







NLP论文笔记1:Neural Architectures for Named Entity Recognition
看这一篇论文的主要目的是看BILSTM-CRF模型,对于实际应用,CRF看分词、BILSTM-CRF做NER,接下来通过BILSTM-CNN-CRF做序列标注,NLP几个基本的应用也差不多了,句法分析貌似比较复杂,留作以后吧。
********************开始论文吧****************
一.叙述
命名实体识别一直是更具挑战性的NLP应用,为什么更具挑战呢?原因有两方面,一方面,可用的已标注的命名实体数据集很少,量也小;另一方面,命名词的规律性不强,约束很少,组织名称、地名,随意性还是很强的,还有一方面是新加入的命名词、新加入的领域也很多,想从小批量的数据集中提取出完整的特征,比较难。
这篇论文将命名实体分为两种:1.多个词组成的命名实体,2.单个词组成的命名实体。对于第一种,实体中的每个词都很重要,且词与词之间的关系也要关注,作者用了两种模型来对比这种命名的识别效果——BILSTM-CRF和栈式LSTM。
第二种命名有两个重点:什么样的词更像是实体?一个词在什么样的语境下更容易成为实体。作者采用了字向量来解决第一个问题,采用词向量来解决第二个问题。
训练时使用dropout提高泛化。
二. LSTM-CRF模型
1.LSTM输出到CRF tagging
LSTM和CRF模型都不陌生,之前都单独看过原理和程序,这里,笨妞更关心的是BILSTM后的结果如何与CRF结合起来。
作者认为,使用LSTM处理NLP问题最简单的方式是将输出LSTM层的输出作为特征直接用于tagging决策,这种方式在POS标注上很有效,但是在对外部的标签依赖性很强的分类问题上局限性很大,而NER正好是这样的问题。因为在NER的序列标注“语法”中的那些规则很难用独立的假设建立模型。
作者将LSTM的输出作为打分矩阵(称作P),
对于一个输入句子 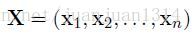
P是一个n*k的矩阵,k是输出标注Y的取值个数,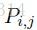
这个句子的预测标注序列表示为 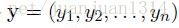
定义y矩阵的打分函数为 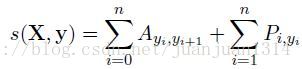
其中,A是转移打分矩阵,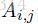
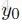
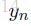
然后,然后一个softmax计算所有可能的标注的概率: 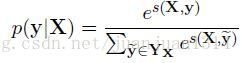
训练时采用极大似然估计作为损失函数,对数似然函数如下: 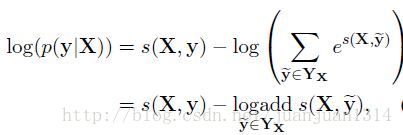
其中,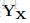
预测输出序列时通过以下公式的最大得分得到:
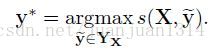
2.参数和训练
最后的打分是BILSTM的输出(每个词的向量)和类似于二元语法的转移分数结合计算出来的,整个网络的结构如下: 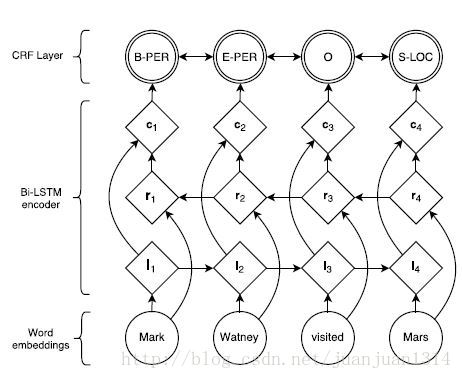
图1
整个模型的参数是二元转移打分矩阵A中的各分数和BILSTM中用于计算矩阵P的参数和BILSTM的输入词向量。
为了改善结果,作者还在ci层和CRF层添加了一个隐层。以上所有的参数优化的目标都是最大化对数似然函数。
3.Tagging Schemes
作者提到了两种tagging scheme,一种是IOB标注形式的,这种形式标注集为{B、I、O},B表示命名实体的开头词,I表示命名实体非开始的词,O表示非命名实体词。另一个中是IOBES标注形式,标注集合为{B、I、E、O、S},添加的E表示命名实体结尾词,S表示单个词的命名实体。
三.Stack-LSTM
stack-LSTM在transition-based 依存句法分析被用到,这个模型可以直接构建多词的命名实体。
模型通过一个堆栈数据结构来构建输入的分块。在stack-LSTM中,LSTM通过一个堆栈指针扩展。序列化的LSTM是从左到右的,而stack-LSTM确保embedding记录既可以增加,也可以移除,他的工作原理如同堆栈数据结构。
这个模型的原论文是《Transition-based dependency parsing with stack long-short-term memory》
1.chunking算法
模型包含两个组件:transition inventory、存已经处理过的词的buffer。transition inventory如下图
图2

