







课程安排
- 物流信息的需求分析
- 技术实现分析
- 基于MongoDB的功能实现
- 多级缓存的解决方案
- Redis缓存存在的问题分析并解决
1、背景说明
让收发件人清晰的了解到包裹的“实时”状态,就是“快递到哪了”
在电商大促期间,快件数量非常庞大,也就意味着查询人的量也是很大的
使用缓存技术解决并形成通用的高并发查询的解决方案
2、需求分析
用户寄件后,是需要查看运单的运输详情,也就是需要查看整个转运节点,类似这样:
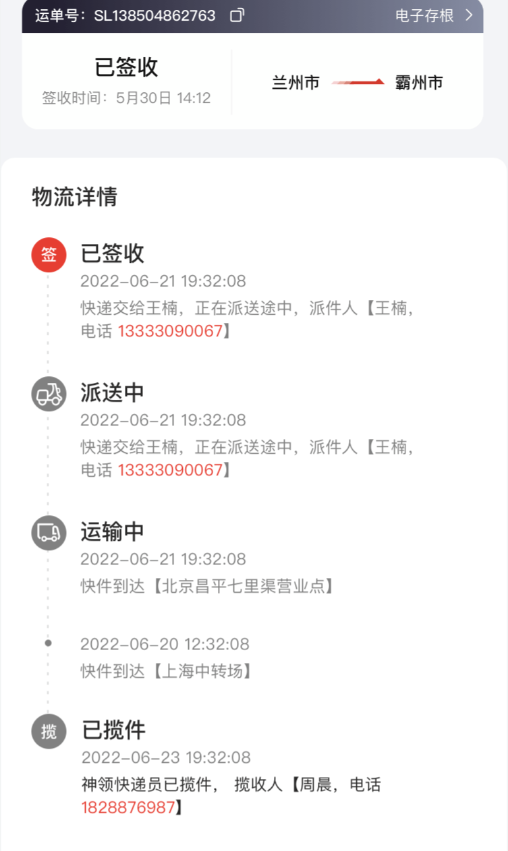
产品的需求描述如下(在快递员端的产品文档中):

可以看出,物流信息中有状态、时间、具体信息、快递员姓名、快递员联系方式等信息。

在快递员取件时使用mq发消息进行保存
3、实现分析
3.1、MySQL实现
如果采用MySQL的存储,一般是这样存储的,首先设计表结构:
CREATE TABLE `sl_transport_info` (
`id` bigint NOT NULL AUTO_INCREMENT,
`transport_order_id` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '运单号',
`status` varchar(10) DEFAULT NULL COMMENT '状态,例如:运输中',
`info` varchar(500) DEFAULT NULL COMMENT '详细信息,例如:您的快件已到达【北京通州分拣中心】',
`created` datetime DEFAULT NULL COMMENT '创建时间',
`updated` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;插入测试数据:
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (1, 'SL920733749248', '已取件', '神领快递员已取件, 取件人【快递员,电话 18810966207}】', '2022-09-25 10:48:30', '2022-09-25 10:48:33');
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (2, 'SL920733749262', '已取件', '神领快递员已取件, 取件人【快递员,电话 18810966207}】', '2022-09-25 10:51:11', '2022-09-25 10:51:14');
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (3, 'SL920733749248', '运输中', '您的快件已到达【昌平区转运中心】', '2022-09-25 11:14:33', '2022-09-25 11:14:36');
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (4, 'SL920733749248', '运输中', '您的快件已到达【北京市转运中心】', '2022-09-25 11:14:54', '2022-09-25 11:14:57');
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (5, 'SL920733749262', '运输中', '您的快件已到达【昌平区转运中心】', '2022-09-25 11:15:17', '2022-09-25 11:15:19');
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (6, 'SL920733749262', '运输中', '您的快件已到达【江苏省南京市玄武区长江路】', '2022-09-25 11:15:44', '2022-09-25 11:15:47');
INSERT INTO `sl_transport_info`(`id`, `transport_order_id`, `status`, `info`, `created`, `updated`) VALUES (7, 'SL920733749248', '已签收', '您的快递已签收,如有疑问请联系快递员【快递员},电话18810966207】,感谢您使用神领快递,期待再次为您服务', '2022-09-25 11:16:16', '2022-09-25 11:16:19');
查询运单号【SL920733749248】的物流信息:
SELECT
*
FROM
sl_transport_info
WHERE
transport_order_id = 'SL920733749248'
ORDER BY
created ASC结果:

3.2、优化(MongoDB实现)
分析
物流信息功能的特点:
- 数据量大
- 查询频率高(签收后查询频率低)
显然,在存储大数据方面非关系型数据库更合适一些。并且物流信息相对用户信息,物品信息不是那么重要,不需要mysql的ACID功能,故使用MongoDB数据库。
MySQL存储在一张表中,每条物流信息就是一条行数据,数据条数将是运单数量的数倍,查询时需要通过运单id作为条件,按照时间正序排序得到所有的结果。
其次MongoDB数据库可以使用嵌套文档存储数据,一条物流信息只需存储一条数据即可。查询时指需要根据运单id进行一次查询。相较于mysql的多条数据存储物流信息,有较大优势
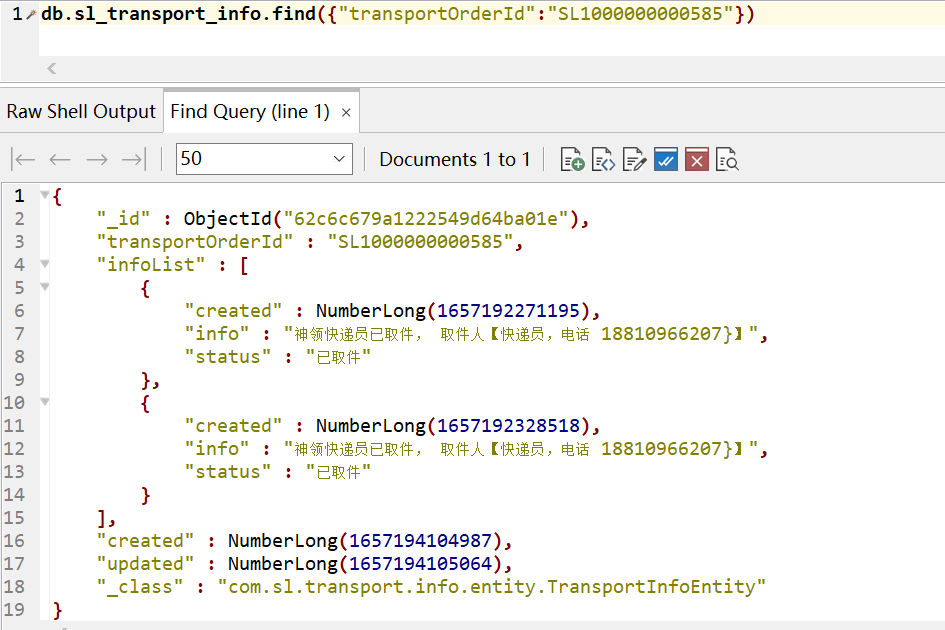
基于MongoDB的实现,可以充分利用MongoDB数据结构的特点,可以这样存储:
{
"_id": ObjectId("62c6c679a1222549d64ba01e"),
"transportOrderId": "SL1000000000585",
"infoList": [
{
"created": NumberLong("1657192271195"),
"info": "神领快递员已取件, 取件人【快递员,电话 18810966207}】",
"status": "已取件"
},
{
"created": NumberLong("1657192328518"),
"info": "神领快递员已取件, 取件人【快递员,电话 18810966207}】",
"status": "已取件"
}
],
"created": NumberLong("1657194104987"),
"updated": NumberLong("1657194105064"),
"_class": "com.sl.transport.info.entity.TransportInfoEntity"
}如果有新的信息加入的话,只需要向【infoList】中插入元素即可,查询的话按照【transportOrderId】条件查询。
db.sl_transport_info.find({"transportOrderId":"SL1000000000585"})
4、功能实现
4.1、Service实现
在TransportInfoService中定义了2个方法,一个是新增或更新数据,另一个是根据运单号查询物流信息。
4.2.1、saveOrUpdate
逻辑
根据运单id和infoDetail查询数据库(infoDetail是infoList中的一条信息)
1根据运单id查询TransportInfoEntity
2TransportInfoEntity为空,新建对象,并设置属性,设置更新时间,保存数据库
3非空,将infoDetail加入infoList中。设置更新时间,保存数据库
代码
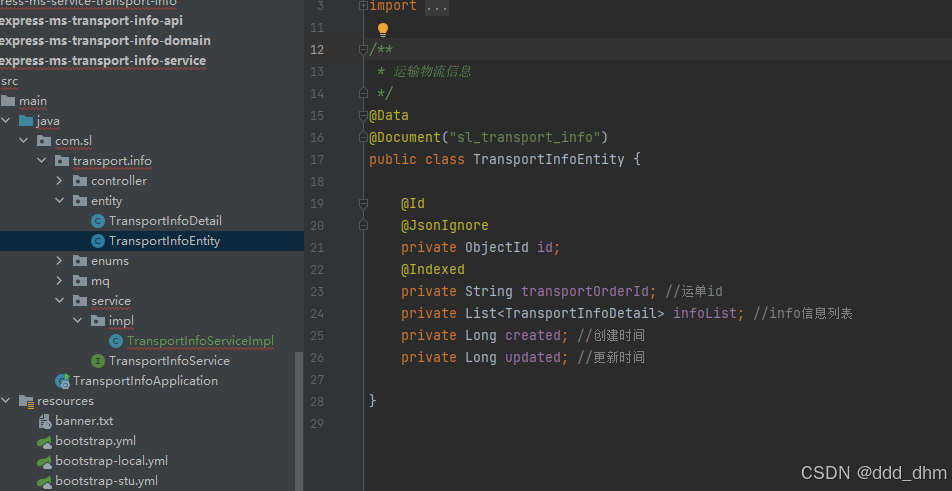
