






数据仓库系列文章
数仓—商业智能系统
数仓—AARRR海盗模型
数仓—总线矩阵
数仓—数据安全
数仓—数据质量
数仓—数仓建模和业务建模
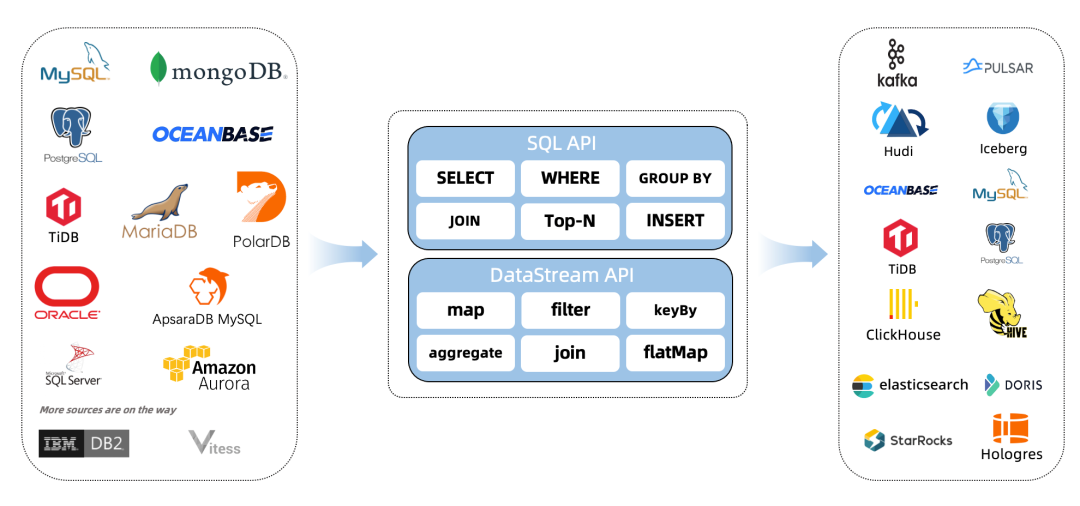
什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1. 环境准备
mysql
elasticsearch
flink on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
2. 下载下列依赖包
下面两个地址下载flink的依赖包,放在lib目录下面。
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-elasticsearch7_2.11/1.13.5/flink-sql-connector-elasticsearch7_2.11-1.13.5.jar
https://repo.maven.apache.org/maven2/com/alibaba/ververica/flink-sql-connector-mysql-cdc/1.4.0/flink-sql-connector-mysql-cdc-1.4.0.jar
这里flink-sql-connector-mysql-cdc,在这里只能下到最新版1.4:
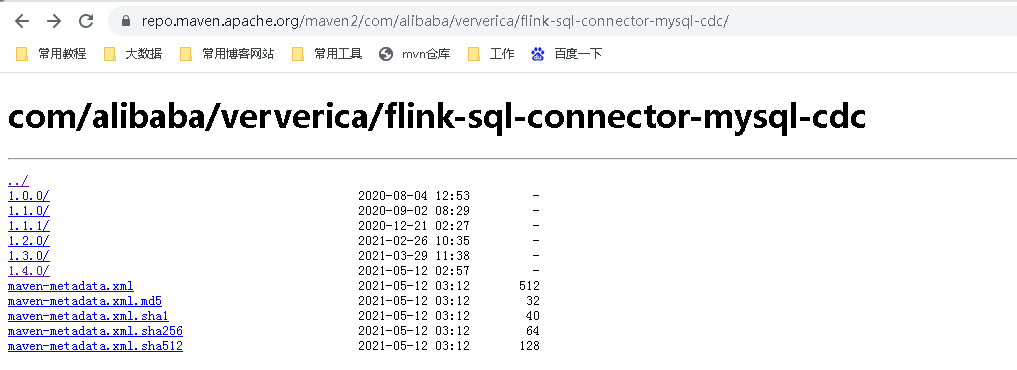
可以自行https://github.com/ververica/flink-cdc-connectors下载新版mvn clean install -DskipTests 自己编译。
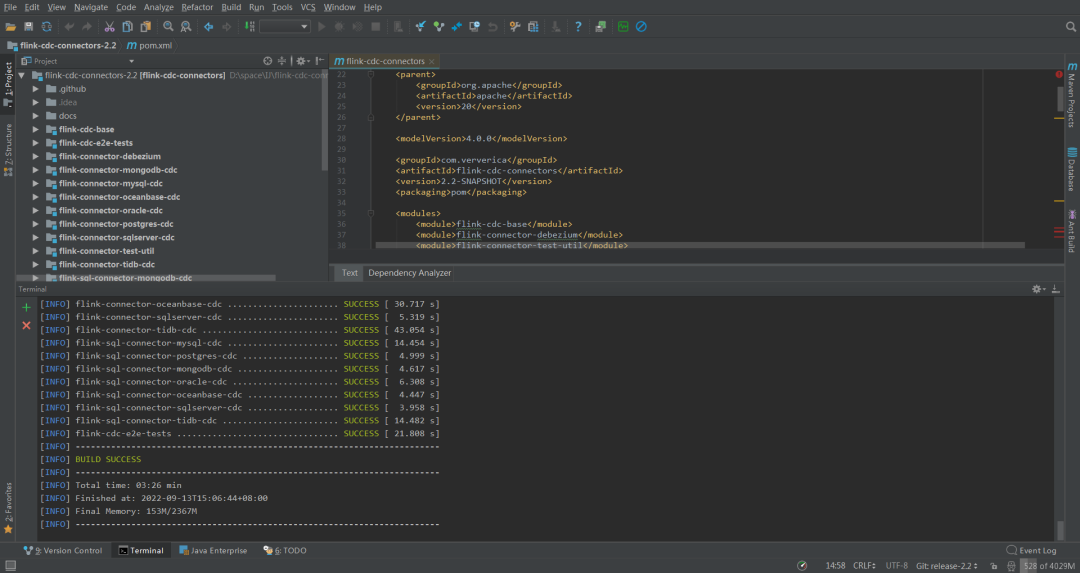
这是我编译的最新版2.2,传上去发现太新了,如果重新换个版本,我得去gitee下载源码,不然github速度太慢了,然后用IDEA编译打包,又得下载一堆依赖。我投降,我直接去网上下载了个1.4的直接用了。
我下载的jar包,放在flink的lib目录下面:
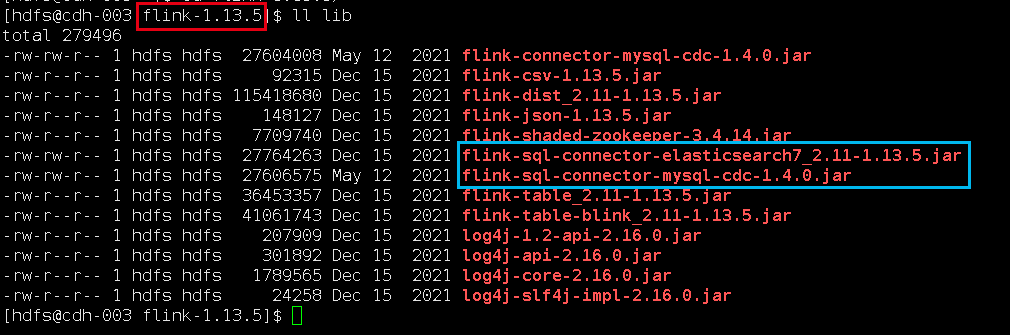
flink-sql-connector-elasticsearch7_2.11-1.13.5.jar
flink-sql-connector-mysql-cdc-1.4.0.jar3. 启动flink-sql client
先在yarn上面启动一个application,进入flink13.5目录,执行:
bin/yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -qu root.flink-queue-nm flink-cdc进入flink sql命令行
bin/sql-client.sh embedded -s flink-cdc
4. 同步数据
这里有一张mysql表:
CREATE TABLE `product_view` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) NOT NULL,
`server_id` int(11) NOT NULL,
`duration` int(11) NOT NULL,
