






人工神经网络
人工神经网络是由大量的最简单的基本元件——神经元相互连接,通过模拟人脑的大脑处理信息的方式,进行信息并行处理和非线性转换的复杂网络系统。其优点是多输入多输出实现了数据的并行处理以及自学能力。
神经网络的拓扑结构包括网络层数、各层神经元的数量以及各神经元之间相互连接的方式。
常用的激励函数

如果数据进行映射处理,比如 100,在激活函数上基本上是直线段,很难降低误差,就算是用优化算法也没多大作用,这也是为什么需要对数据进行[0,1]或者[-1,1]的映射处理。将数据映射在 0-1 之内就可以用对数 S 型函数,映射在[-1,1]可以用正切 S 型函数。
BP神经网络
BP 指的是误差反向传播的一个方法。当发现第一次输出误差较大时,就将误差带到阈值和权值更新公式中进行计算,得到新的权值和阈值,更新公式中涉及到了激活函数的导数, 因此在选择激活函数或者自己定义激活函数时需要考虑到所选激活函数必须是可微可导的。
学习过程
第一阶段,在正向传播的时候,将学习样本数据输入网络,经过每一层的权值、阈值,通过激活函数映射,到最后一层的输出,在反向传播的时候,需要计算出本次输出与理想目标的输出的误差,反向传播到每一层神经元当中更新权值和阈值。(在学习过程中,如果误差较大,那么就会认为目前网络中的权值和阈值还存在不合理的地方,还需要进行修正)
第二阶段,在权值更新过程,将误差和输入激活时的数值相乘得到权值的梯度,通过从权重中减去梯度的比例(该比例为学习效率),将权重降到梯度的相反方向,得到新的权值,阈值更新则直接和学习效率与误差有关。
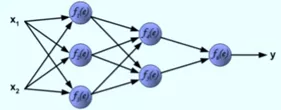
接下来用图来解释下 BP 算法,以一个两层隐含层结构的神经网络为例:
其中单个神经元的传递过程:
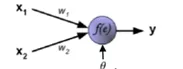
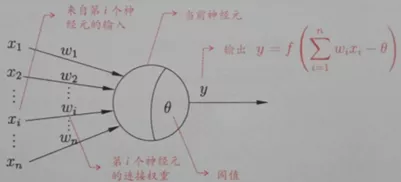
x1、x2 乘以 w1、w2 之和传递到节点,减去阈值θ(阈值有正有负,除了初始的)通过激活函数映射出一个值,即输出 y,此刻的 y 及时传递到下一神经节点的输入值,公式表示为
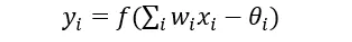
为了避免混淆权值和阈值,可以这么看,权值存在于神经节点的链 接上,阈值存在于神经节点中,有多少节点链接就有多少权值,有多少节点就有多少阈值。
整个网络的传递过程如下:

然后进行反向的误差传递,首先将网络得到的值 y6 与 y 做差得到误差 δ6,然后反向的 传递给f4、f5得到误差δ4、δ5,依次类推,其中阈值的更新与设置的学习效率和误差直接有关
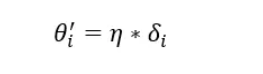
以下是误差的反向传递:

接着是权值和阈值的更新,刚刚也说了阈值是通过学习效率和误差决定的,就不多说,这里说下权值的更新,公式是这样的
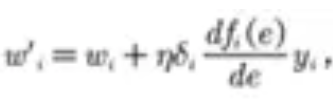
其中的e就是∑wi*yi ,就比如说f1节点的输入,dfi(e)/de就是fi(e)的导数,上文也讲到了激活函数必须是可导的,这就是原因,权值更新过程如下:

然后是再算一次误差 ,进行反向传播,如此循环,最后要么到了设定的最大训练次数 要么是误差达到了比如说小于 0.001,就停止了。
python实现BP神经网络
import numpy as np
class Bpnet():
def __init__(self,InputNode,HideNode,OutputNode,test_x,test_y,Learningrate):
self.input=InputNode
self.hide=HideNode
self.out=OutputNode
self.p=Learningrate
self.x=len(InputNode)
self.y=len(HideNode)
self.z=len(OutputNode)
self.test_x = test_x
self.test_y = test_y
self.value1=np.random.randint(-5,5,(1,self.y))
self.value2=np.random.randint(-5,5,(1,self.z))
self.w1 = np.random.randint(-5, 5, (self.x, self.y))
self.w2 = np.random.randint(-5, 5, (self.y, self.z))
def sigmoid(self,z):
return 1/(1+np.exp(-z))
def training(self):
for j in range(500):
for i in range(self.x):
inputset=np.mat(self.input[i]).astype(np.float64)
outputset=np.mat(self.out[i]).astype(np.float64)
input1=np.dot(inputset,self.w1).astype(np.float64)
output2=self.sigmoid(input1-self.value1).astype(np.float64)
input2 = np.dot(output2,self.w2).astype(np.float64)
output3=self.sigmoid(input2-self.value2).astype(np.float64)
a = np.multiply(output3, 1 - output3)
g = np.multiply(a, outputset - output3)
b = np.dot(g, np.transpose(self.w2))
c = np.multiply(output2, 1 - output2)
e = np.multiply(b, c)
v1_change=-self.p*e
v2_change=-self.p*g
w1_change=self.p*np.dot(np.transpose(inputset),e)
w2_change=self.p*np.dot(np.transpose(output2),g)
self.value1+=v1_change
self.value2+=v2_change
self.w1+=w1_change
self.w2+=w2_change
def test(self):
rightcount=0
for i in range(len(self.test_x)):
inputset = np.mat(self.test_x[i]).astype(np.float64)
outputset=np.mat(self.test_y[i]).astype(np.float64)
output2=self.sigmoid(np.dot(inputset,self.w1)-self.value1)
output3=self.sigmoid(np.dot(output2,self.w2)-self.value2)
if output3 > 0.5: flag=1
else : flag=0
if self.test_y[i] == flag : rightcount+=1
print("正确率:%d" %(rightcount/len(self.test_x)))
欢迎关注公众号 : 数学算法实验室















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









