







本文为下面两本书的读书笔记。
Assemblers And Loaders.pdf - Free download books
Linkers and Loaders Mirror (wh0rd.org)
一、概述
1、程序”一生“
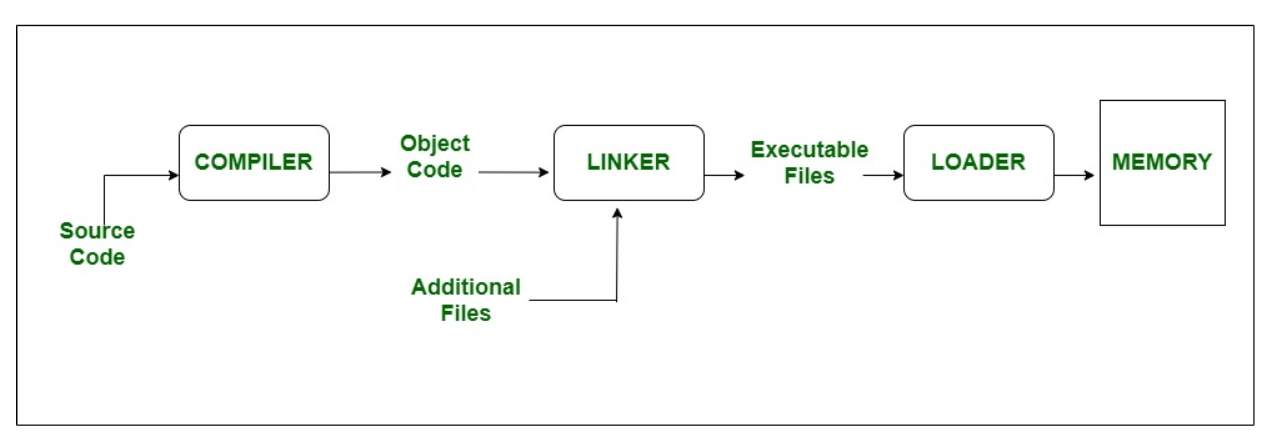
从用编程语言(C、汇编等)完成程序,到机器执行程序的过程一般是:编译、链接、加载。编译生成目标文件、和其他目标文件或库进行链接生成可执行文件,最后被加载到内存中执行。
这些过程可以大体分成两步:
编译就是“翻译":输入一个源文件,输出一个目标文件。它将编程语言这种能被人类理解的语言,翻译成目标代码这种能被机器理解的”语言“。目标代码是机器码的一部分,它就是01串,但不能直接在机器上实际运行,因为还不够完整。
链接、加载则是“修缮”目标文件:链接输入目标文件(可能包含库),输出可执行文件(把输入的目标文件修改打包);加载输入可执行文件,输出被加载的程序。本质上链接和加载都在对目标文件进行修改、补充使其能够运行。
2、再说编译
关于编译器的开发逻辑,一般是“迭代增量开发”,从这个角度可以看到程序语言的发展历史。
机器能执行的“语言”是机器码,所以直接书写机器码可以在机器上运行。
机器码太过具体,限制了人类编写更加复杂的例程,因为涉及的细节太过庞大。这时需要一个抽象一些的语言,既能够容易地翻译成机器码,又具备抽象性隐藏部分细节,它就是汇编语言。使用汇编语言来编程意味着需要能够翻译自身的翻译器,而这个翻译器只能使用机器码完成(现在咱只有机器码)。通过这个翻译器,汇编语言程序能够经过翻译得到机器码,在机器上加载运行。
汇编语言虽然具备一定抽象性,但随着操作系统等复杂软件系统的实现需求,用这种低级语言仍然很困难,因此出现了更加抽象的高级语言,如Fortran语言、C语言等。同样的,使用高级语言编程需要能够翻译自己的翻译器,同理,使用低级语言实现这样的翻译器。这个翻译器可以将高级语言程序转换成低级语言程序 ,再转换成机器码分两步走(第二步已经实现),也可以一步到位直接生成机器码。
总结来看,使用存在翻译器的程序语言来实现新语言的翻译器,使得新语言程序能够得以翻译运行。特别的,机器码不需要翻译器,所以理论上可以用机器码实现一切,当然只是理论上。
二、编译
编译包含五个阶段:词法分析、语法分析、语义分析、中间代码优化、目标代码生成。其中,前三者称为前端,中间代码优化称为中端,目标代码生成称为后端。前端的过程和算法十分成熟,大同小异;中端的中间代码优化涉及多种算法,中间代码结构也可分层,充满技巧;后端的目标代码生成和运行机器息息相关,因为目标代码就是机器码的一部分。
| 阶段 | input | output |
|---|---|---|
| 词法分析 | 高级语言编写的源程序 | 单词序列 |
| 语法分析 | 单词序列 | AST/语法序列 |
| 语义分析 | AST | 中间代码 |
| 中间代码优化 | 中间代码 | 中间代码 |
| 目标代码生成 | 中间代码 | 目标代码 |
三、汇编
1、汇编语言
汇编语言程序一般包含:指令(instr)、伪指令(directive)、宏(macro)。指令在汇编后翻译成机器码,最终会执行的。伪指令则是用来指导汇编过程、链接过程、加载过程进行的。宏则是以符号定义指令序列,并且可以带参数。
