









 本文是一份详细的AI图像生成开发教程,涵盖AI图像生成模型、大语言模型(如文心一言与StableDiffusion)的介绍,以及PaddleMIX在跨模态开发中的应用。教程通过实例演示如何使用这些工具进行艺术创作、游戏开发和应用开发,鼓励读者参与社区讨论并实践新技术。
本文是一份详细的AI图像生成开发教程,涵盖AI图像生成模型、大语言模型(如文心一言与StableDiffusion)的介绍,以及PaddleMIX在跨模态开发中的应用。教程通过实例演示如何使用这些工具进行艺术创作、游戏开发和应用开发,鼓励读者参与社区讨论并实践新技术。
AI图像生成开发教程

教程简介
经过几个月的实践与酝酿,AI图像生成开发系列教程,它来了。【AI图像生成开发教程】致力于用最通俗易懂的语言,为大家带来最好的教程,介绍AI图像的前世今生,结合图像生成模型、多模态模型、大语言模型以及各类便捷的语音合成等API,完成AI图像生成,并通过设计游戏类、应用类、AI艺术类实际案例,起到抛砖引玉的作用。打通AI生成模型与大语言模型共同创作的障碍,助力大家实现不同AI场景、AI应用的实现。
After several months of practice and preparation, a series of tutorials on AI image generation development have arrived. AI Image Generation Development Tutorial is committed to providing the best tutorials in the most user-friendly language, introducing the past and present of AI images. By combining image generation models, multimodal models, large language models, and various convenient speech synthesis APIs, we aim to complete AI image generation and design practical cases for gaming, application, and AI art, playing a role in attracting valuable insights. To overcome the obstacles of co creation between AI generation models and big language models, and help everyone achieve different AI scenarios and applications.
教程目录
第3课 AI图像生成开发教程之文心一言遇见Stable Diffusion
大家如对教程感兴趣或者有任何问题,可以在评论区留言,或者扫码加入我的社区专属频道。
| 社区频道 | 课程详情 |
|---|---|
 |  |
第1课 AI图像生成开发教程之认识AI图像生成模型

随着人工智能技术的飞速发展,图像生成技术成为了计算机视觉领域的研究热点之一。AI图像生成模型,也称为图像生成器,是利用深度学习和计算机视觉技术生成逼真、高质量图像的一类模型。本节将带领大家认识和理解AI图像生成模型的基本概念、原理和应用。

