







使用servlet和tomcat6,注意事项:
1,将lucene-core-2.9.0.jar复制到WEB-INF/lib
2,按照tomcat的要求组织好目录
3,编写好web.xml
4,编译产生的SluceneSearcher.class类拷到WEB-INF/classes/bservlet
web.xml配置如下:
<?xml version="1.0" encoding="GB2312"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
version="2.5">
<display-name>Welcome to Tomcat</display-name>
<description>
Welcome to Tomcat
</description>
<servlet>
<servlet-name>testsearch2</servlet-name>
<servlet-class>bservlet.SluceneSearcher</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>testsearch2</servlet-name>
<url-pattern>/deepfuturesou</url-pattern>
</servlet-mapping>
</web-app>
建立索引代码
package bindex;
import java.io.File;
import tool.FileText;
import tool.FileList;
import java.io.*;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import jeasy.analysis.MMAnalyzer;
import org.apache.lucene.store.LockObtainFailedException;
public class FileIndexer {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
String indexPath ="indexes";
try {
IndexWriter indexWriter = new IndexWriter(indexPath,new MMAnalyzer());
String[] files=FileList.getFiles("htmls");
int num=files.length;
for(int i=0;i<num;i++){
Document doc=new Document();
File f=new File(files[i]);
String name=f.getName();
String content=FileText.getText(f);
String path=f.getPath();
Field field=new Field("name",path+name,Field.Store.YES,Field.Index.TOKENIZED);
doc.add(field);
field=new Field("content",content,Field.Store.YES,Field.Index.TOKENIZED);
doc.add(field);
field=new Field("path",path,Field.Store.YES,Field.Index.NO);
doc.add(field);
indexWriter.addDocument(doc);
System.out.println("File:"+path+name+" indexed!");
}
System.out.println("OK!");
indexWriter.close();
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (LockObtainFailedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
搜索代码
package bservlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.*;
import org.apache.lucene.search.*;
import java.io.*;
public class SluceneSearcher extends HttpServlet {
private String indexpath="D:/workspace/testsearch2/indexes";
public void doPost(HttpServletRequest request,HttpServletResponse response){
StringBuffer sb=new StringBuffer("");
try {
request.setCharacterEncoding("GBK");
String phrase=request.getParameter("phrase");
IndexSearcher searcher;
searcher = new IndexSearcher(indexpath);
Term t=new Term("content",phrase);
Query q=new TermQuery(t);
Hits hs=searcher.search(q);
int num=hs.length();
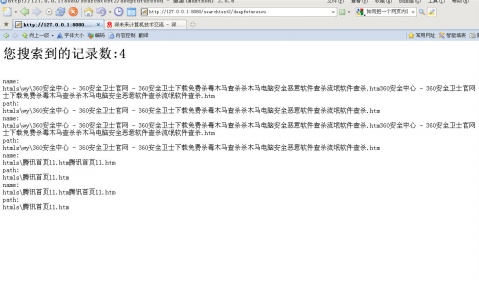
sb.append("<h1>您搜索到的记录数:"+num+"</h1>");
for (int i=0;i<num;i++){
Document doc=hs.doc(i);
if (doc==null){
continue;
}
Field field=doc.getField("name");
String name="<br>name:<br>"+field.stringValue();
field=doc.getField("path");
String path="<br>path:<br>"+field.stringValue();
sb.append(name);
sb.append(path);
}
searcher.close();
} catch (CorruptIndexException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
PrintWriter out;
try {
response.setContentType("text/html;charset=GBK");
out = response.getWriter();
out.print(sb.toString());
out.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void doGet(HttpServletRequest request,HttpServletResponse response){
doPost(request,response);
}
}
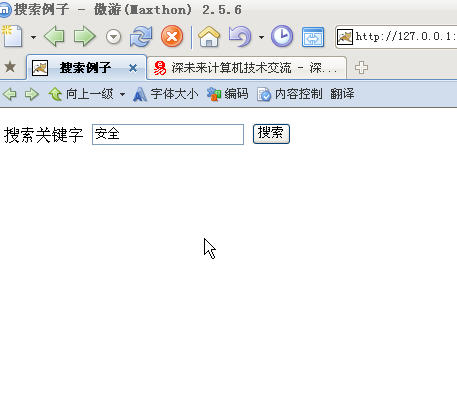
搜索网页
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>搜索例子</title>
</head>
<body>
<form id="form1" name="form1" method="post" action="deepfuturesou">
搜索关键字
<input name="phrase" type="text" id="phrase" />
<input type="submit" name="Submit" value="搜索" />
</form>
</body>
</html>
效果如下


















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









