需要进行一些处理才能适配多分类的评估,整体有两种计算策略:
基于macro的策略:ovr的划分方式,分别计算每个类别的metrics然后再进行平均
基于micro的策略:所有类放在一起算metrics;
micro的评估方式,当类别非常不均衡时,micro的计算结果会被样本数量多的类别主导,此时需要使用macro
ks曲线的横坐标是分类的阈值,纵坐标代表了精确率或者误杀率,一个分类阈值对应的一个精确率和一个误杀率,而ks曲线就是用每个分类阈值下的精确率-误杀率,ks值则是指ks曲线上的最大值;
小目标、小样本检测
- 多尺度训练(图像金字塔,特征金字塔(BiFPN、FPN、NAS-FPN、PANet、SFF)),多尺度测试;
- 对于数据集中含有小目标图片较少的情况,使用过度采样的方式,即多次训练这类样本
- 将小物体在图片中复制多份,增加出现次数,在保证不影响其他物体的基础上,增加小物体在图片中出现的次数
- 设置合适的anchor size, 这样可提高proposal的准确率
- 对于分辨率很低的小目标,我们可以对其所在的proposal进行超分辨率,提升小目标的特征质量
- 显著性检测,先切割小图再检测
- 借鉴Cascade R-CNN的设计思路,优化目标检测中Two-Stage方法中的IOU阈值。检测中的IOU阈值对于样本的选取是至关重要的,如果IOU阈值过高,会导致正样本质量很高,但是数量会很少,会出现样本比例不平衡的影响;如果IOU阈值较低,样本数量就会增加,但是样本的质量也会下降。
不平衡问题的解决方案
通常针对类别不平衡问题可以从调整样本数或修改loss weight两方面取解决,常用的方法有OHEM,OHNM, class balanced loss和Focal loss;限制正负样本比例为1:1,如果正样本不足,就用负样本补充
- Online Hard Example Mining,OHEM。将所有sample根据当前loss排序,选出loss最大的N个,其余的抛弃。这个方法就只处理了easy sample的问题
- Online hard negative mining, OHNM, SSD里使用的一个OHEM变种,在Focal loss里代号为OHEM 1:3。在计算loss时,使用所有的positive anchor,使用OHEM选择3倍于positive anchor的negative anchor。同时考虑了类间平衡与easy sample.
- 重加权,Class balanced loss。计算loss时,正负样本上的loss分别计算,然后通过权重来平衡两者。只考虑了类间平衡。
- Focal loss, 难易样本上的loss权重是根据样本难度计算出来的。
- 重采样,对少样本过采样,对多样本欠采样
- 数据合成/增强,mixup copypaste
- label assignment, ATSS, 采用一些anchor free的方案
Sigmoid与softmax
对于二分类问题来说,理论上,两者是没有任何区别的。由于我们现在用的Pytorch、Tensorflow等框架计算矩阵方式的问题,导致两者在反向传播的过程中还是区别的。通常来说,二分类直接选用sigmoid。
Sigmoid函数:output(x1)=
1
1
+
e
−
x
1
\frac{1}{1+e^{-x_1}}
1+e−x11
Softmax函数:output(x1)=
e
x
1
e
x
1
+
e
x
2
=
1
1
+
e
−
(
x
1
−
x
2
)
\frac{e^{x_1}}{e^{x_1}+e^{x_2}}=\frac{1}{1+e^{-(x_1-x_2)}}
ex1+ex2ex1=1+e−(x1−x2)1
Swish、Mish
f
(
x
)
=
x
∗
s
i
g
m
o
i
d
(
β
x
)
f(x)=x*sigmoid(\beta{x})
f(x)=x∗sigmoid(βx)
f
(
x
)
=
x
.
t
a
n
h
(
θ
(
x
)
)
θ
(
x
)
=
l
n
(
1
+
e
x
)
f(x)=x.tanh(\theta(x))\theta(x)=ln(1+e^x)
f(x)=x.tanh(θ(x))θ(x)=ln(1+ex)
- 无上界,有下界:无上届是任何激活函数都需要的特征,因此它避免了导致训练速度急剧下降的梯度饱和。因此,加速训练过程。无下界属性有助于实现强正则化效果(适当的拟合模型)。
- 非单调函数:这种性质有助于保持小的负值,从而稳定网络梯度流。大多数常用的激活函数,如ReLU, Leaky ReLU,由于其差分为0,不能保持负值,因此大多数神经元没有得到更新。
- 无穷连续性和光滑性:Mish是光滑函数,具有较好的泛化能力和结果的有效优化能力,可以提高结果的质量。
- 计算量较大,但是效果好:与ReLU相比,它的计算量比较大,但在深度神经网络中显示了,但在深度神经网络中显示了比ReLU更好的结果。
- 自门控:此属性受到Swish函数的启发,其中标量输入被共给gate。它优于像ReLU这样的点式激活函数,后者只接受单个标量输入,而不需要更改网络参数。
anchor based和anchor free
anchor-base存在的问题:
- 与锚点框相关超参(scale, aspect ratio, IoU threshold)会较明显的影响最终预测效果
- 大量的锚点会导致运算复杂度增大,产生的参数较多
- anchor中往往会带来大量的负样本,预制的锚点大小,比例在检测差异较大物体时不够灵活
anchor-free算法的优点:
- 使用类似分割的思想来解决目标检测问题
- 不需要调优与anchor相关的超参数
- 避免大量计算GT boxes与anchor boxes之间的IoU,使得训练过程占用内存更低。
DCN
- 问题:对几何变换建模的能力主要来自于数据增强,相同CNN层的所有激活单元的感受野相同,普通卷积的感受野是正方形;
- 方案:卷积核不变,被卷积的感受野的特征图可变形。在特征图后用卷积先学习偏移量,通道N的特征图输出通道2N(分辨率相同)的偏移图,(因为每个通道的每个点都有xy两个偏移),根据offset调整感受野,进行卷积。
- 偏移量有小数时采用双线性插值
- 优缺点:效果更好,支持了任意形状,缺点是增加了计算量
手撕代码篇
计算卷积网络输出尺寸
卷积神经网络的计算公式为: N = ( W − K + 2 P ) / S + 1 N=(W-K+2P)/S+1 N=(W−K+2P)/S+1
NMS
import numpy as np
def py_cpu_nms(dets, thresh):
x1 = dets[:,0]
y1 = dets[:,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 +1)*(y2 - y1 + 1)
order = scores.argsort()[::-1] # 降序排列
keep = [] # 保留的边界框
while order.size > 0:
i = order[0] # 取置信度最大的框
keep.append(i) # 将其作为保留的框