1 图像生成模型的前世今生
1.1 图像生成模型发展时间线
- 早期阶段(2014-2016)
-
2014年:生成对抗网络(GAN)被首次提出,奠定了深度学习生成模型的基础。
-
2015年:深度卷积生成对抗网络(DCGAN)问世,提高了图像生成的质量和分辨率。
- 发展阶段(2017-2020)
-
2017年:条件生成对抗网络(如CycleGAN和Pix2Pix)出现,可以根据输入图像进行风格转换和图像转换。
-
2018年:StyleGAN提出,生成了高质量、高分辨率的人脸图像,并引入了风格混合和渐进式增长等技术。
-
2020年:BigGAN问世,通过增加模型规模和改变训练方法,提高了生成图像的质量和多样性。
- 近期进展(2021年至今)
-
2021年:DALL-E模型被提出,可以根据文本描述生成对应的图像,展示了文本到图像生成的强大能力。
-
2022年:Stable Diffusion模型问世,结合了扩散模型和Transformer架构,实现了高质量的图像生成。
1.2 国内外比较优秀的AI生成模型网站和插件:
1.2.1 国内优秀网站和插件:
-
文心一言ERNIE-ViLG:百度推出的模型,具备跨模态理解能力,可以实现文本与图像的相互转换和理解。
-
文心一格:百度推出的图像生成工具,可以根据用户输入的关键词或句子生成符合要求的图像。
-
触站:提供高质量的插画作品和插画资源的交流平台。
-
数画:根据用户提供的文本或参考图像生成符合要求的数字绘画作品。
1.2.2 国外优秀网站和插件:
-
DALL-E API:OpenAI推出的图像生成工具,可以根据文本描述生成对应的图像。
-
Stable Diffusion:Stability AI推出的高质量图像生成模型,支持多种语言和风格。
-
Midjourney:根据用户提供的文本描述或草图生成高质量的图像。
-
TIAMAT:提供高质量的艺术作品和插画作品的交流平台。
-
