







上一节,在WordCloud函数,并且发现,jieba分词效果更好,直接使得最终做的词云也更准确一些。
分词是自然语言处理(NLP)中最底层、最基本的模块,分词精度的好坏将直接影响文本分析的结果。有好多大型的分词系统(比如北京理工大学张华平博士开发的中文分词系统:ICTCLAS,是一个很优秀的分词系统),这里介绍Python中使用的小巧、强大的jieba中文分词。
首先获得jieba包:
pip3 install jieba
下载后,就能加载使用了。
jieba中文分词的三种常用模式
精确模式:试图将句子最精确地切开,适合文本分析;
全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
注:同时结巴分词支持繁体分词和自定义字典方法。
首先需要导入模块:import jieba
(1)、精确模式
>>> test = '小天于2014年毕业于北京大学'
>>> cut1 = jie.cut(test)
>>> cut1 = jieba.cut(test)
>>> type(cut1)
<class 'generator'>
>>> print('精确模式分词结果:',' '.join(cut1))
精确模式分词结果:小天于 2014 年 毕业 于 北京大学
这里的' '.join()函数指用空格分开cut1里面的元素,是个字符串连接函数。
举个小小的例子予以说明;
>>> a1 = 'abc'
>>> a2 = 'def'
>>> '/'.join(a1+a2)
'a/b/c/d/e/f'
如果加一个参数cut_all = False
>>> cut1 = jieba.cut(test,cut_all = False)
>>> print(' '.join(cut1))
可以看出cut_all = False这个参数加与没加都一样,它是个默认参数。
(2)、全模式
>>> cut1 = jieba.cut(test,cut_all = True)
>>> print('全模式分词结果:',' '.join(cut1))
全模式分词结果:小 天 于 2014 年 毕业 于 北京 北京大学 大学
显然,全模式不管分词后意思会不会有歧义,只管快速分出所有可能的词,不适合做文本分析。
(3)、搜索引擎模式
>>> cut1 = jieba.cut_for_search(test)
>>> print('搜索引擎模式分词结果:',' '.join(cut1))
搜索引擎模式分词结果:小天于 2014 年 毕业 于 北京 大学 北京大学
搜索引擎模式也会给出所有可能的分词结果,但是搜索引擎模式对于词典中不存在的词,比如一些很少见、新词,却能给出正确的分词结果。
简单文本分析朱自清写《匆匆》的情感状态
这是网上下载的《匆匆》原文:

由于Python不像R语言那样强大的可视化功能,R中还能画个词云什么的。所以,这里对《匆匆》里面每段话统计词频,取每段话词频最高的前五个词。导入必要的分次及词频统计包:
import jieba
import jieba.analyse
发现开始时候将朱自清这个大作家分开了,应该是一个完整的人名词。就要加入自定义词典:自己新建一个add_dict.txt文档,里面写上朱自清即可。以后遇到类似需要人工加词典,只需要每行放一个词即可。
注意:add_dict.txt默认ANSI编码,需要另存为utf-8编码格式;
import jieba
import jieba.analyse
path1 = 'D:\\Program Files\\python\\codes\\匆匆.txt'
#添加自定义词典,解决默认词典没有特殊词的问题
path2 = 'D:\\Program Files\\python\\codes\\add_dict.txt'
jieba.load_userdict (path2)
a = open(path1,'r')
dat = a.readline()
while(dat):
dat = jieba.cut(dat,cut_all = False)
print('/'.join(dat))
dat = a.readline()
a.close()
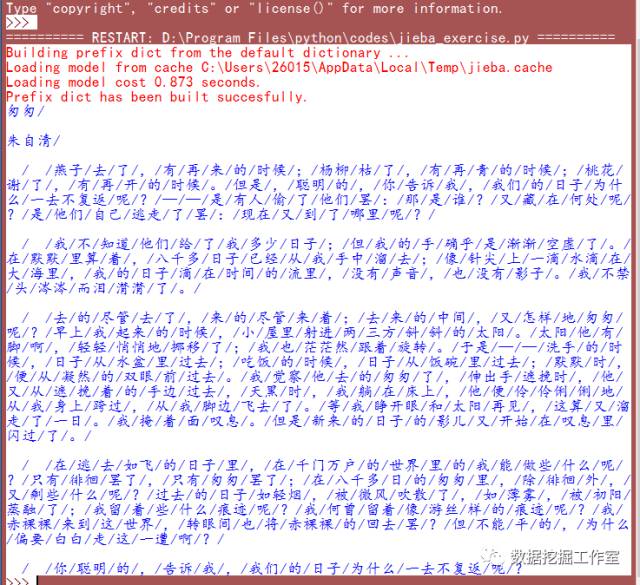
分词结果:
下面统计词频
import jieba
import jieba.analyse
path1 = 'D:\\Program Files\\python\\codes\\匆匆.txt'
#添加自定义词典,解决默认词典没有特殊词的问题
path2 = 'D:\\Program Files\\python\\codes\\add_dict.txt'
jieba.load_userdict (path2)
a = open(path1,'r')
dat = a.readline()
while(dat):
#提取前topK = n个关键词
tags = jieba.analyse.extract_tags(dat,topK = 5)
print(' '.join(tags))
dat = a.readline()
a.close()
分词并提取词语结果:
匆匆一去不复返 杨柳 桃花 燕子日子潸潸 里算 八千多 流里过去 太阳 日子 叹息 匆匆罢了一去不复返 聪明 日子 为什么 告诉
给我们反映的信息就是:
日子 过去 一去不复返 罢了
使用wordcloud做词云
这里先使用jieba分词,然后用分好的词来做词云:
from wordcloud import WordCloud as WC
import jieba
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
def wc():
# 读取小说内容
file = 'zhuziqing_congcong.txt'
with open(file, 'r', encoding='utf-8') as f:
content = f.read()
cut_content = jieba.cut(content.strip())
# 读取停用词
stopwords = stopwordslist('stopwords.txt')
outstr = ''
for word in cut_content:
if word not in stopwords and word != '\t':
outstr = outstr + word + " "
# 产生词云
wordcloud = WC(
font_path='C:/Windows/Fonts/simkai.ttf'
, width=1400
, height=700
).generate(outstr)
# 保存图片
wordcloud.to_file("congcong.jpg")
if __name__ == '__main__':
wc()
词云是这样的

情感状态
《匆匆》表达了作者对时间过去的感叹与无奈!
那么,NLP(自然语言处理)只需要分词就完了吗,把2篇文章分词后,怎么找到两篇文章的相似关系呢,一个个的词怎么存储,怎么计算,那么有没有什么好的办法呢?欢迎留言讨论。
猜你可能喜欢

















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