1)指令
汇编指令一般包含4个域(field):符号label,操作符mnemonic(operation),操作数oprand,注释comment。
loop: add $1, $8, $9 #loop is the label, add is the mnemonic, 1/8/9 is the oprands, now is the comment integer: .word 4 #.word is mnemonic, the line is a directive j loop #j is the mnemonic, loop is the operand, no label here
2)伪指令
伪指令用来指示汇编过程、加载过程,种类繁多,用途广泛。详细伪指令可参考Assemblers And Loaders中DIRECTIVE一章。
3)宏
宏是用符号来代替字符串,一般包括宏定义和宏扩展,且支持嵌套定义和嵌套扩展(通过栈,扩展中遇到新的扩展则扩展新的后继续原扩展)。
宏最关键的性质是支持参数,可以像函数一样传递参数,宏定义时的形式参数(parameter),宏扩展时的实际参数(arguement)。
宏的定义放在MDT中(macro definition table),一般通过pass 0(第0遍扫描)来收集所有的宏定义(嵌套宏定义只收集最外层名字/定义,内部当作字符串存储在MDT中),并处理所有的宏扩展(扩展过程中若有新的定义则加入MDT后继续原扩展)。实现算法可参考Assemblers And Loaders中MACRO一章。
2、符号
汇编语言能够被人类所理解,主要原因是包含符号。
计算机执行一般程序主要操作的就是地址和数据,因此机器码的含义包含操作和操作数(数值、地址)。数值和地址处理直接出现在汇编语言中,更灵活的通过符号出现。比如定义一个符号(比如指令的label域),其余指令可以引用该符号来使用它代表的数值或地址。
符号映射到高级语言就是变量、过程、函数。
符号的定义可以通过指令,可以通过伪指令。
LC #location counter 0 loop: add $1, $8, $9 #the value of loop is 0 4 integer: .word 4 #the value of the integer is 4 8 j loop
上面的LC是位置计数器,用来计算每个指令的相对主LC位置的地址。
LC可以有多个,每个LC独立计数,比如text的LC和data的LC分别对应目标文件的text节,data节。LC的切换通过在汇编文件中USE伪指令。

3、符号解析(resolve)和重定位(relocation)
解析符号:汇编语言中的符号是机器不能理解的,因此通过汇编将符号引用翻译成符号被定义的地址和数值。符号表用来存储符号的定义。符号表项一般包含符号名name,符号值value,符号是否定义type。
重定位:并非所有符号都在汇编过程被解析(符号定义可能来自其他目标文件或库,导致解析可能放到链接过程),且程序运行地址一般目前无法确定(可能需要加载时重定位),因此目标代码涉及到的地址、数值可能需要修改,这个过程就是重定位。
链接、加载、运行时进行的重定位,需要回答两个问题:哪条指令需要修改?修改成什么?如何修改?