mongoTemplate.findOne(Query.query(Criteria.where("transportOrderId").is(transportOrderId)),TransportInfoEntity.class);
查询,此处传入TransportInfoEntity.class,即可识别该类对应表,因为在类中有@Document注释
@Override
public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {
TransportInfoEntity transportInfoEntity = mongoTemplate.findOne(Query.query(Criteria.where("transportOrderId").is(transportOrderId)),TransportInfoEntity.class);
if(ObjectUtil.isEmpty(transportInfoEntity))
{
TransportInfoEntity entity = new TransportInfoEntity();
entity.setTransportOrderId(transportOrderId);
entity.setInfoList(ListUtil.toList(infoDetail));
entity.setCreated(System.currentTimeMillis());
entity.setUpdated(System.currentTimeMillis());
return mongoTemplate.save(entity);
}
else{
transportInfoEntity.getInfoList().add(infoDetail);
transportInfoEntity.setUpdated(System.currentTimeMillis());
return mongoTemplate.save(transportInfoEntity);
}
}注意: MongoDB也有自动填写id的功能,不设置也可以
entity.setId(new ObjectId());
4.2.2、查询
根据运单号查询物流信息。
@Override
public TransportInfoEntity queryByTransportOrderId(String transportOrderId) {
//根据运单id查询
Query query = Query.query(Criteria.where("transportOrderId").is(transportOrderId)); //构造查询条件
TransportInfoEntity transportInfoEntity = this.mongoTemplate.findOne(query, TransportInfoEntity.class);
if (ObjectUtil.isNotEmpty(transportInfoEntity)) {
return transportInfoEntity;
}
throw new SLException(ExceptionEnum.NOT_FOUND);
}4.2、记录物流信息
4.2.1、分析
如何时记录物流信息?
一种是微服务直接调用,另一种是通过消息的方式调用,也就是同步和异步的方式。
选择通过消息的方式,主要原因有两个:
- 物流信息数据的更新的实时性并不高,例如,运单到达某个转运中心,晚几分种记录信息也是可以的。
- 更新数据时,并发量比较大,例如,一辆车装了几千或几万个包裹,到达某个转运中心后,司机入库时,需要一下记录几千或几万个运单的物流数据,在这一时刻并发量是比较大的,通过消息(异步)的方式,可以进行对流量削峰,从而保障系统的稳定性。
4.2.2、消息结构
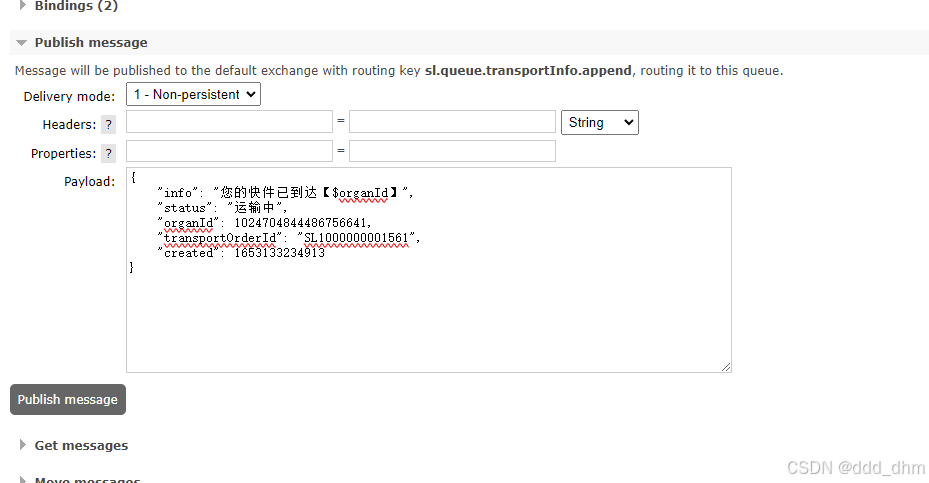
消息的结构如下:
{
"info": "您的快件已到达【$organId】",
"status": "运输中",
"organId": 1012479939628238305,
"transportOrderId": "SL920733749248",
"created": 1653133234913
}通过$organId占位符表示机构,也就是,需要通过传入的organId查询机构名称替换到info中,当然了,如果没有机构,无需替换。
练习1
难度系数:★★★★☆
描述:在work微服务中完成发送【物流信息】的消息的逻辑,这样的话,work微服务就和transport-info微服务联系起来了。
提示,一共有4处代码需要完善:
- com.sl.ms.work.mq.CourierMQListener#listenCourierPickupMsg()
- com.sl.ms.work.service.impl.PickupDispatchTaskServiceImpl#saveTaskPickupDispatch()
-
- 此处实现难度较大,会涉及到基础服务系统消息模块,需要阅读相应的代码进行理解。
- com.sl.ms.work.service.impl.TransportOrderServiceImpl#updateStatus()
- com.sl.ms.work.service.impl.TransportOrderServiceImpl#updateByTaskId()
另外,包裹的签收与拒收的消息已经在【快递员微服务】中实现,学生可自行阅读源码:
- com.sl.ms.web.courier.service.impl.TaskServiceImpl#sign()
- com.sl.ms.web.courier.service.impl.TaskServiceImpl#reject()
4.2.3、功能实现
发送消息为练习,此处指实现消费消息的代码

JSONUtil.toBean(msg, TransportOrderMsg.class);
if (StrUtil.contains(info, "$organId")) {
info = StrUtil.replace(info,"$organId",organDTO.getName());
@Component
public class TransportInfoMQListener {
@Resource
private OrganFeign organFeign;
@Resource
private TransportInfoService transportInfoService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = Constants.MQ.Queues.TRANSPORT_INFO_APPEND),
exchange = @Exchange(name = Constants.MQ.Exchanges.TRANSPORT_INFO, type = ExchangeTypes.TOPIC),
key = Constants.MQ.RoutingKeys.TRANSPORT_INFO_APPEND
))
@Transactional
public void listenTransportInfoMsg(String msg) {
//{"info":"您的快件已到达【$organId】", "status":"运输中", "organId":90001, "transportOrderId":"SL920733749248" , "created":1653133234913}
TransportInfoMsg transportInfoMsg = JSONUtil.toBean(msg, TransportInfoMsg.class);