如图所示,transition的动作包含3个:SHIFT、REDUCE、OUT。SHIFT transition将从buffer搬到stack;OUT transition将词从buffer直接搬到输出stack;REDUCE transition从stack的top层将所有词推出来,组成 “chunking”,并将这个chunking的representation压入到output stack中。当stack和output stack全部为空,这个算法要做的事情就完了。
模型通过定义每一时刻下的动作的概率分布来使模型参数化,LSTM的输出用于计算每一时刻采取的action的个概率分布,通过最大化整个序列的标准标注的条件概率而使模型得到训练。
预测过程中,寻找输入序列每一步概率最大的action。对于对于输入序列中的每个词将经历从buffer直接到输出,或者从buffer到stack,再从stack到输出这两步。对于长度为n的序列,最多了2n个action。
(这个模型真心没怎么看懂,后面看看原论文再说吧)
四.输入Word Embeeding
这一部分主要看基于字母的词模型,词向量之前已经看过了。
1.模型
下图是通过字母生成词的embedding的结构: 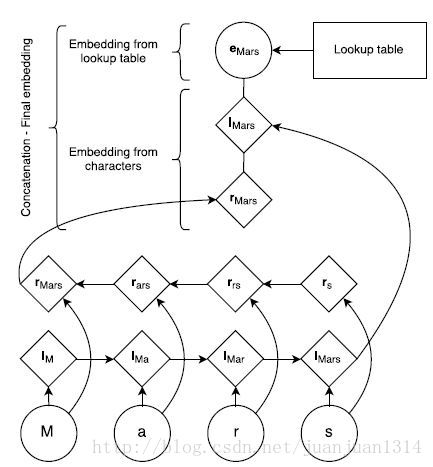
图3
首先,生成一份字母的向量查询表,每个字母的向量随机生成,同时还有一份词自身的向量查询表。根据LSTM的前向和后向词顺序查询子母向量表得到基于字母的正序向量和逆序向量,再和词lookup向量一起组成完整的词向量输入到BILSTM。
如图3所示,词”Mars”的词向量生成过程。首先,从Lookup table中查询出字母”M”,”a”,”r”,”s”这4个字母的向量,然后根据正序和逆序分别组成“M->a->r->s”的向量和“s->r->a->M”的向量,最后词word的lookup table向量、基于字母的正序向量、基于字母的逆序向量共同组成”Mars”的向量。
2.预训练
上一部分提到基于字母的lookup向量和词lookup向量表是随机生成的,但这样的效果没有预训练的效果好。
作者用word2vec的skip-n-gram训练词的lookup向量,然后在模型训练时只做fine-tuned。
3.dropout
作者发现,用随机初始化的字母lookup向量也预训练的词向量结合,效果并不理想,于是在组合两方面向量的最后一层加入了一个dropout后,再输入到BILSTM,这样效果显著。
五.实验
1.模型超参数配置
训练通过BP算法更新参数。用SGD以0.01的学习率优化参数,以5.0作为梯度的阈值。
LSTM-CRF模型用前向和后向LSTM各一个独立层,维度为100,并加入了0.5的dropout。
Stack-LSTM每一个stack用了2个100维的网络层,用16维的向量表示actoion,输出向量为20维。这个模型也加入了dropout,dropout rate通过调试,采用最好的那一个(不固定),采用贪婪模型,获取局部最优。
2.实验结果
作者对比了各参考论文的结果和自己的4种模型的结果,结果如下: 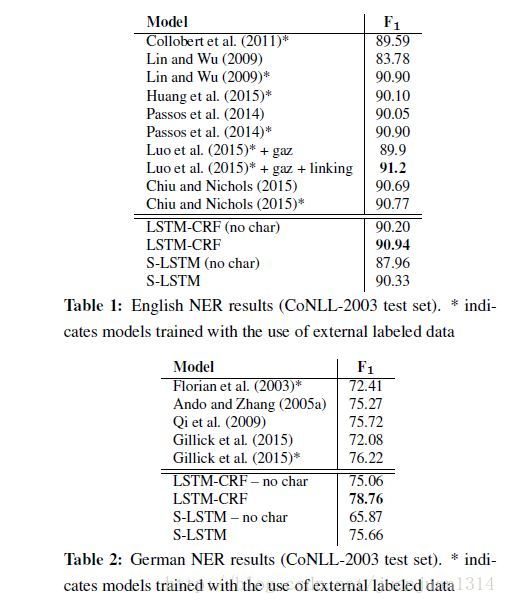
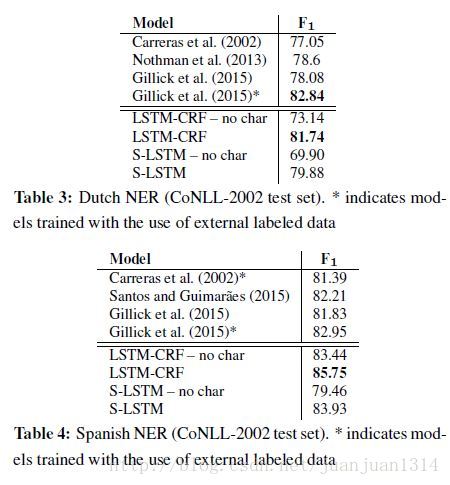
总体来说带基于字母的词向量表示的BILSTM-CRF模型的准确率在4种语言的NER工作准确性最好。
*************************论文看完啦****************
看起来很不错的样子,接下来就是跑BILSTM-CRF的时刻啦。程序自带的代码是通过Theano实现的,对于只会用tensorflow的笨妞来说,默默的找一个tensorflow版本的改一改算了。














 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