回答由汇编过程产生的重定位表给出。重定位项一般包含对应的目标代码指针,所引用的符号/段指针,重定位类型。目标代码指针(where)给出要修改的目标代码,引用符号/段指针(what)告知该代码涉及到的符号/段从而提供修改的“材料”(由于符号/段的值更新导致重定位),重定位类型(how)指导如何进行修改。
重定位类型取决于重定位发生的时间和目标代码的寻址方式。
可能发生的重定位场景:
-
未解析的符号找到了定义
-
链接时节的合并,各个目标文件中的节的初始地址改变(不再为0)。
-
程序运行地址加载时才能确定,因此加载时可能重定位。
-
。。。。
可能的代码的寻址方式:
-
直接寻址:指令包含符号的全部或部分值,符号值改变需重定位。
-
pc相对寻址:同节的引用不需重定位(链接等操作不“拆节”),跨节的引用需要重定位(由于节的间距改变导致引用和自己的相对距离改变)。
-
基地址寻址:一般无需处理,寄存器和offset都是确定的数,无从重定位(除非offset由于某些原因可能改变)。
-
。。。。。
4、汇编过程
汇编输入汇编程序文件,主要输出目标文件(目标代码、重定位表、符号表等),根据不同要求生成额外内容(比如listing file),指令到目标代码通常是一对一的。
汇编过程分为多种,这里主要介绍一遍式汇编和两遍式汇编。但不管方式如何,汇编过程需要生成符号表管理符号信息,用于解析符号。
1)一遍式
扫描指令(LC自增)时,既添加符号的定义到符号表(if存在符号定义),也把指令翻译成机器码加载到内存。这里需要注意的是先引用符号后定义符号的情况,引用时就添加该符号,但其value指向该指令以便找到定义之后修改,其type为U(未定义,找到定义后改为D)。多个引用在前一个定义在后的情况可采用链表结构。

一遍式主要优势在于轻便快速且生成目标代码直接加载到内存,不会进行链接等操作,一般也不支持宏和很多和链接加载相关的伪指令。
2)两遍式
第一遍扫描主要对于所有符号定义构建符号表,第二表扫描主要解析符号生成目标代码到目标文件。不同于一遍式,两遍式可以支持更多功能(宏,更多伪指令),且一般需要链接加载到内存执行。
两遍扫描可以提供更大的自由度以支持更强大的功能,下面以多LC的实现为例介绍伪指令在两遍之间的协调合作。
第一遍扫描遇到USE时,会将其定义的LC符号加入符号表(name,value,type);第二遍扫描将所有的USE换成相应的加载伪指令来指导链接加载过程的进行,并切换LC继续翻译。

上图在汇编文件中被分成了7部分,第二遍结束后链接加载伪指令展示了每个部分的所属节及其地址。加载时可按照main、data、beta、gamma的顺序或1、3、6、2、5、4、7的顺序。
以上只是一个逻辑过程,真实细节取决于具体数据结构,比如ELF的可重定位文件其实完成了上述的“加载”,将节规整好。
四、链接和加载
链接和加载是关系较紧密的两个过程,因此放在一起讨论。
链接把输入的目标文件中相同的节合并成段,进行符号解析和重定位,生成一个可执行文件用于加载运行。

链接过程通常是两遍。
Pass 1
收集每一个目标文件的引入符号(引用外部定义的符号)、导出符号(全局可见的符号)(汇编程序通过伪指令EXTRN、ENTRY声明),构建全局的符号表来进行全局符号的解析。当然各自的符号表也可能用于重定位。
各自符号表

全局符号表

同时,链接过程收集目标文件的所有节信息来进行段布局用于重定位以及生成可执行文件。
Pass 2
扫描所有目标代码依据其重定位项和第一遍收集的符号、段信息进行重定位。
链接过程可以假设生成的可执行文件加载的地址:
-
对程序运行地址固定的程序(存在虚拟内存),使用该固定地址对链接时的进行重定位,如此加载时不再需要重定位。
-
对程序运行地址无法确定的情况,假设从零开始,并生成重定位信息用于加载时根据实际运行地址来修改代码,运行。
五、库
很多功能函数定义了好的输入输出接口并生成目标文件被打包成库,可以直接用来使用,也就不用重复造轮子。
1、静态库