String transportOrderId = transportInfoMsg.getTransportOrderId();
Long organId = transportInfoMsg.getOrganId();
String info = transportInfoMsg.getInfo();
if (StrUtil.contains(info, "$organId"))
{
OrganDTO organDTO = organFeign.queryById(organId);
if(ObjectUtil.isEmpty(organDTO)) return;
info = StrUtil.replace(info,"$organId",organDTO.getName());
}
TransportInfoDetail transportInfoDetail = new TransportInfoDetail();
transportInfoDetail.setCreated(transportInfoMsg.getCreated());
transportInfoDetail.setInfo(info);
transportInfoDetail.setStatus(transportInfoMsg.getStatus());
transportInfoService.saveOrUpdate(transportOrderId,transportInfoDetail);
}
}测试
mq发消息
确认消费成功:应用程序在处理消息完成后,向MQ服务发送确认(ACK),表示消息已成功处理。此时,MQ服务将该消息从队列中删除,避免重复消费。
共享配置文件:消费消息失败最多重新发送三次,之后将消息归为错误队列中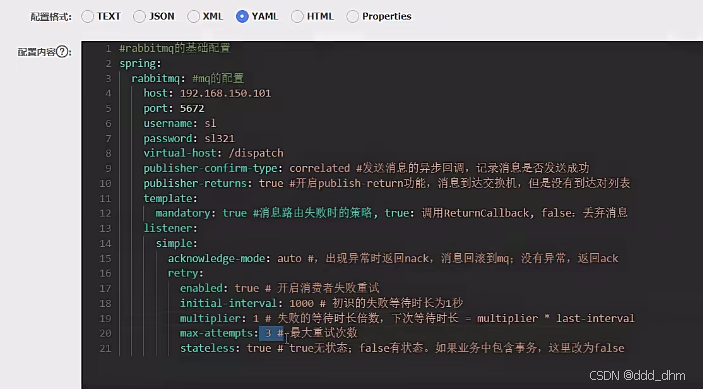
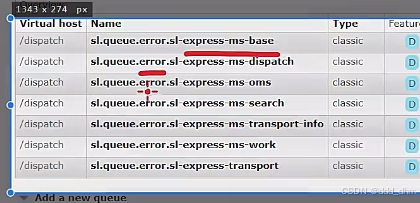
5、多级缓存解决方案
1 nginx+redis,2 Caffeine,3MongoDB数据库
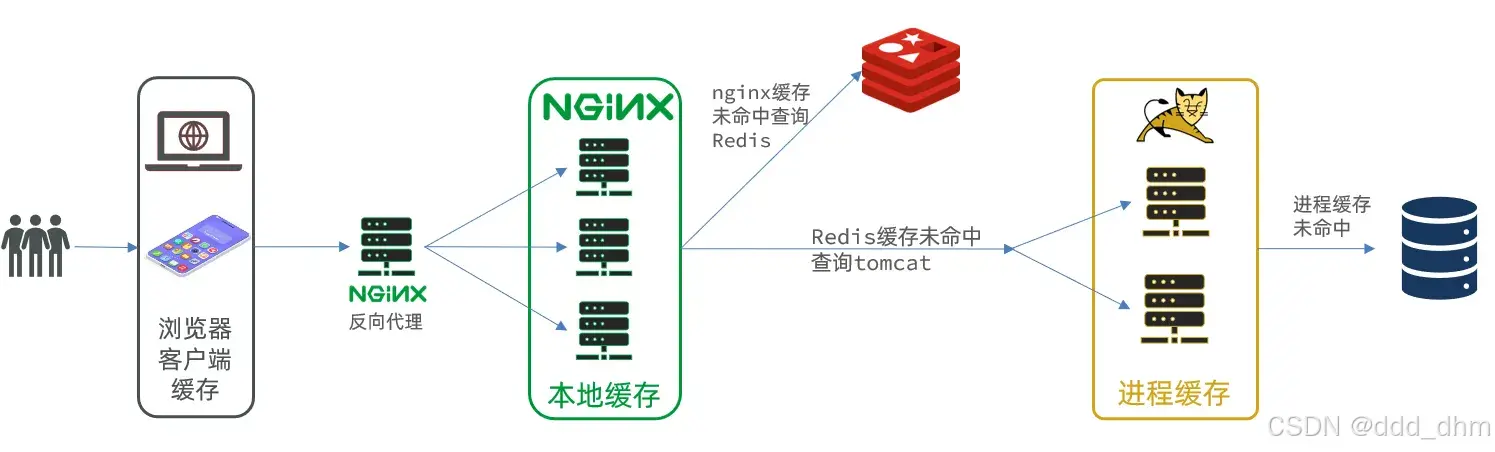
- 浏览器的本地缓存
- 使用Nginx作为反向代理的架构时,可以启用Nginx的本地缓存,对于代理数据进行缓存
- 如果Nginx的本地缓存未命中,可以在Nginx中编写Lua脚本从Redis中命中数据
- 如果Redis依然没有命中的话,请求就会进入到Tomcat,也就是执行我们写的微服务,在程序中可以设置进程级的缓存,如果命中直接返回即可。
- 如果进程级的缓存依然没有命中的话,请求才会进入到持久层数据库查询数据。
| 缓存位置 | Nginx 服务器上的本地磁盘或内存 | JVM 内存(堆内存) |
| 作用层次 | 代理服务器(请求进入后) | 应用服务器(进程内缓存) |
| 典型延迟 | 低,依赖 I/O 性能 | 极低(JVM 内存读取) |
| 缓存数据类型 | 静态资源、API 响应 | 计算结果、动态数据、数据库查询结果 |
| 缓存策略 | 通过配置(缓存时间、缓存键等) | 动态淘汰策略(LRU、LFU) |
| 扩展性 | 适用于多个应用服务器 | 仅适用于单个 JVM 实例 |
| 缓存失效 | 配置失效时间或主动清理 | 自适应淘汰 |
| 适用场景 | 静态资源、减少后端压力 | 动态数据、高性能应用内缓存 |
| 网络通信 | 没有本地通信,但会与后端通信 | 无需网络通信 |
由于nginx到redis很多语法需要学,本项目更改多级缓存方案为
1 Caffeine,2 redis,3MongoDB数据库
其中Caffeine与redis都是部署在内存中的,但redis属于微服务是单独的进程,tomcat再调用redis需要网络通信的时间。Redis 则是独立部署的内存缓存系统,通常作为微服务的一部分运行在单独的进程中。应用程序在需要访问缓存数据时,需要通过网络通信与 Redis 进行交互。
caffeine与代码写在一起,是JVM(Java Virtual Machine)级别的缓存(用的java中的堆内存),数据存储在本地内存中,应用程序在请求时可以直接访问,无需进行网络通信,因此不存在额外的延迟。
Redis 是为分布式系统设计的,能够跨多台机器运行并扩展。
如果 Redis 被嵌入到每个应用服务器的内存中,缓存将无法跨服务器共享,这意味着每个服务器都将有自己独立的缓存,导致数据不一致以及缓存的重复存储。
5.2、Caffeine快速入门
Caffeine是一个基于Java8开发,实现进程级的缓存。Spring内部的缓存使用的就是Caffeine。
5.2.1、使用
导入依赖:
<!--jvm进程缓存-->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
基本使用:
package com.sl.transport.info.service;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.junit.jupiter.api.Test;
public class CaffeineTest {
@Test
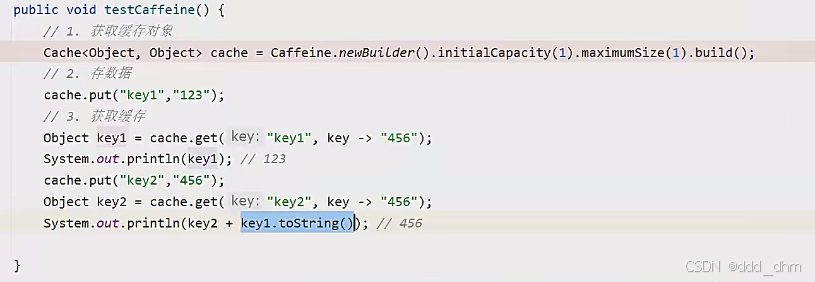
public void testCaffeine() {
// 创建缓存对象
Cache<String, Object> cache = Caffeine.newBuilder()
.initialCapacity(10) //缓存初始容量
.maximumSize(100) //缓存最大容量
.build();
//将数据存储缓存中
cache.put("key1", 123);
// 从缓存中命中数据
// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是在未命中时执行
// 优先根据key查询进程缓存,如果未命中,则执行参数二的Lambda表达式
//没有查到值时,用456补充
Object value1 = cache.get("key1", key -> 456);
System.out.println(value1); //123
Object value2 = cache.get("key2", key -> 456);
System.out.println(value2); //456
}
}
5.2.2、清除策略
面试问题:数据越来越多,装不下怎么办
Window TinyLfu策略来删除缓存。带来的优势是高命中,高性能
工作流程
-
新数据加入:
- 当有新的数据到来时,首先将其放入Window 区域,表示这个数据是最新的请求。
-
淘汰 Window 区域数据:
- Window 区域中的数据由于容量限制,会被逐步淘汰。一旦 Window 缓存满了,系统将决定是否将一个数据晋升到 Main 区域。
-
晋升至 Main 区域:
- 当 Window 中的数据要被淘汰时,TinyLFU 通过频率计数判断该条目是否足够频繁访问。如果其历史访问频率足够高,则将其从 Window 区域晋升到 Main 区域。
- 如果频率不高,则该条目直接淘汰,不进入 Main 缓存。
-
Main 区域中的数据淘汰:
- 当 Main 区域也满时,淘汰的数据基于 TinyLFU 的频率计数进行决策。访问频率低的数据会被逐出缓存。
- 由于 Main 缓存存储的是长期访问频率较高的条目,因此这个区域的内容更稳定,减少了短期热点的影响。
Caffeine提供了三种缓存驱逐策略:
- 基于容量(项目中使用):设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1,当缓存超出这个容量的时候,会使用Window TinyLfu策略来删除缓存。