`times` varchar(11) NOT NULL,
`time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`),
KEY `user_product` (`user_id`,`product_id`) USING BTREE,
KEY `times` (`times`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 样本数据
INSERT INTO `product_view` VALUES ('1', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('2', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('3', '1', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('4', '1', '1', '2', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('5', '8', '1', '1', '120', '120', '2020-05-14 13:14:00');
INSERT INTO `product_view` VALUES ('6', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
INSERT INTO `product_view` VALUES ('7', '8', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('8', '8', '1', '3', '120', '120', '2020-04-23 13:14:00');
INSERT INTO `product_view` VALUES ('9', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');创建数据表关联mysql
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.2',
'port' = '3306',
'username' = 'bigdata',
'password' = 'bigdata',
'database-name' = 'test',
'table-name' = 'product_view'
);这样,我们在flink sql client操作这个表相当于操作mysql里面的对应表。
创建数据表关联elasticsearch
CREATE TABLE product_view_sink(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.1.2:9200',
'index' = 'product_view_index',
'username' = 'elastic',
'password' = 'elastic'
);这样,es里面的product_view_index这个索引会被自动创建,如果想指定一些属性,可以提前手动创建好索引,我们操作表product_view_sink,往里面插入数据,可以发现es中已经有数据了。
同步数据
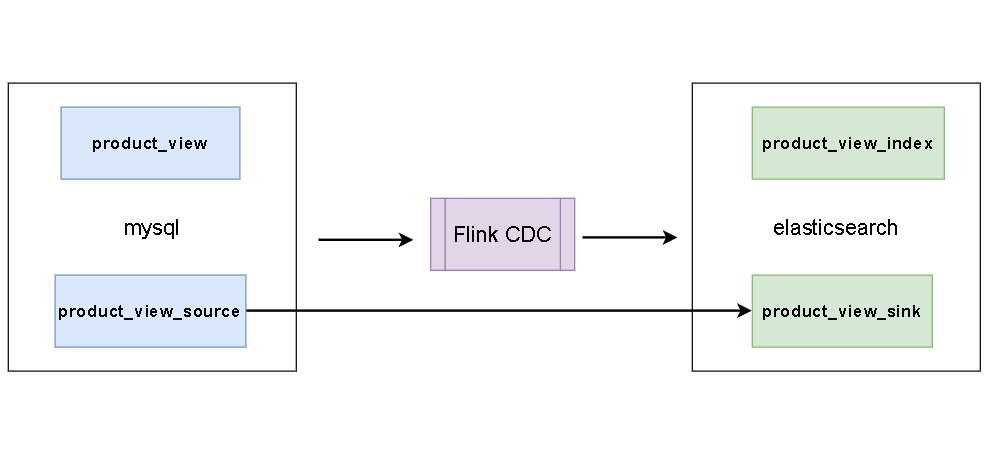
建立同步任务,可以使用sql如下:
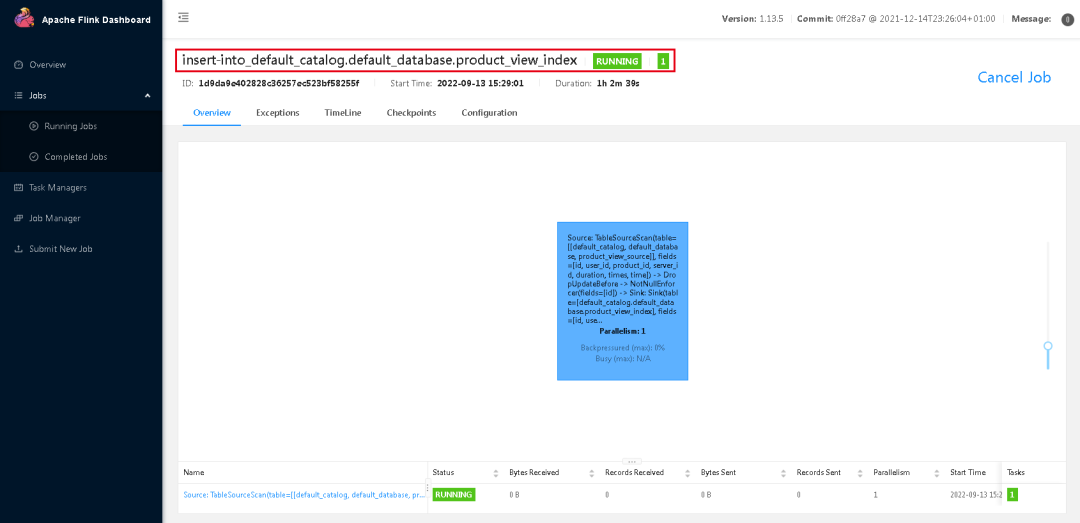
insert into product_view_sink select * from product_view_source;这个时候是可以退出flink sql-client的,然后进入flink web-ui,可以看到mysql表数据已经同步到elasticsearch中了,对mysql进行插入删除更新,elasticsearch都是同步更新的。
5. 连接器参数
下面连接器参数是官方给出的,文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/table/elasticsearch/
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (none) | String | 指定要使用的连接器,有效值为:elasticsearch-6:连接到 Elasticsearch 6.x 的集群。elasticsearch-7:连接到 Elasticsearch 7.x 及更高版本的集群。 |
| hosts | 必选 | (none) | String | 要连接到的一台或多台 Elasticsearch 主机,例如 'http://host_name:9092;http://host_name:9093'。 |
| index | 必选 | (none) | String | Elasticsearch 中每条记录的索引。可以是一个静态索引(例如 'myIndex')或一个动态索引(例如 `'index-{log_ts |
| document-type | 6.x 版本中必选 | (none) | String | Elasticsearch 文档类型。在 elasticsearch-7 中不再需要。 |
| document-id.key-delimiter | 可选 | _ | String | 复合键的分隔符(默认为"_"),例如,指定为"将导致文档为KEY2$KEY3"。 |
| username | 可选 | (none) | String | 用于连接 Elasticsearch 实例的用户名。请注意,Elasticsearch 没有预绑定安全特性,但你可以通过如下指南启用它来保护 Elasticsearch 集群。 |
| password | 可选 | (none) | String | 用于连接 Elasticsearch 实例的密码。如果配置了username,则此选项也必须配置为非空字符串。 |
| failure-handler | 可选 | fail | String | 对 Elasticsearch 请求失败情况下的失败处理策略。有效策略为:fail:如果请求失败并因此导致作业失败,则抛出异常。ignore:忽略失败并放弃请求。retry-rejected:重新添加由于队列容量饱和而失败的请求。自定义类名称:使用 ActionRequestFailureHandler 的子类进行失败处理。 |