静态库就是很多目标文件的集合。在自己的程序中引用对应模块,程序链接的过程就会在所有库中搜寻直至找到其所在库并链接该模块。链接该模具时还可能遇到其依赖的别的模块,重复上述。
2、静态共享库
详情参见Linkers and Loaders中SHARED LIBRARIES一章
1)动机
静态库的模块是被链接进目标代码中生成可执行文件,但当相同的模块参与了多个目标文件的链接,该模块就在内存中重复多次,造成浪费。由此出现了共享库。
2)共享原理(虚拟内存)
每个程序有自己的独立地址空间,由OS负责为地址空间分配物理页面,也就是地址映射。
对于库模块的text段页面,因为其只读,所以可以将其物理页面映射到多个地址空间。
但是对于data段等可写的页面,不能简单的映射,而采用COW(写时复制)机制。COW,即在程序没有试图修改data段之前,data页面都被映射进程序地址空间,当程序试图写data段页面(比如虚页A,对应实页PA)时,OS分配新的物理页面(比如PB)来映射该将要被写的data段页面(A),从此data段页面(A)可以自由读写。
该原理本质在于:程序执行依靠虚拟地址,页面复制前后,data段页面的虚拟地址并没有改变。
3)共享库的链接和运行
首先明确静态共享库的加载地址是固定的,放在程序地址空间的最上方,同用户程序空间分开。因此静态共享库是不需要加载重定位的,由于其地址确定,链接时也不需要对静态共享库模块进行重定位。
共享库包含一个存根库(stub library),它包含共享库中导入和导出符号的定义,同链接时目标文件提供的符号表和导入导出符号类似,不同的是这里不需要其本地的符号表。这些导入导出符号的定义会在引用该库的程序进行链接时参与程序的符号解析和绑定(全局符号表的构建)。通俗的说,存根库参与程序的链接的pass 1。
程序执行时需要做共享库的地址映射,这个工作不同系统实现不同,可以通过在引用共享库的程序中添加一段代码执行,也可以由OS执行这个工作。地址映射完成后,可能需要做一些库模块的初始化工作,取决于具体库模块。
4)共享库的不足
共享库的更新是一大问题,共享库的更新如果引起引用他的程序失效,则只能重新编译链接加载这些程序,但找出所有引用该库的程序是很困难的,所以这是个有严重后果的假设。
理想情况共享库的更新对引用它的程序透明,这需要两个约束:库在内存所占空间能满足更新,库导出符号的地址不变。前者很矛盾,一方面大一点可以保证由空间更新,另一方面不希望占用太多内存。后者包含导出的text符号值和data符号值都尽量不变。
对于导出的text符号,将他们的符号值统一放在一张表格(jump表,每个表项都是一个jump语句),并将该表项的地址作为其对应的导出符号值。这样所有引用导出符号的指令都会跳转到对应的jump语句,之后jump跳到目的地址。这样做的好处是任何导出text符号的实际值可以改变,但不会影响其被其他程序“看见”的值(stub lib中展现的)。

对于导出的data符号,由编程者保证导出的符号值不变:确保导出符号大小固定且符号值很少改变。有一个技巧是把导出的符号放在data段前面,这样后面的局部data符号改变不会影响前面的导出符号。
5)共享库的编写(这里直接看原文吧)
Determine at what address the library’s code and data will be loaded.
Scan through the input library to find all of the exported code symbols. (One of the control files may be a list of some of symbols not to export, if they’re just used for inter-routine communication within the library.
Make up the jump table with an entry for each exported code symbol.