Artbreeder:使用AI技术生成独特的艺术作品,并支持用户进行创作和交流。
-
Dream by Wombo:通过简单的文字描述或选择风格来生成艺术作品。
-
Prisma:将用户的照片转换为各种艺术风格的图像。
-
NightCafe Creator:使用AI技术将用户的草图转化为精美的艺术作品。
-
StarryAI:根据用户的文字描述生成独特的艺术作品。
-
ArtGenerator.io:使用GAN技术生成各种风格的艺术作品。
2 AI图像生成模型的基本概念
-
图像生成:指从现有数据集生成新的图像的任务。这些新生成的图像可以是与训练集相似的图像,也可以是全新的、未见过的图像。
-
生成模型:一种训练模型进行无监督学习的模型。给模型一组数据,希望从数据中学习到信息后的模型能够生成一组和训练集尽可能相近的数据。
-
图像生成模型:特指用于图像生成任务的生成模型。它们通过学习训练数据中的潜在分布,能够生成与训练数据相似的高质量图像。
3 AI图像生成模型的原理
-
生成对抗网络(GANs):通过一对互相竞争的神经网络——生成器和判别器,生成逼真的图像。生成器尝试生成看起来真实的图像,而判别器的工作是区分生成的图像和真实的图像。随着训练的进行,这两个网络会逐渐提高各自的性能,从而生成高质量的图像。
-
变分自编码器(VAEs):一种基于概率的生成模型,它通过编码和解码过程学习数据的潜在表示。与GANs不同,VAEs强调对生成图像的完整概率分布的建模,因此可以产生符合潜在分布的、无限数量的样本。
-
扩散模型:通过一系列逐步“混合”真实数据和生成的样本,来生成新的图像。这种模型的优点是可以产生高质量、高效率的图像,同时还能保持一定的创新性。
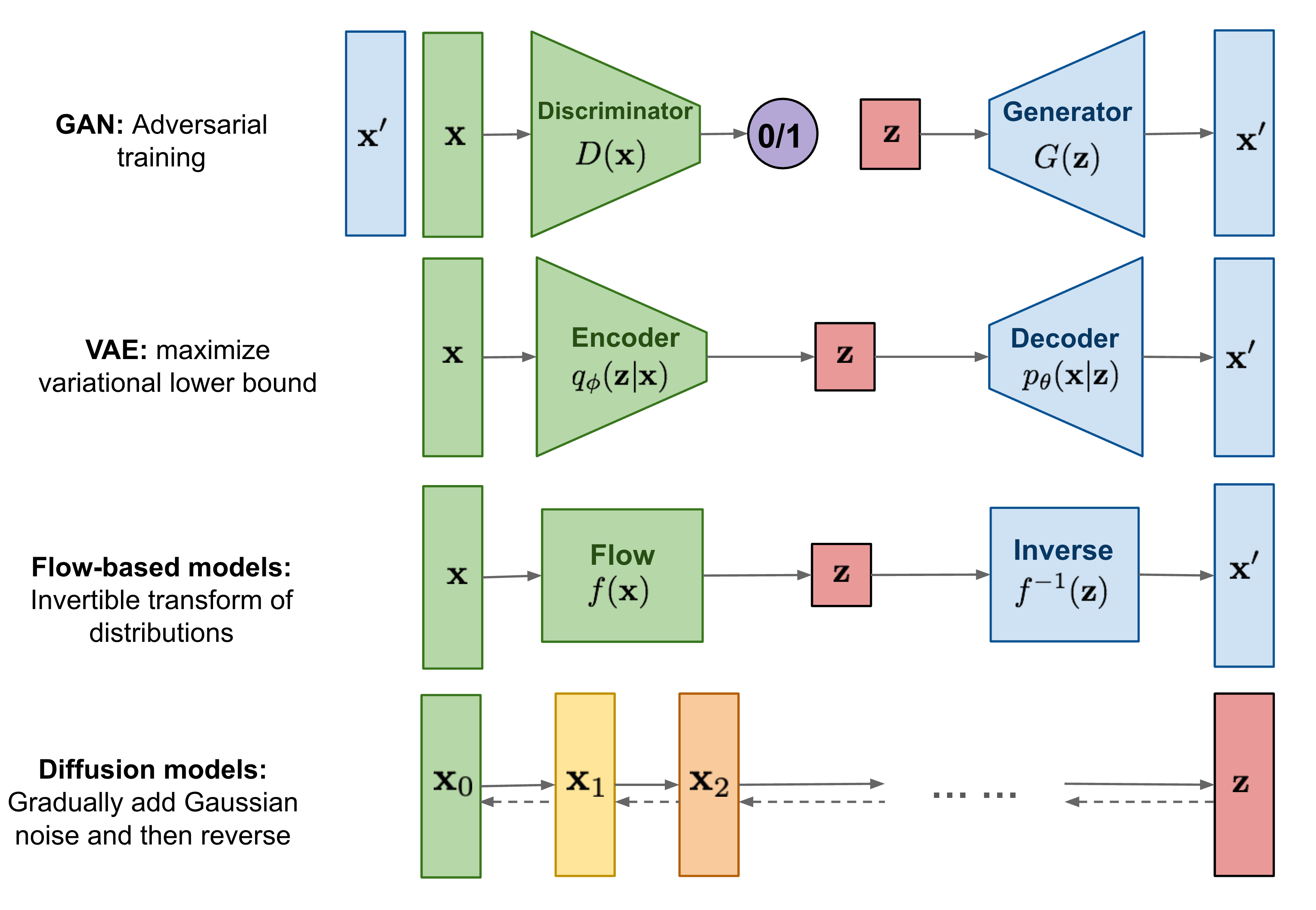
4 AI图像生成模型的应用
- 艺术创作:利用AI图像生成模型可以创作出独特的艺术作品,如风格转换、艺术风格迁移等。