.build();- 基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
一个进程操作,不会立即驱逐,缓存中有两个key
两个线程,会在第二个线程结束以后,淘汰key1
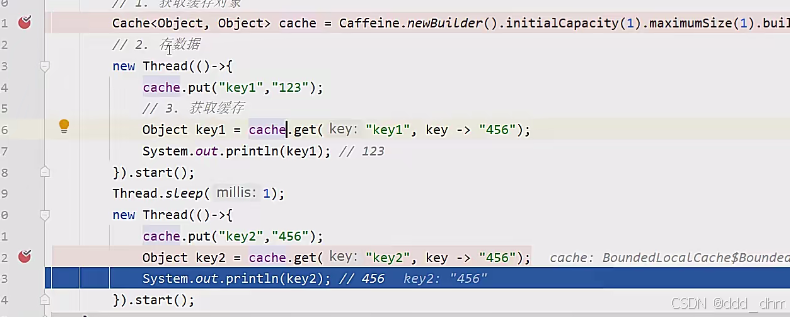
5.3、一级缓存
下面我们通过增加Caffeine实现一级缓存,主要是在TransportInfoController中修改逻辑。
逻辑:先判断caffeine缓存中有无,无才继续走controller调用
5.3.1、设置全局Caffeine配置
package com.sl.transport.info.config;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.sl.transport.info.domain.TransportInfoDTO;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Caffeine缓存配置
*/
@Configuration
public class CaffeineConfig {
@Value("${caffeine.init}")
private Integer init;
@Value("${caffeine.max}")
private Integer max;
@Bean
public Cache<String, TransportInfoDTO> transportInfoCache() {
return Caffeine.newBuilder()
.initialCapacity(init)
.maximumSize(max).build();
}
}
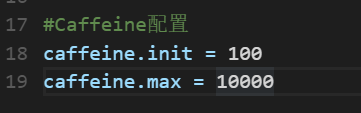
具体的配置项在Nacos中的配置中心的sl-express-ms-transport-info.properties中:
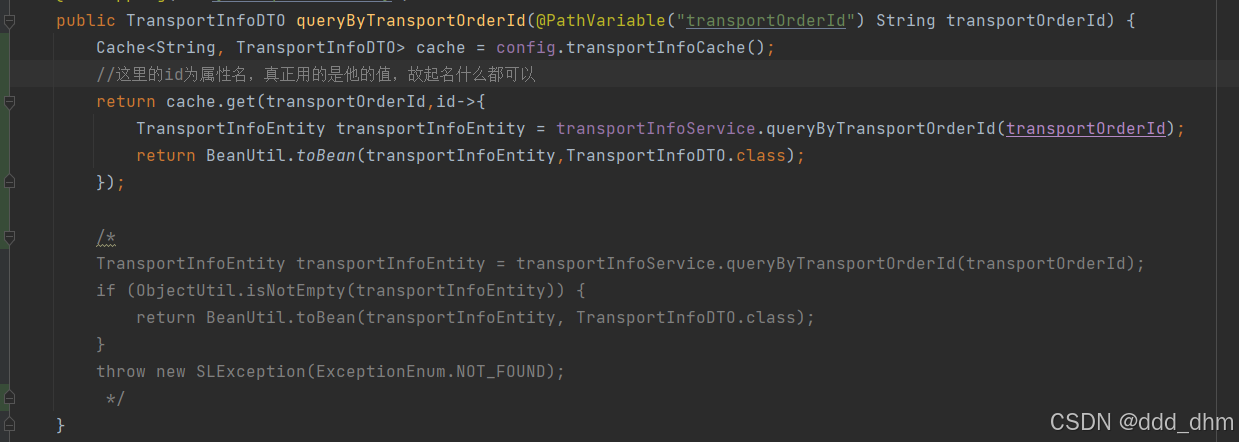
5.3.2、改造Controller
public class TransportInfoController {
@Resource
private TransportInfoService transportInfoService;
@Resource
private CaffeineConfig config;
/**
* 根据运单id查询运单信息
*
* @param transportOrderId 运单号
* @return 运单信息
*/
@ApiImplicitParams({
@ApiImplicitParam(name = "transportOrderId", value = "运单id")
})
@ApiOperation(value = "查询", notes = "根据运单id查询物流信息")
@GetMapping("{transportOrderId}")
public TransportInfoDTO queryByTransportOrderId(@PathVariable("transportOrderId") String transportOrderId) {
Cache<String, TransportInfoDTO> cache = config.transportInfoCache();
//这里的id为属性名,真正用的是他的值,故起名什么都可以
return cache.get(transportOrderId,id->{
TransportInfoEntity transportInfoEntity = transportInfoService.queryByTransportOrderId(transportOrderId);
return BeanUtil.toBean(transportInfoEntity,TransportInfoDTO.class);
});
/*
TransportInfoEntity transportInfoEntity = transportInfoService.queryByTransportOrderId(transportOrderId);
if (ObjectUtil.isNotEmpty(transportInfoEntity)) {
return BeanUtil.toBean(transportInfoEntity, TransportInfoDTO.class);
}
throw new SLException(ExceptionEnum.NOT_FOUND);
*/
}5.4、二级缓存
二级缓存通过Redis的存储实现,这里我们使用Spring Cache进行缓存数据的存储和读取。
在Service中增加SpringCache的注解
5.4.1、Redis配置
Spring Cache默认是采用jdk的对象序列化方式,这种方式比较占用空间而且性能差,所以往往会将值以json的方式存储,此时就需要对RedisCacheManager进行自定义的配置。
使用RedisCacheManager后,可以直接通过注解使用redis
package com.sl.transport.info.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
/**
* Redis相关的配置
*/
@Configuration
public class RedisConfig {
/**
* 存储的默认有效期时间,单位:小时
*/
@Value("${redis.ttl:1}")
private Integer redisTtl;
@Bean
public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
// 默认配置
RedisCacheConfiguration defaultCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
// 设置key的序列化方式为字符串
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
// 设置value的序列化方式为json格式
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))
.disableCachingNullValues() // 不缓存null
.entryTtl(Duration.ofHours(redisTtl)); // 默认缓存数据保存1小时
// 构redis缓存管理器
RedisCacheManager redisCacheManager = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisTemplate.getConnectionFactory())
.cacheDefaults(defaultCacheConfiguration)
.transactionAware() // 只在事务成功提交后才会进行缓存的put/evict操作
.build();
return redisCacheManager;
}
}5.4.2、缓存注解
接下来需要在Service中增加SpringCache的注解,确保数据可以保存、更新数据到Redis。
@Override
@CachePut(value = "transport-info", key = "#p0") //更新缓存数据
public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {
//省略代码
}
@Override
@Cacheable(value = "transport-info", key = "#p0") //新增缓存数据
public TransportInfoEntity queryByTransportOrderId(String transportOrderId) {
//省略代码
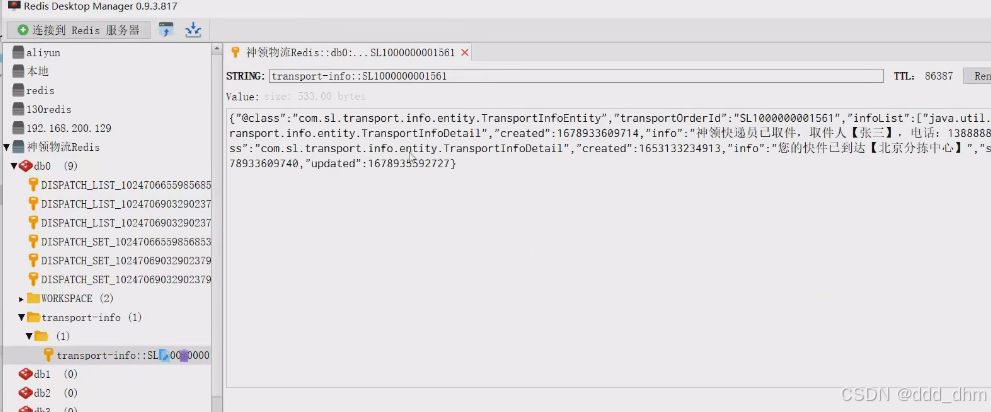
}@Cacheable(value = "transport-info", key = "#p0") 或者
@Cacheable(value = "transport-info", key = "#transOrderId")
#p0,意为param0,即第一个参数。将transport-info::第一个参数拼接后查询redis数据库

@Cacheable(value = "transport-info", key = "#p0")
@Override
public TransportInfoEntity queryByTransportOrderId(String transportOrderId) {
//根据运单id查询
Query query = Query.query(Criteria.where("transportOrderId").is(transportOrderId)); //构造查询条件
TransportInfoEntity transportInfoEntity = this.mongoTemplate.findOne(query, TransportInfoEntity.class);
if (ObjectUtil.isNotEmpty(transportInfoEntity)) {
return transportInfoEntity;
}
throw new SLException(ExceptionEnum.NOT_FOUND);
}
5.5、一级缓存更新的问题
更新物流信息时,只是更新了Redis中的数据,并没有更新Caffeine中的数据,需要在更新数据时将Caffeine中相应的数据删除。
具体实现如下:
@Resource
private Cache<String, TransportInfoDTO> transportInfoCache;
@Override
@CachePut(value = "transport-info", key = "#p0") //更新缓存数据
public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {
//省略代码
//清除缓存中的数据
this.transportInfoCache.invalidate(transportOrderId);
//保存/更新到MongoDB
return this.mongoTemplate.save(transportInfoEntity);
}这样的话就可以删除Caffeine中的数据,也就意味着下次查询时会从二级缓存中查询到数据,再存储到Caffeine中。
5.6、分布式场景下的问题
面试引出:写代码时遇到了一致性的bug
5.6.1、问题分析
上述this.transportInfoCache.invalidate(transportOrderId);清理缓存代码,当两个微服务启动时,caffeine只会在自己的微服务区域进行清理缓存
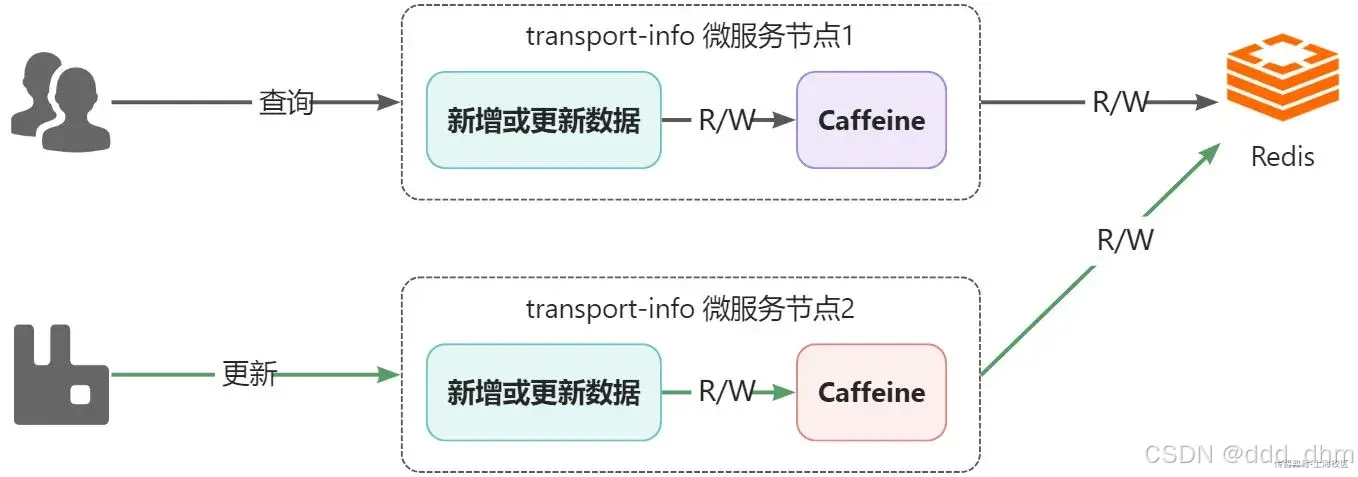
- 接着,系统通过节点2更新了物流数据,此时节点2中的caffeine和Redis都是更新后的数据
- 用户还是进行查询动作,依然是通过节点1查询,此时查询到的将是旧的数据,也就是出现了一级缓存与二级缓存之间的数据不一致的问题
5.6.2、问题解决
关于消息的实现,可以采用RabbitMQ,也可以采用Redis的消息订阅发布来实现,在这里为了应用技术的多样化,所以采用Redis的订阅发布来实现。
mq:数据更新时发送消息,微服务监听消息队列并更新缓存
redis发布订阅(实现简单):当reids内容变化时,订阅reids的微服务都会收到通知
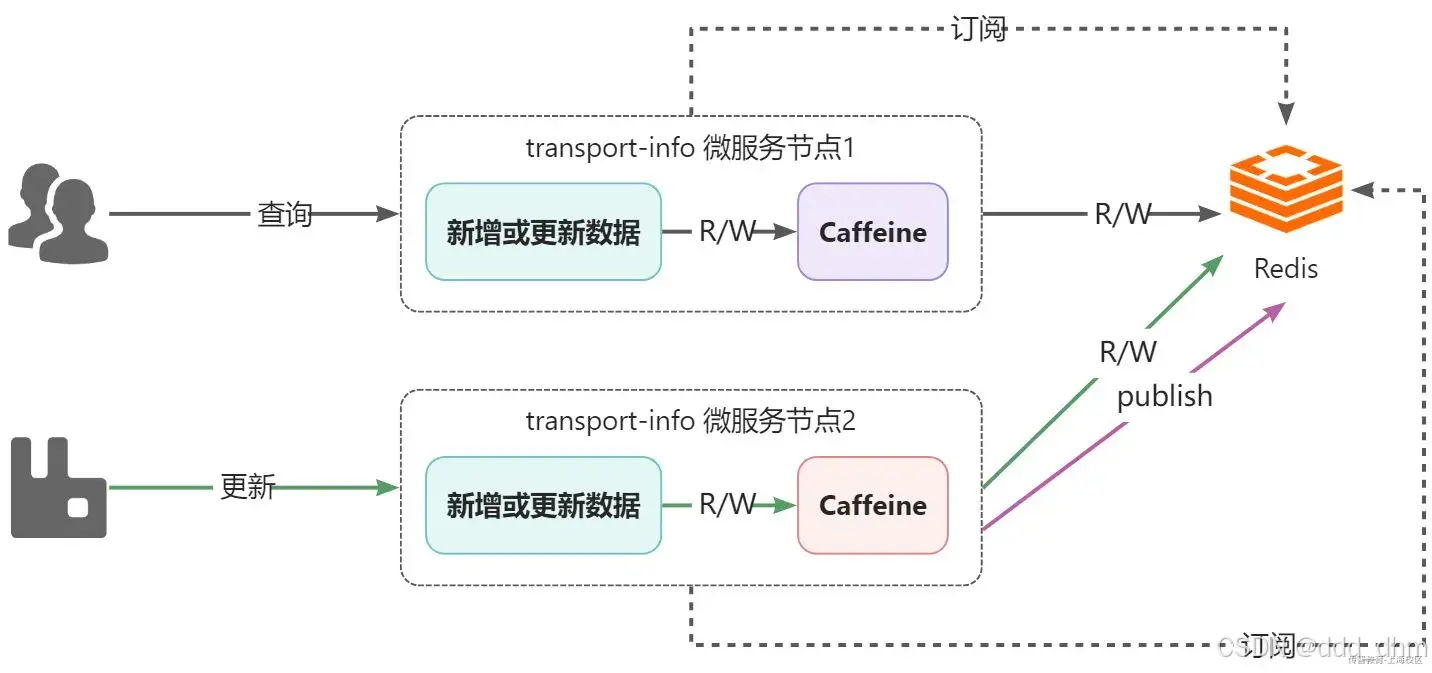 在
在com.sl.transport.info.config.RedisConfig增加订阅的配置:
这段代码的主要功能是配置一个 Redis 消息监听器容器,使其能够订阅 Redis 的指定频道(sl-express-ms-transport-info-caffeine),并且通过 listenerAdapter 处理订阅到的消息。
//发布订频道的字符串
public static final String CHANNEL_TOPIC = "sl-express-ms-transport-info-caffeine";
/**
* 配置订阅,用于解决Caffeine一致性的问题
*
* @param connectionFactory 链接工厂
* @param listenerAdapter 消息监听器
* @return 消息监听容器
*/
//配置一个ioc容器对象
@Bean
public RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory,
MessageListenerAdapter listenerAdapter) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
//使用 addMessageListener 方法,将消息监听器 listenerAdapter 和指定的频道(CHANNEL_TOPIC)关联起来。
container.addMessageListener(listenerAdapter, new ChannelTopic(CHANNEL_TOPIC));
return container;
}编写RedisMessageListener用于监听消息,删除caffeine中的数据。
package com.sl.transport.info.mq;
import cn.hutool.core.convert.Convert;
import com.github.benmanes.caffeine.cache.Cache;
import com.sl.transport.info.domain.TransportInfoDTO;
import org.springframework.data.redis.connection.Message;
import org.springframework.data.redis.listener.adapter.MessageListenerAdapter;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
* redis消息监听,解决Caffeine一致性的问题
*/
@Component
public class RedisMessageListener extends MessageListenerAdapter {
@Resource
private Cache<String, TransportInfoDTO> transportInfoCache;
@Override
public void onMessage(Message message, byte[] pattern) {
//获取到消息中的运单id
String transportOrderId = Convert.toStr(message);
//将本jvm中的缓存删除掉
this.transportInfoCache.invalidate(transportOrderId);