If there’s an initialization or loader routine at the beginning of the library, compile or assemble that.
Create the shared library: Run the linker and link everything together into one big executable format file.
Create the stub library: Extract the necessary symbols from the newly created shared library, reconcile those symbols with the symbols from the input library, create a stub routine for each library routine, then compile or assemble the stubs and combine them into the stub library. In COFF libraries, there’s also a little initialization code placed in the stub library to be linked into each executable.
六、位置无关代码(PIC)
详情可参考Linkers and Loaders中Position-Independent Code一章
1、原理
PIC去除了text段中所有的直接地址寻址的指令,包括局部符号的实际地址和全局符号的实际地址。以ELF文件为例,每个可执行文件的text段和data段距离固定(每个程序的该距离都不一定一样,但链接之后该距离确定下来),因此可以通过pc加偏移的方式(pc就是运行时指令地址)确定data段位置,从而确定data中符号的位置访问这些符号值。

2、具体实现
PIC把程序中的所有全局符号的实际地址存储在GOT(global offset table)中,并把text段中所有的直接地址指令根据引用的符号是全局还是局部,分别换成通过GOT间接寻址和GOT基地址寻址。
1)GOT的运行地址
这里涉及到一个问题GOT的地址如何获得?根据开始说的依靠text段和data段距离固定来通过pc(运行时指令的地址)加上这段距离获得,具体的,
call .L2 ;; push PC in on the stack .L2: popl %ebx ;; PC into register EBX addl $_GLOBAL_OFFSET_TABLE_+[.-.L2],%ebx;; adjust ebx to GOT address
上面的代码在运行时获得了所在可执行文件的GOT表的运行时地址。其中$GLOBAL_OFFSET_TABLE是GOT的符号,在编译(包括汇编)后上面的addl指令对应一个类型为R_386_GOTPC的重定位项,该重定位项在链接时将该符号解析到GOT的链接后地址(可执行文件中的地址,此后指令和GOT的相对距离固定),从而该addl指令将该可执行文件的GOT的运行时地址放到寄存器ebx中。
存在GOT的可执行文件中的代码在调用函数时,目前存储GOT的运行时地址的约定寄存器需要保护,因为每个可执行文件的GOT是独立的,当调用其他的文件(也存在GOT)的函数时,该约定寄存器的值可能会被覆盖。
2)处理“直接地址”
现在我们得到了GOT的运行时地址,它保存在约定的寄存器中。下面来处理程序中剩余段中的直接地址:
text段中的引用局部符号和全局符号的直接寻址指令,通过两种重定位类型在链接时处理:R_386_GOT32、R_386_GOTOFF。(这两个重定位类型都是构造PIC的链接过程使用的)
data段中的直接地址,通过R_386_RELATIVE来指导进行加载时重定位。
假设有如下C代码:
static int a; /* static variable */ extern int b; /* global variable */ ... a=1; b= 2;
a=1被编译成如下指令:
movl $1,a@GOTOFF(%ebx);; R_386_GOTOFF reference to variable "a"
movl的重定位类型为GOTOFF,因此符号a被重定位为data段符号a和GOT之间的距离。如此movl通过基地址寻址完成对a的访问。
