






代码:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def saveImages(imglist):
number = 1
for imageURL in imglist:
fileName = "pic" + "/" + str(number) + "." + "jpg"
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen("http:"+imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'data-original="(.+?\.jpg)" alt'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
print imglist
return imglist
if __name__ == '__main__':
html = getHtml("http://category.vip.com/search-1-0-1.html?q=3|29736|10000389|&rp=30071|29737#J_catSite")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'图片'
imglist = getAllImg(html) #获取图片的地址列表
saveImages(imglist) # 保存图片
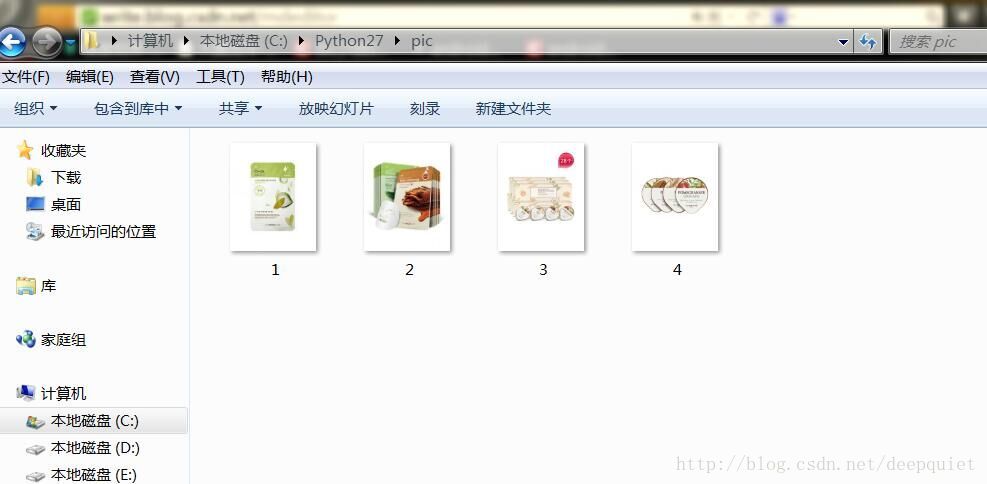
结果:















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