}
}
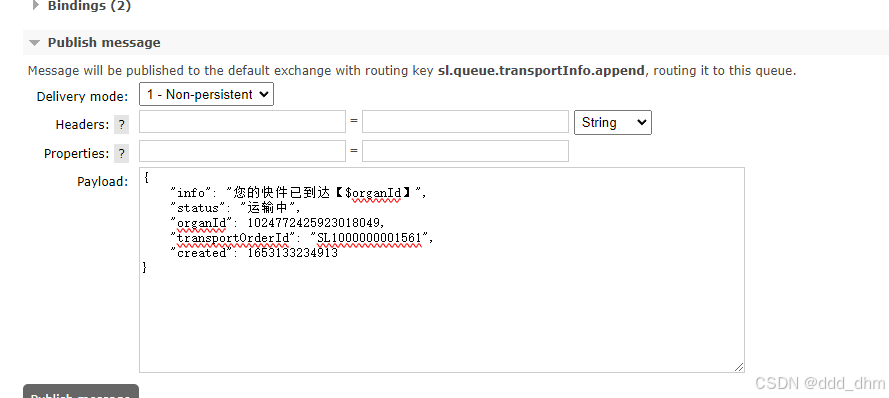
更新数据后发送消息:
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
@CachePut(value = "transport-info", key = "#p0")
public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {
//省略代码
//清除缓存中的数据
// this.transportInfoCache.invalidate(transportOrderId);
//发布订阅消息到redis
this.stringRedisTemplate.convertAndSend(RedisConfig.CHANNEL_TOPIC, transportOrderId);
//保存/更新到MongoDB
return this.mongoTemplate.save(transportInfoEntity);
}
测试
注意,测试时需开启TransportApplication,OrganFiegn接口需要
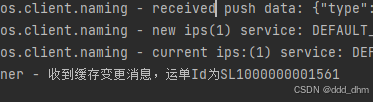
caffeine一级缓存已清除
总结
reids订阅频道,使redis像mq一样可以群发消息。
reidsTemplate.convertAndSend(RedisConfig.CHANNEL_TOPIC,transportOrderId);
但由于reids没有可靠性,重试机制的处理。故只在清理缓存的时候使用
6、Redis的缓存问题
在使用Redis时,在高并发场景下会出现一些问题,常见的问题有:缓存击穿、缓存雪崩、缓存穿透,这三个问题也是面试时的高频问题。
6.1、缓存击穿(一个key)
6.1.1、说明
缓存击穿是指,某一热点数据存储到redis中,该数据处于高并发场景下,如果此时该key过期失效,这样就会有大量的并发请求进入到数据库,对数据库产生大的压力,甚至会压垮数据库。
6.1.2、解决方案
针对于缓存击穿这种情况,常见的解决方案有两种:
- 热数据不设置过期时间
- 使用互斥锁,可以使用redisson的分布式锁实现,就是从redis中查询不到数据时,不要立刻去查数据库,而是先获取锁,获取到锁后再去查询数据库,而其他未获取到锁的请求进行重试,这样就可以确保只有一个查询数据库并且更新缓存的请求。
6.1.3、实现
本项目没有实现
防止有人恶意根据运单号查询,高并发的机器人查询操作
使用如下解决方案,解决机器人大量查询问题
1韵达快递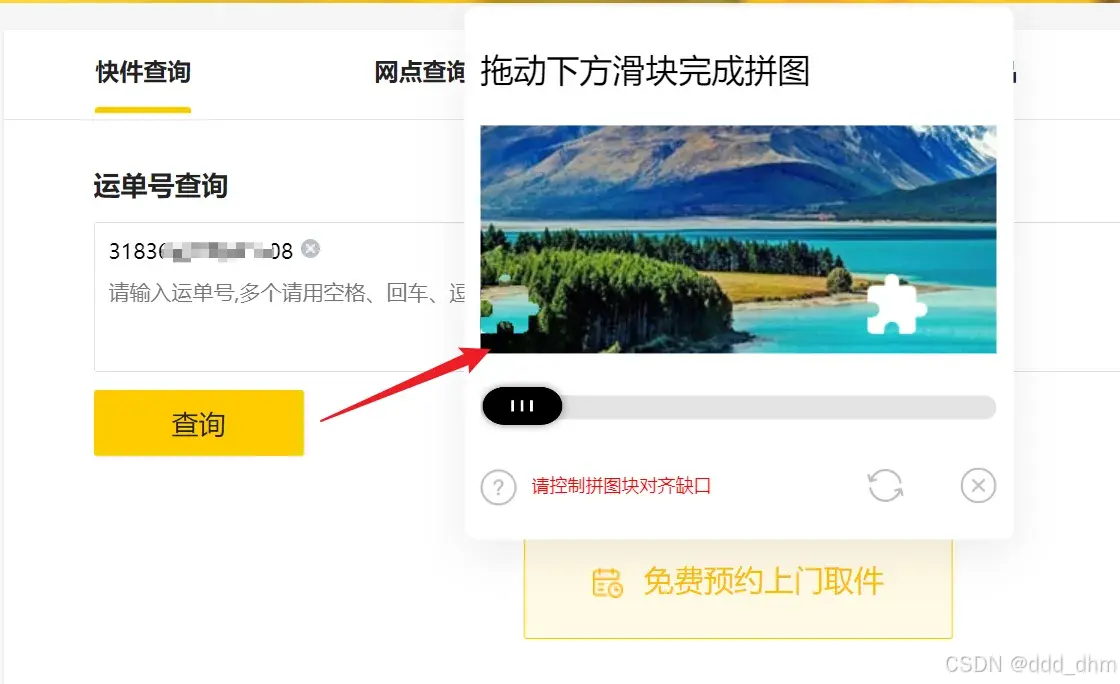
2顺丰
填写寄件人的电话号和运单号
6.2、缓存雪崩(大量key)
6.2.1、说明
缓存雪崩的情况往往是由两种情况产生:
- 情况1:由于大量 key 设置了相同的过期时间(数据在缓存和数据库都存在),一旦到达过期时间点,这些 key 集体失效,造成访问这些 key 的请求全部进入数据库。
- 情况2:Redis 实例宕机,大量请求进入数据库
6.2.2、解决方案
本项目使用(情况1)错开过期时间和(情况2)搭建高可用集群
针对于雪崩问题,可以分情况进行解决:
- 情况1的解决方案
-
- 错开过期时间:在过期时间上加上随机值(比如 1~5 分钟)
- 服务降级:暂停非核心数据查询缓存,返回预定义信息(错误页面,空值等),使请求不访问数据库

- 情况2的解决方案
-
- 事前预防:搭建高可用集群
redis集群分类:主从,哨兵(定义一写哨兵监控主从服务,出现问题时自动切换,保证这最少一个正常运行,但存储的数据量有限),分片集群
-
- 构建多级缓存,实现成本稍高(查询不同的缓存获得数据)
- 熔断:通过监控一旦雪崩出现,暂停缓存访问待实例恢复,返回预定义信息(有损方案)
- 限流:通过监控一旦发现数据库访问量超过阈值,限制访问数据库的请求数(有损方案)
6.2.3、实现
我们将针对【情况1】的解决方案进行实现,主要是在默认的时间基础上随机增加1-10分钟有效期时间。
需要注意的是,使用SpringCache的@Cacheable注解是无法指定有效时间的,所以需要自定义RedisCacheManager对有效期时间进行随机设置。
自定义RedisCacheManager:
package com.sl.transport.info.config;
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.core.util.RandomUtil;
import org.springframework.data.redis.cache.RedisCache;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import java.time.Duration;
/**
* 自定义CacheManager,用于设置不同的过期时间,防止雪崩问题的发生
*/
public class MyRedisCacheManager extends RedisCacheManager {
public MyRedisCacheManager(RedisCacheWriter cacheWriter, RedisCacheConfiguration defaultCacheConfiguration) {
super(cacheWriter, defaultCacheConfiguration);
}
@Override
protected RedisCache createRedisCache(String name, RedisCacheConfiguration cacheConfig) {
//获取到原有过期时间
Duration duration = cacheConfig.getTtl();
if (ObjectUtil.isNotEmpty(duration)) {
//在原有时间上随机增加1~10分钟
Duration newDuration = duration.plusMinutes(RandomUtil.randomInt(1, 11));
//更新缓存配置中的过期时间,将新的过期时间设置到缓存配置中。
cacheConfig = cacheConfig.entryTtl(newDuration);
}
return super.createRedisCache(name, cacheConfig);
}
}更改代码到MyRedisCacheManager中:
@Bean
public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
// 默认配置
RedisCacheConfiguration defaultCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
// 设置key的序列化方式为字符串
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
// 设置value的序列化方式为json格式
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))
.disableCachingNullValues() // 不缓存null
.entryTtl(Duration.ofHours(redisTtl)); // 默认缓存数据保存1小时
// 构redis缓存管理器
// RedisCacheManager redisCacheManager = RedisCacheManager.RedisCacheManagerBuilder