b=2被编译成如下指令:
movl b@GOT(%ebx),%eax;; R_386_GOT32 ref to address of variable "b" movl $2,(%eax)
movl的重定位类型为GOT,因此符号b被重定位其在GOT中的相对地址(下标),通过第一个movl来从b的GOT项取出b的运行地址(这里暗示GOT需要加载时重定位、解析),再对该地址指向的内存进行存取。
PIC只保证text段可以无需加载时重定位,但data中的GOT和其他直接地址仍然需要加载重定位,后者就通过类型为R_386_RELATIVE的重定位项来标记。
2、优劣
1)优势
PIC的text段不需要加载重定位。
位置无关代码解决了目标文件(运行地址不确定)需要大量加载时重定位的问题,主要用于动态共享库,解除了静态共享库对目标文件确定加载地址的限制。
2)劣势
需要占用一个寄存器保存GOT运行时地址。
调用函数时开销增加,需要维护GOT的运行时地址。
PIC在加载之后仍然需要进行data段的重定位,主要集中在GOT中和data段的直接地址。
七、动态链接
详情可参考Linkers and Loaders中DYNAMIC LINKING AND LOADING一章
动态链接指把符号的绑定和库对可执行文件的绑定推迟到运行时。这里的动态共享库都是PIC。
常规情况在链接时完成这些工作,虽然时机不同,但要做的仍然是对程序和动态共享库进行“链接”:动态共享库的加载(也就是PIC的重定位),程序和动态共享库的链接(程序的动态段提供程序连接所需信息)。这里程序不需要加载重定位,因为存在虚拟内存,地址空间独立,加载地址早已确定。
0、ELF动态共享模块逻辑结构
程序头是整个文件的目录,记载“主干”的位置信息。
hash、dysym,dynstr三个段是动态符号表,hash用于快速查找,dysym为符号项(不包含名字),dynstr则为名字。
text段中的函数调用都指向plt段。
dynamic段提供动态链接器需要的所有信息。

1、动态链接
”Pass 1“
OS加载可执行文件时发现INTERPRETER段,这就是动态链接器ld.so。OS首先加载这个动态链接器,并将程序运行前需要的信息传递给链接器。这些信息包括:程序头(该可执行文件的“目录”),程序的启动地址(第一个执行的指令地址),链接器自身的加载地址。
动态链接器执行自己的启动代码,找到自己的GOT(第一项为其动态段),接着找到动态段,进行自身的重定位和符号解析,并开始构建全局符号表(和常规链接时的全局符号表一样的作用)。
之后ld按照程序的动态段提供的需要模块及库的信息,依次加载它们,将其符号表添加进全局符号表。
此时程序全部依赖的动态库完成加载和地址映射,全局符号表构建完成。到这里其实完成了常规链接过程的pass 1。
后面对程序和共享库进行符号解析和重定位。也就是进行pass 2。
“Pass 2”
此时共享库的重定位有四种类型:
-
R_386_GLOB_DAT, used to initialize a GOT entry to the address of a symbol defined in another library.来自外部的全局符号解析
-
R_386_32, a non-GOT reference to a symbol defined in another library, generally a pointer in static data.来自外部的局部符号解析
-
R_386_RELATIVE, for relocatable data references, typically a pointer to a string or other locally defined static data.自身的局部符号地址重定位
-
R_386_JMP_SLOT, used to initialize GOT entries for the PLT, described later.指向对应PLT项的指针。
完成对共享库的重定位、解析之后,再利用程序的动态段和全局符号表对程序进行重定位和解析。由此完成pass 2。
回顾一下,GOT是程序运行时依赖的数据结构,而全局符号表和动态段是链接过程进行重定位和符号解析依赖的数据结构。
2、延迟绑定
1)背景