- 视频制作和游戏开发:利用这些模型可以自动生成视频内容或游戏场景,提高制作效率和质量。

- 虚拟人物和虚拟场景:在电影、电视、广告等领域中,可以利用AI图像生成模型创建逼真的虚拟人物和虚拟场景,丰富视觉效果。

- 数据增强:在机器学习和深度学习任务中,可以利用AI图像生成模型扩充数据集,提高模型的泛化能力。

- 辅助设计:在建筑、工业、服装等领域中,可以利用这些模型辅助设计师进行设计创新和优化。
5 文心一格
文心一格是一款基于人工智能的图像生成工具,它可以根据用户的输入生成高质量的图像。本节将带领大家了解和使用文心一格,包括其基本概念、功能和使用方法。
5.1 功能介绍
-
图像生成:用户可以通过输入文字描述或选择风格来生成高质量的图像。
-
风格转换:用户可以将自己的图片转换为不同的艺术风格,如油画、素描等。
-
批量处理:用户可以一次性处理多张图片,提高工作效率。
-
高清输出:文心一格支持高清输出,用户可以根据自己的需求选择不同的分辨率。
5.2 使用方法
-
注册登录:用户需要先注册一个账号,并登录到文心一格的官方网站。
-
选择功能:根据自己的需求选择相应的功能,如图像生成、风格转换等。
-
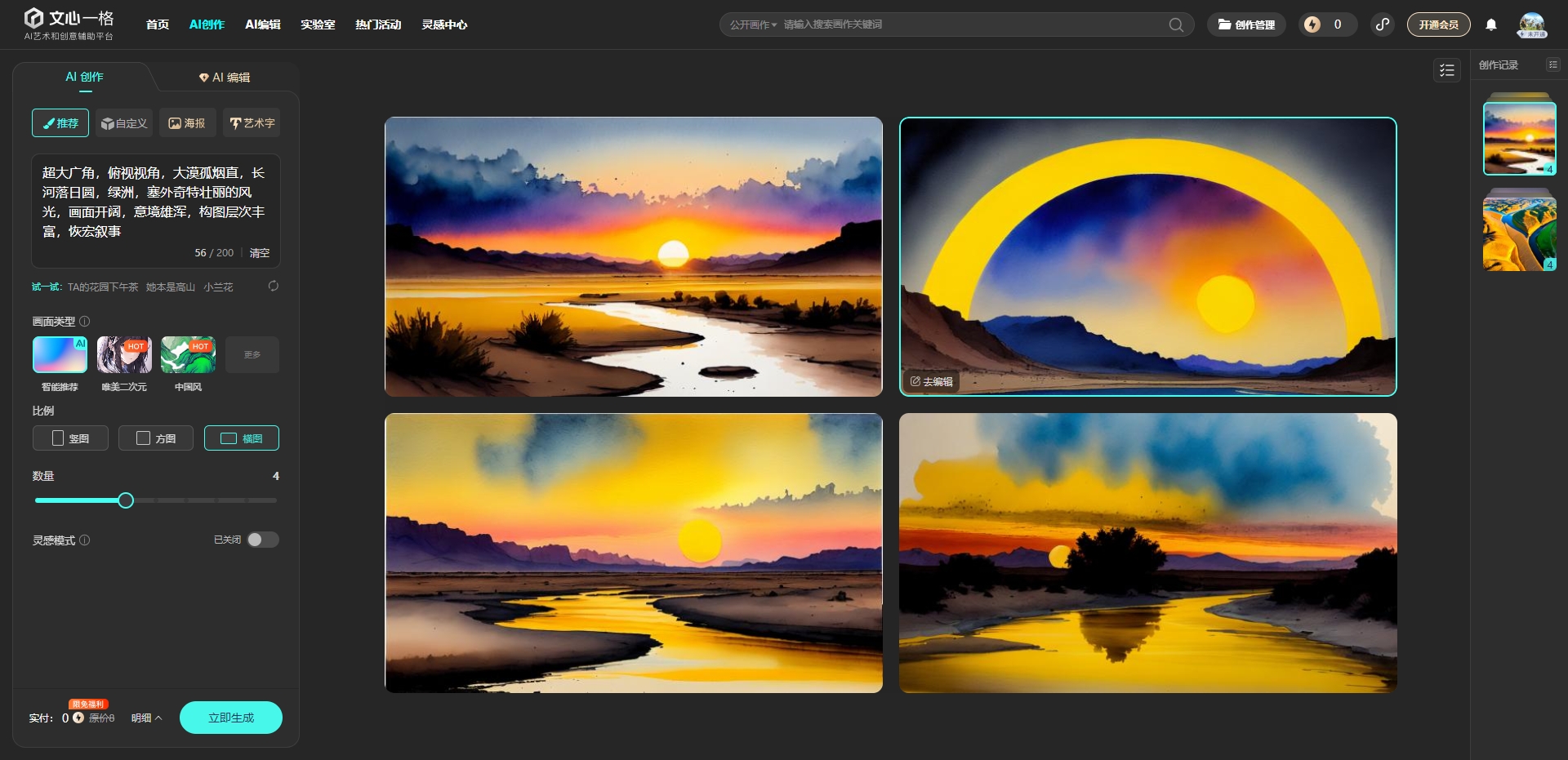
输入描述:如果选择图像生成功能,用户需要输入一段文字描述,如“超大广角,俯视视角,大漠孤烟直,长河落日圆,绿洲,塞外奇特壮丽的风光,画面开阔,意境雄浑,构图层次丰富,恢宏叙事”。
-
选择风格:如果选择风格转换功能,用户需要上传自己的图片,并选择想要转换的艺术风格。
-
等待生成:点击“生成”按钮后,文心一格会自动根据用户的输入生成相应的图像。这个过程可能需要一定的时间,请耐心等待。
-
下载保存:生成完成后,用户可以下载并保存生成的图像。如果需要高清输出,请在下载前选择相应的分辨率。
-
分享交流:用户可以将生成的图像分享到社交媒体或与其他用户进行交流。
效果如下图所示:
6 PaddleMIX
6.1 PaddleMIX简介
PaddleMIX是基于飞桨(PaddlePaddle)的跨模态大模型开发套件,聚合图像、文本、视频等多种模态,为开发者提供丰富的跨模态模型开发和应用的全流程功能。这个工具集能够帮助开发者在单一平台上快速实现跨模态大模型的训练、推理和应用,推动AI应用创新。
而ppdiffusers是PaddleMIX的前身,最初专注于扩散模型。随着技术的不断发展,ppdiffusers从PaddleNLP独立出来,专注于多模态的研究和应用。因此,ppdiffusers可以被看作是PaddleMIX的一个重要组成部分,它在多模态模型的开发和应用方面有着丰富的经验和能力。
总的来说,PaddleMIX和ppdiffusers都是基于飞桨平台开发的工具集,前者是一个功能丰富的跨模态大模型开发套件,后者则专注于多模态的扩散模型。这两个工具集在推动AI应用创新方面都起到了重要的作用。本教程所使用的套件和功能基于PaddleMIX、PaddleNLP及其他一些基础套件以及Ernie Bot SDK、百度翻译API、语音合成API等。
6.2 PaddleMIX安装
1. PaddleMIX环境安装
# !git clone https://github.com/PaddlePaddle/PaddleMIX.git -b develop
!unzip PaddleMIX.zip