# 以下计算置信度最大的框与其它所有的框的IOU,以下都是以向量形式表示和计算
xx1 = np.maximum(x1[i], x1[order[1:]]) #计算xmin的max,即overlap的xmin
yy1 = np.maximum(y1[i], y1[order[1:]]) # 计算ymin的max
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter) # 计算IoU
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1] #删除IoU大于阈值的框
return keep
SoftNMS
import numpy as np
def soft_nms(dets, sigma=0.5, Nt=0.5, method=2, threshold=0.1):
box_len = len(dets)
for i in range(box_len):
tmpx1, tmpx2, tmpx2, tmpy2, ts = dets[i, 0], dets[i, 1], dets[i, 2], dets[i,3], dets[i, 4]
max_pos = i
max_socres = ts
# get max box
pos = i + 1
while pos < box_len:
if max_scores < dets[pos, 4]:
max_scores = dets[pos, 4]
max_pos = pos
pos += 1
# add max box as a detection
dets[i, :] = dets[max_pos, :]
# swap ith box with position of max box
dets[max_pos, 0] = tmpx1
dets[max_pos, 1] = tmpy1
dets[max_pos, 2] = tmpx2
dets[max_pos, 3] = tmpy2
dets[max_pos, 4] = ts
# 将置信度最高的box赋给临时变量
tmpx1, tmpy1, tmpx2, tmpy2, ts = dets[i, 0], dets[i, 1], dets[i, 2], dets[i, 3], dets[i, 4]
pos = i + 1
# NMS
while pos < box_len:
x1, y1, x2, y2 = dets[pos, 0], dets[pos, 1], dets[pos, 2], dets[pos, 3]
area = (x2 - x1 + 1)*(y2 - y1 + 1)
iw = (max(tmpx1, x1) - min(tmpx2, x2) + 1)
ih = (max(tmpy1, y1) - min(tmpy2, y2) + 1)
if iw > 0 and ih > 0:
overlaps = iw * ih
ious = overlaps / ((tmpx2 - tmpx1 + 1) * (tmpy2 - tmpy1 + 1) + area - overlaps)
if method == 1: # 线性
if ious > Nt:
weight = 1 - ious
else:
weight = 1
elif method == 2 # gaussian
weight = np.exp(-(ious**2)/sigma)
else:
if ious > Nt:
weight = 0
else:
weight = 1
# 赋予该box新的置信度
dets[pos, 4] =weight*dets[pos, 4]
# 如果box得分低于阈值thresh,则通过与最后一个框交换来丢弃该框
if dets[pos, 4] < threshold:
dets[pos, 0] = dets[box_len-1, 0]
dets[pos, 1] = dets[box_len-1, 1]
dets[pos, 2] = dets[box_len-1, 2]
dets[pos, 3] = dets[box_len-1, 3]
dets[pos, 4] = dets[box_len-1, 4]
box_len = box_len - 1
pos = pos - 1
pos += 1
keep = [i for i in range(box_len)]
return keep
yolo系列的区别
yolo2
先说一下匹配原则,对于某个ground truth, 首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值,计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置,然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth 匹配,对应的预测框用来预测这个ground truth.
yolo中一个ground truth 只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。
yolo3
全部的4032个输出框直接和ground truth 计算IOU,取IOU最高的cell分配ground truth;这是因为现有有3个特征值输出,中心有重叠。
用过蒸馏吗
没用过,个人理解就是找个模型结构类似但是更具表达能力的上位模型,对原模型进行制导,具体做法就是用KL散度或者均方差让2个模型的输出分布一致
同步BN,异步BN
BN在具体实现的时候有4个关键参数,分别是running_mean, running_variance, gamma, beta。其中gamma, beta可以直接和其他网络权重一起同等的训练,因为也是反向传播更新的。
但是running_mean和running_variance是在前向传播的时候更新的。多卡训练的时候,每张卡就会在各自的卡内计算切分后的batchsize下的mean和variance再更新running_mean和running_variance.
这样,等于是batchsize变小了。然后为了解决这个问题就有了同步BN,再更新running_mean和running_variance的时候多张卡做一次同步,然后再做normalize。
多卡GPU用过吗?梯度最后是如何更新的
多个有2种,一种的dataparallel,一种的distributeddataparallel。 DP的话是每张卡把梯度汇总给主卡,然后主卡做反向传播更新再把参数发给其他卡
DDP是大家把梯度汇总之后各自在各自的卡里面更新。
DDP比DP快的原因:
- DDP是多进程,DP是单进程多线程,避免了GIL带来的性能开销
- DDP是大家各自传播梯度后,用ring all reduce做平均并传会给大家,然后大家各自做更新。
数据增强的方法
random crop, flip, mosaic, 旋转,对比度,亮度,mixup,对抗样本














 2573
2573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