| sink.flush-on-checkpoint | 可选 | true | Boolean | 是否在 checkpoint 时执行 flush。禁用后,在 checkpoint 时 sink 将不会等待所有的 pending 请求被 Elasticsearch 确认。因此,sink 不会为请求的 at-least-once 交付提供任何有力保证。 |
| sink.bulk-flush.max-actions | 可选 | 1000 | Integer | 每个批量请求的最大缓冲操作数。可以设置为'0'来禁用它。 |
| sink.bulk-flush.max-size | 可选 | 2mb | MemorySize | 每个批量请求的缓冲操作在内存中的最大值。单位必须为 MB。可以设置为'0'来禁用它。 |
| sink.bulk-flush.interval | 可选 | 1s | Duration | flush 缓冲操作的间隔。可以设置为'0'来禁用它。注意,'sink.bulk-flush.max-size'和'sink.bulk-flush.max-actions'都设置为'0'的这种 flush 间隔设置允许对缓冲操作进行完全异步处理。 |
| sink.bulk-flush.backoff.strategy | 可选 | DISABLED | String | 指定在由于临时请求错误导致任何 flush 操作失败时如何执行重试。有效策略为:DISABLED:不执行重试,即第一次请求错误后失败。CONSTANT:等待重试之间的回退延迟。EXPONENTIAL:先等待回退延迟,然后在重试之间指数递增。 |
| sink.bulk-flush.backoff.max-retries | 可选 | 8 | Integer | 最大回退重试次数。 |
| sink.bulk-flush.backoff.delay | 可选 | 50ms | Duration | 每次回退尝试之间的延迟。对于 CONSTANT 回退策略,该值是每次重试之间的延迟。对于 EXPONENTIAL 回退策略,该值是初始的延迟。 |
| connection.max-retry-timeout | 可选 | (none) | Duration | 最大重试超时时间。 |
| connection.path-prefix | 可选 | (none) | String | 添加到每个 REST 通信中的前缀字符串,例如,'/v1'。 |
| format | 可选 | json | String | Elasticsearch 连接器支持指定格式。该格式必须生成一个有效的 json 文档。默认使用内置的 'json' 格式。更多详细信息,请参阅 JSON Format 页面。 |
参考资料
https://ververica.github.io/flink-cdc-connectors/master/content/about.html
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/table/elasticsearch/
















 1833
1833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