# !unzip ~/data/data250540/nltk_data.zip
%cd ~/PaddleMIX
!pip install -e . --user
#ppdiffusers 安装
%cd ppdiffusers
!pip install -e . --user
2. 快速开始
%cd ~/PaddleMIX
!pip install -r paddlemix/appflow/requirements.txt
注:在开始运行下属代码前,切忌重启内核。
案例1 开放世界视觉模型
from paddlemix.appflow import Appflow
from ppdiffusers.utils import load_image
from PIL import Image
import numpy as np
task = Appflow(app="openset_det_sam",
models=["GroundingDino/groundingdino-swint-ogc","Sam/SamVitH-1024"],
static_mode=False) #如果开启静态图推理,设置为True,默认动态图
url = "https://paddlenlp.bj.bcebos.com/models/community/CompVis/stable-diffusion-v1-4/overture-creations.png"
image_pil = load_image(url)
result = task(image=image_pil,prompt="dog")
print(result)
案例2 文图生成(Text-to-Image Generation)
import paddle
from paddlemix.appflow import Appflow
from PIL import Image
import numpy as np
paddle.seed(1024)
task = Appflow(app="text2image_generation",
models=["stabilityai/stable-diffusion-v1-5"]
)
prompt = "a photo of an astronaut riding a horse on mars."
result = task(prompt=prompt)['result']
# 将结果转换为PIL Image对象并显示
image = Image.fromarray(np.uint8(result))
image.show()
| 示例1 | 示例2 | 示例3 |
|---|---|---|
 |  |  |
第1课 AI图像生成开发教程之认识AI图像生成模型就为大家讲解到这儿,如果对AI图像生成感兴趣或想了解AI图像生成技术,希望通过此教程能对大家有所帮助。有任何问题可以扫码加入我的社区频道,咱们一起探索AI图像生成的奇妙。从初始-遇见-相知过程很美好,希望课程的内容也是如何,你与我思维的碰撞亦是如此。敬请期待第2课 AI图像生成开发教程之认识AI大语言模型。

请点击此处查看本环境基本用法.
Please click here for more detailed instructions.















 6911
6911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