PIC中外部函数的地址存放在GOT中,而其定义的查找可能会很慢(大量的函数定义),这进一步拖慢了共享模块解析符号,重定位的速度。为了改善这一点,将外部函数的地址解析推迟到其被调用时进行,也就是延迟绑定。那么现在对外部函数的调用通过什么呢?通过跳转到模块中对应的的PLT项执行。PLT(procedure linkage table)本身是PIC,包含在动态模块的text段中。(如果是本地全局函数,加载时就能重定位)
2)具体实现
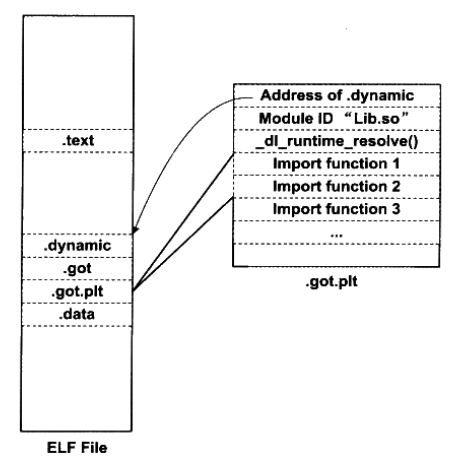
ELF将GOT拆分成两个表".got"和"".got.plt"。其中"".got"用来保存全局变量的引用地址。".got.plt"用来保存函数引用的地址,也就是说,所有对于外部函数的引用全部被分离出来放到了 ".got.plt"中。另外 ".got.plt"还有一个特殊的地方就是它的前三项是有特殊意义的,分别含义如下:
-
第一项保存的是 ".dynamic" 段的地址
-
第二项保存的是本模块的ID
-
第三项保存的是_dl_runtime_resolve()的地址,用于解析下面的外部函数的符号(进行绑定)。
其中第二项和第三项由动态链接器在加载共享模块的时候负责将它们初始化。".got.plt"的其余项分别对应每一个外部函数的引用。
PLT的内容如下,
Special first entry #特别的第一项,压入自己的模块名,跳转到函数引用解析例程 PLT0: pushl GOT+4 #GOT中第二项,就是caller所在模块名。 jmp *GOT+8 #跳转到解析器 Regular entries, non-PIC code: #非PIC版本 PLTn: jmp *GOT+m push #reloc_offset jmp PLT0 Regular entries, PIC code: #PIC版本 PLTn: jmp *GOT+m(%ebx) #第一次执行等价于nop,之后跳向函数实际地址 push #reloc_offset #压入函数名 jmp PLT0
3)整个过程
第一次调用外部函数时,跳转到相应的PLTn项,执行其代码段:
PLTn:jmp *GOT+m(%ebx) 被第一次调用时不会产生结果(跳到相邻指令),因为其目标地址存在函数对应的GOT项中,而该GOT项初始化为jmp(本指令)的下一条指令:push #reloc_offset。
push #reloc_offset 被执行,压入函数符号。这里对应一个类型为R_386_JMP_SLOT的重定位项,加载时重定位为函数符号项(符号表中)。
jmp PLT0 被执行,跳转到PLT0。
PLT0: pushl GOT+4 被执行,压入函数所在模块。作为参数传递给解析例程,方便找到定义后定位该模块的GOT,进行函数符号绑定。
jmp *GOT+8 被执行跳转到解析器。此时栈中从顶开始,依次是:模块名,函数名,调用者的返回地址。
解析例程保存所有寄存器,并在符号表中查找函数定义,依据传递的模块对其GOT相应的项填充函数实际地址。
之后恢复寄存器,弹出PLT压入的两个参数,跳转到相应函数例程。
之后的该函数调用可以直接通过PLT的jmp跳转进入。
3、随用随加载
程序和动态库的结构基本一样,意味着程序可以在运行时才加载新的动态库并与之链接,并调用库的函数和数据。能这样做的原因在于延迟绑定。
八、回看
编译针对单个源文件进行翻译,生成目标代码文件。
链接、加载过程是程序设计(使得程序可以拆成多个源文件)、运行的手段,贯穿始终的就是由于代码序列的分散、重组和加载地址的不确定导致的符号解析和重定位。
库本质还是一堆目标模块,只是因为不同的用途有着不同的设计。
常规链接且只使用静态库的程序,符号被绑定到一个地址以及库模块被绑定到可执行文件中(打包在一起)都发生在链接过程,也因此链接过程可能有大量的重定位发生。
静态共享库的符号绑定仍然发生在链接时(使用库的存根stub lib来进行符号解析),但库模块和可执行文件的绑定在程序运行时才发生(COW机制)。
动态共享库的符号绑定以及库模块被绑定到可执行文件都在程序运行时发生运行时,甚至延迟绑定(lazy binding将函数调用的地址绑定推迟到调用)。
虽然分出来三种类型的库,但实际上蕴含的思想只有两个:共享和动态(运行时)。将二者结合在一起就是动态共享库,在linux中叫共享库,windows中叫动态链接库。















 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