// .fromConnectionFactory(redisTemplate.getConnectionFactory())
// .cacheDefaults(defaultCacheConfiguration)
// .transactionAware()
// .build();
//使用自定义缓存管理器
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());
MyRedisCacheManager myRedisCacheManager = new MyRedisCacheManager(redisCacheWriter, defaultCacheConfiguration);
myRedisCacheManager.setTransactionAware(true); // 只在事务成功提交后才会进行缓存的put/evict操作
return myRedisCacheManager;
}6.3、缓存穿透(一个key不存在)
6.3.1、说明
缓存穿透是指,如果一个 key 在缓存和数据库都不存在,那么访问这个 key 每次都会进入数据库
- 很可能被恶意请求利用
- 缓存雪崩与缓存击穿都是数据库中有,但缓存暂时缺失
- 缓存雪崩与缓存击穿都能自然恢复,但缓存穿透则不能
6.3.2、解决方案
针对缓存穿透,一般有两种解决方案,分别是:
- 如果数据库没有,也将此不存在的 key 设置 null 值放入缓存,缺点是这样的 key 没有任何业务作用,白占空间
- 采用BloomFilter(布隆过滤器)解决,基本思路就是将存在数据的哈希值存储到一个足够大的bitmap中,在查询redis时,先查询布隆过滤器,如果数据不存在直接返回即可,如果存在的话,再执行缓存中命中、数据库查询等操作。
bitmap:Redis 将每个字符串的每个字符转换成 8 位二进制的形式,因此可以通过位操作来存储和操作布尔值。
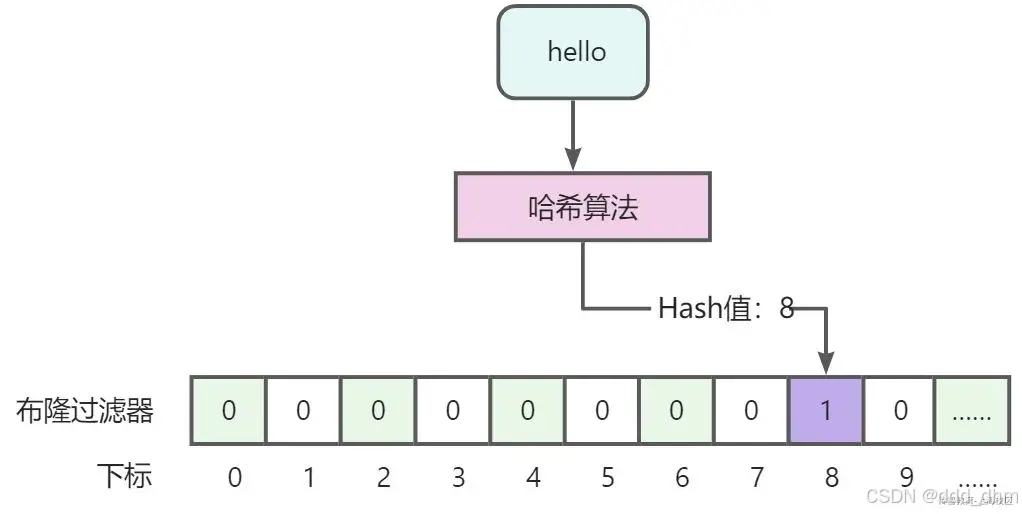
6.3.3、布隆过滤器(面试点)
实际上是一个很长的二进制向量(0或1)和一系列随机映射函数,默认是0。
布隆过滤器存储在reids的内存中,判断二进制位非常快
缺点:
不同的key经过哈希算法得到相同的值,1个位置可能会代表多个数据,会出现误判。所以布隆过滤器基本是不能做删除动作的。
使用布隆过滤器能够判断一定不存在,而不能用来判断一定存在。
降低误判率:
1:加长数组长度,使计算后得到同一值概率降低
2:增加多个哈希算法,计算多个hash值。因为不同的值经过多个哈希算法计算得到全部相同值的概率要低一些。
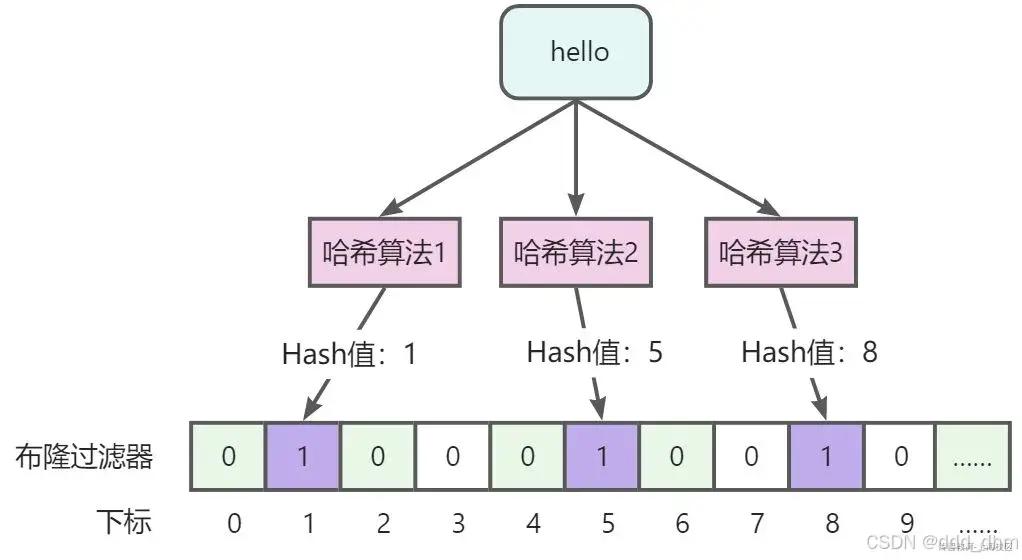
多个哈希算法只要得到一个0值,即可判断不存在
总结下布隆过滤器的优缺点:
●优点
存储的二进制数据,1或0,不存储真实数据,空间占用比较小且安全。
插入和查询速度非常快,因为是基于数组下标的,类似HashMap,其时间复杂度是O(K),其中k是指哈希算法个数。
● 缺点
存在误判,可以通过增加哈希算法个数降低误判率,不能完全避免误判。
删除困难,因为一个位置可能会代表多个值,不能做删除。
牢记结论:布隆过滤器能够判断一定不存在,而不能用来判断一定存在
总结:因为本项目的物流信息不可以删除(idDeleted逻辑删除),所以很适配布隆过滤器不能删除的特性
6.3.4、实现
关于布隆过滤器的使用,建议使用Google的Guava 或 Redission基于Redis实现,前者是在单体架构下比较适合,后者更适合在分布式场景下,便于多个服务节点之间共享。
Redission基于Redis,使用string类型数据,生成二进制数组进行存储,最大可用长度为:4294967294。
引入Redission依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
</dependency>
导入Redission的配置:
代码实现了 Redisson 客户端的配置,用于与单节点的 Redis 服务器进行连接。通过 Spring 的配置类和 Redis 配置属性,将 Redis 和 Redisson 客户端关联起来,便于在项目中使用 Redisson 进行 Redis 操作。
package com.sl.transport.info.config;
import cn.hutool.core.convert.Convert;
import cn.hutool.core.util.StrUtil;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.config.SingleServerConfig;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
public class RedissonConfiguration {
@Resource
private RedisProperties redisProperties;
@Bean
public RedissonClient redissonSingle() {
Config config = new Config();
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());
if (null != (redisProperties.getTimeout())) {
serverConfig.setTimeout(1000 * Convert.toInt(redisProperties.getTimeout().getSeconds()));
}
if (StrUtil.isNotEmpty(redisProperties.getPassword())) {
serverConfig.setPassword(redisProperties.getPassword());
}
return Redisson.create(config);
}
}自定义布隆过滤器配置:
package com.sl.transport.info.config;
import lombok.Getter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
/**
* 布隆过滤器相关配置
*/
@Getter
@Configuration
public class BloomFilterConfig {
/**
* 名称,默认:sl-bloom-filter
*/
@Value("${bloom.name:sl-bloom-filter}")
private String name;
/**
* 布隆过滤器长度,最大支持Integer.MAX_VALUE*2,即:4294967294,默认:1千万
*/
@Value("${bloom.expectedInsertions:10000000}")
private long expectedInsertions;
/**
* 误判率,默认:0.05
*/
@Value("${bloom.falseProbability:0.05d}")
private double falseProbability;
}定义BloomFilterService接口:
package com.sl.transport.info.service;
/**
* 布隆过滤器服务
*/
public interface BloomFilterService {
/**
* 初始化布隆过滤器
*/
void init();
/**
* 向布隆过滤器中添加数据
*
* @param obj 待添加的数据
* @return 是否成功
*/
//通过算法计算得到下标,将该位置值置为1
boolean add(Object obj);
