







基于PaddleHub预训练模型Senta完成情感分析预测(傻瓜式推理版)
基于PaddleHub预训练模型Senta完成情感分析预测(傻瓜式推理版)
情感倾向分析(Sentiment Classification,简称Senta)针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度,能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。
NOTE: 首先fork该项目示例。之后按照该示例操作即可。
senta_bilstm 模型链接:https://www.paddlepaddle.org.cn/hubdetail?name=senta_bilstm&en_category=SentimentAnalysis
环境:PaddlePaddle2.0.0rc PaddleHub2.0.0b1 senta_bilstm 1.2.0(最新版)
一、定义数据集
以”这家餐厅很好吃“,”这部电影真的很差劲“为例,展示如何如何使用Senta进行情感分析。
请在左边上传自己的数据文件(txt),数据格式:
这家餐厅很好吃
这部电影真的很差劲
二、更多模型选择
Senta开源了一系列,供用户选择:
- BOW(Bag Of Words)模型,是一个非序列模型,使用基本的全连接结构;关于该模型更多介绍, 查看PaddleHub官网介绍
- CNN(Convolutional Neural Networks),是一个基础的序列模型,能处理变长序列输入,提取局部区域之内的特征;关于该模型更多介绍, 查看PaddleHub官网介绍
- GRU(Gated Recurrent Unit),序列模型,能够较好地解决序列文本中长距离依赖的问题;关于该模型更多介绍, 查看PaddleHub官网介绍
- LSTM(Long Short Term Memory),序列模型,能够较好地解决序列文本中长距离依赖的问题;关于该模型更多介绍, 查看PaddleHub官网介绍
- Bi-LSTM(Bidirectional Long Short Term Memory),序列模型,采用双向LSTM结构,更好地捕获句子中的语义特征;关于该模型更多介绍, 查看PaddleHub官网介绍
以Bi-LSTM为例,展示预测如何完成。
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。
大家按自己的需求选择需要的模型
如果想尝试其他模型,只需要更换Module中的name参数即可.
| 模型名 | PaddleHub Module |
|---|---|
| BOW | hub.Module(name='senta_bow') |
| CNN | hub.Module(name='senta_cnn') |
| GRU | hub.Module(name='senta_gru') |
| LSTM | hub.Module(name='senta_lstm') |
| Bi-LSTM | hub.Module(name='senta_bistm') |
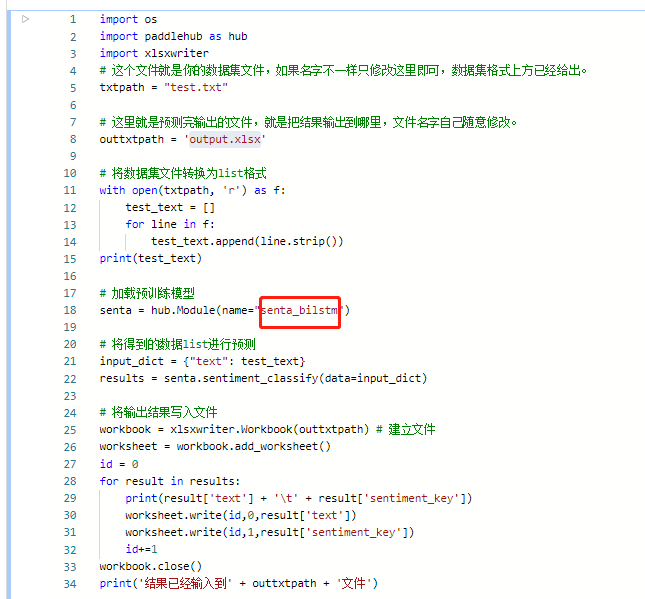
在下方代码中这个位置修改需要的模型名称即可
三、使用教程
1.修改下列变量txtpath = "test.txt"为自己需要的文件名称,或者将自己上传的文件改为test.txt。
2.修改下列变量outtxtpath = output.xlsx’为自己想要输出的文件名称,或者是默认为output.txt。
3.在右上方点击【运行】----【全部运行】
4.运行完毕之后会生成自己设置的outtxtpath文件,点击即可查看,本示例默认为output.xlsx。
四、修改并开始执行
!pip install paddlehub==2.0.0b1 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install xlsxwriter -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
import paddlehub as hub
import xlsxwriter
# 这个文件就是你的数据集文件,如果名字不一样只修改这里即可,数据集格式上方已经给出。
txtpath = "test.txt"
# 这里就是预测完输出的文件,就是把结果输出到哪里,文件名字自己随意修改。
outtxtpath = 'output.xlsx'
# 将数据集文件转换为list格式
with open(txtpath, 'r') as f:
test_text = []
for line in f:
test_text.append(line.strip())
print(test_text)
# 加载预训练模型
senta = hub.Module(name="senta_bilstm")
# 将得到的数据list进行预测
input_dict = {"text": test_text}
results = senta.sentiment_classify(data=input_dict)
# 将输出结果写入文件
workbook = xlsxwriter.Workbook(outtxtpath) # 建立文件
worksheet = workbook.add_worksheet()
id = 0
for result in results:
print(result['text'] + '\t' + result['sentiment_key'])
worksheet.write(id,0,result['text'])
worksheet.write(id,1,result['sentiment_key'])
id+=1
workbook.close()
print('结果已经输入到' + outtxtpath + '文件')















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