/**
* 判断数据是否存在
*
* @param obj 数据
* @return 是否存在
*/
boolean contains(Object obj);
}编写实现类:
1:从reidssonClient获取布隆过滤器实例,作为获取布隆过滤器的方法
2:新建布隆过滤器对象,并调用初始化方法.tryInit()
package com.sl.transport.info.service.impl;
import com.sl.transport.info.config.BloomFilterConfig;
import com.sl.transport.info.service.BloomFilterService;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
@Service
public class BloomFilterServiceImpl implements BloomFilterService {
@Resource
private RedissonClient redissonClient;
@Resource
private BloomFilterConfig bloomFilterConfig;
private RBloomFilter<Object> getBloomFilter() {
//从 Redis 中获取一个布隆过滤器实例,name 是布隆过滤器的名称,通常从配置中获取。
return this.redissonClient.getBloomFilter(this.bloomFilterConfig.getName());
}
@Override
@PostConstruct // @PostConstruct 注解:该方法会在 Spring 容器启动并完成依赖注入后执行,确保布隆过滤器在系统启动时初始化。
public void init() {
RBloomFilter<Object> bloomFilter = this.getBloomFilter();
//用于初始化布隆过滤器,参数为:expectedInsertions:预期插入的元素数量 falseProbability:允许的误判率
bloomFilter.tryInit(this.bloomFilterConfig.getExpectedInsertions(), this.bloomFilterConfig.getFalseProbability());
}
@Override
public boolean add(Object obj) {
return this.getBloomFilter().add(obj);
}
@Override
public boolean contains(Object obj) {
return this.getBloomFilter().contains(obj);
}
}添加代码(查询所有运单id)
@Override
public List<String> queryIds() {
List<TransportInfoEntity> list = mongoTemplate.findAll(TransportInfoEntity.class);
return list.stream().map(l->{ return l.getTransportOrderId();}).collect(Collectors.toList());
}在BloomFilterServiceImpl.init()中实现将项目原有的全部数据存储到过滤器中
List<String> list = transportInfoService.queryIds();
if(ObjectUtil.isNotEmpty(list)) {
for (String transportOrderId : list) {
bloomFilter.add(transportOrderId);
}
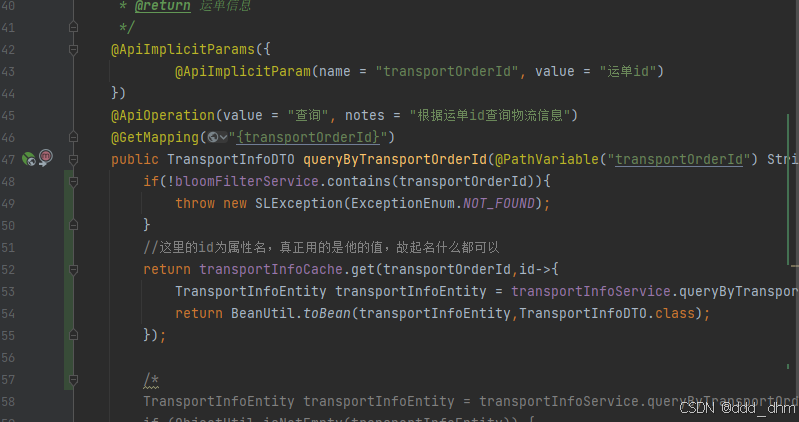
}改造TransportInfoController的查询逻辑,如果布隆过滤器中不存在直接返回即可,无需进行缓存命中。
if(!bloomFilterService.contains(transportOrderId)){
throw new SLException(ExceptionEnum.NOT_FOUND);
}
7、练习
7.1、练习1
难度系数:★★★★☆
描述:在work微服务中完成发送【物流信息】的消息的逻辑,这样的话,work微服务就和transport-info微服务联系起来了。
提示,一共有4处代码需要完善:
- com.sl.ms.work.mq.CourierMQListener#listenCourierPickupMsg()
- com.sl.ms.work.service.impl.PickupDispatchTaskServiceImpl#saveTaskPickupDispatch()
-
- 此处实现难度较大,会涉及到基础服务系统消息模块,需要阅读相应的代码进行理解。
- com.sl.ms.work.service.impl.TransportOrderServiceImpl#updateStatus()
- com.sl.ms.work.service.impl.TransportOrderServiceImpl#updateByTaskId()
另外,包裹的签收与拒收的消息已经在【快递员微服务】中实现,学生可自行阅读源码:
- com.sl.ms.web.courier.service.impl.TaskServiceImpl#sign()
- com.sl.ms.web.courier.service.impl.TaskServiceImpl#reject()
根据消息结构,封装消息,使用mq发送到对应的队列即可
{
"info": "您的快件已到达【$organId】",
"status": "运输中",
"organId": 1012479939628238305,
"transportOrderId": "SL920733749248",
"created": 1653133234913
}
8、面试连环问
面试官问:
- 你们项目中的物流信息那块存储是怎么做的?为什么要选择MongoDB?
MongoDB为非关系型数据库,可以使用嵌套文档存储多条物流信息,只需一条数据存储。而mysql需使用多条数据进行存储
- 针对于查询并发高的问题你们是怎么解决的?有用多级缓存吗?具体是怎么用的(结合代码,配置)?
收件人,发件人都会查询物流信息。caffeine,reids,MongoDB。caffeine与redis都为内存级缓存,但caffeine存储在jvm中,而redis属于一个独立的微服务,访问redis有网络通信开销。
- 多级缓存间的数据不一致是如何解决的?
使用reids订阅技术,当有微服务更新数据时,发消息到reids,reids再发送给各个订阅redis的微服务
- 来,说说在使用Redis场景中的缓存击穿、缓存雪崩、缓存穿透都是啥意思?对应的解决方案是啥?实际你解决过哪个问题?
缓存击穿(一个热点key)1不设置过期时间 2访问数据库时加锁。另:加验证码过滤机器人
缓存雪崩(1大量key同时过期 不同key原过期时间加随机过期时间 2Redis 宕机 使用集群技术)
缓存穿透(一个不存在的key)1设置reids中key值为null,占空间 2使用布隆过滤器
- 说说布隆过滤器的优缺点是什么?什么样的场景适合使用布隆过滤器?
缺点:1只能存,不能删 2存在误判
适合场景:判断数据不存在时


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









