







 本文深入探讨模糊C均值聚类(FCM)算法,解析其思想、推导过程及实现细节,通过实例展示如何优化聚类效果。
本文深入探讨模糊C均值聚类(FCM)算法,解析其思想、推导过程及实现细节,通过实例展示如何优化聚类效果。
文章目录
模糊C聚类(Fuzzy C-means Clustering, FCM)
1. 思想
- 簇内距离尽量小(*)
- 簇间距离尽量大
2. 说明
-
某种程度上类似于 LDA 的思想,但他们间有明显差距,LDA是属于监督学习下的降维操作,而该聚类基于非监督;
-
过程跟k-means聚类类似,区别在于FCM计算了(中心)点到所有数据点的距离,增加了隶属于某一簇的概率值(隶属值),还有属于某一簇的重视程度 m ( > 1 \gt 1 >1)
3. 推导
3.1 初始条件
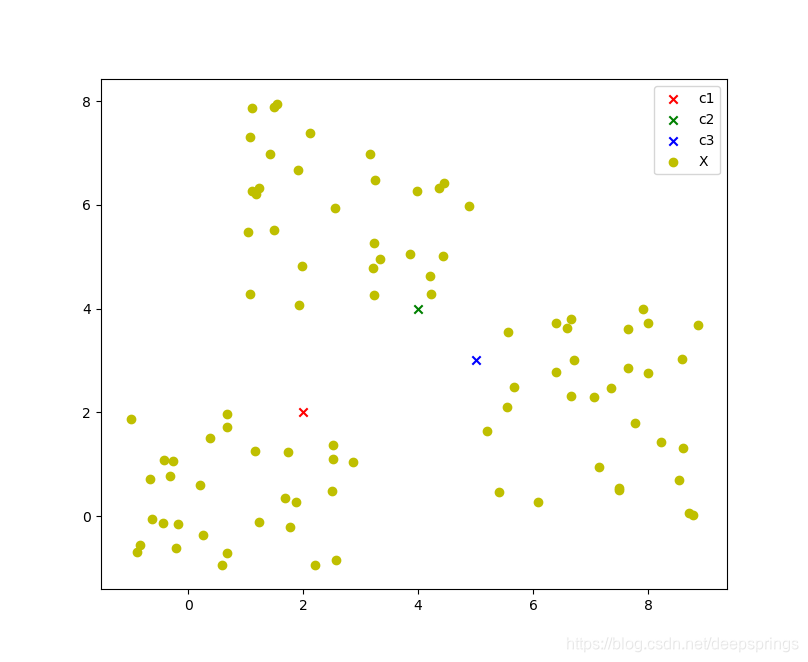
假设有N个原始数据点 X = ( x 1 , x 2 , ⋯ , x N ) X = (x_1, x_2, \cdots, x_N) X=(x1,x2,⋯,xN) ,设定有 L 个簇,初始簇心手动设定为 C = ( c 1 , c 2 , ⋯ , c l ) C=(c_1, c_2, \cdots, c_l) C=(c1,c2,⋯,cl) .
示意图如下(L=3时)
3.2 目标函数
计算每个数据点到簇心的距离(以到第一个簇心 c 1 c_1 c1为例)
d 1 = ∣ ∣ x 1 − c 1 ∣ ∣ 2 + ∣ ∣ x 2 − c 1 ∣ ∣ 2 + ⋯ + ∣ ∣ x N − c 1 ∣ ∣ 2 d_1 = ||x_1-c_1||^2+||x_2-c_1||^2+\cdots+||x_N-c_1||^2 d1=∣∣x1−c1∣∣2+∣∣x2−c1∣∣2+⋯+∣∣xN−c1∣∣2
为了表征一点到不同簇心的隶属程度,设定这些点到某一簇心的概率(隶属值,Membership values)为 u k i u_{ki} uki,该值表示第 i 点到第 k 个簇心的隶属值。点与簇心距离越大,该值越小。对于同一点来说,有
u 1 i + u 2 i + ⋯ + u L i = 1 u_{1i} + u_{2i} + \cdots + u_{Li} = 1 u1i+u2i+⋯+uLi=1
即,同一点到所有簇心隶属值和为 1
同时为了表示该点实实在在属于某一类,如图中右侧数据的某点属于 蓝色x 的重要程度更高,引入另一个参数:模糊系数(Fuzzifier) m
关于引入了隶属值 u k i u_{ki} uki 后为什么还要引入模糊系数m?
那么加权后,每个数据点到簇心 c 1 c_1 c1 的距离和为
d 1 ′ = u 11 m ∣ ∣ x 1 − c 1 ∣ ∣ 2 + u 12 m ∣ ∣ x 2 − c 1 ∣ ∣ 2 + ⋯ + u 1 N m ∣ ∣ x N − c 1 ∣ ∣ 2 = ∑ i = 1 N u 1 i m ∣ ∣ x i − c 1 ∣ ∣ 2 \begin{aligned} d'_1 &= u_{11}^m||x_1-c_1||^2 + u_{12}^m||x_2-c_1||^2 + \cdots + u_{1N}^m||x_N-c_1||^2 \\ &= \sum\limits_{i=1}^N u_{1i}^m||x_i-c_1||^2 \end{aligned} d1′=u11m∣∣x1−c1∣∣2+u12m∣∣x2−c1∣∣2+⋯+u1Nm∣∣xN−c1∣∣2=i=1∑Nu1im∣∣xi−c1∣∣2
对于所有点到所有簇心距离和为
D = ∑ k = 1 L ∑ i = 1 N u k i m ∣ ∣ x i − c k ∣ ∣ 2 D = \sum\limits_{k=1}^L \sum\limits_{i=1}^N u_{ki}^m||x_i-c_k||^2 D=k=1∑Li=1∑Nukim∣∣xi−ck∣∣2
该方程就是目标函数,优化方法是最小化该函数
M i n J ( u k i , c k ) = ∑ k = 1 L ∑ i = 1 N u k i m ∣ ∣ x i − c k ∣ ∣ 2 s . t ∑ k = 1 L u k i = 1 , i = 1 , 2 , ⋯ , N (1*) \begin{aligned}Min\ \ \ J(u_{ki}, c_k) &= \sum\limits_{k=1}^L \sum\limits_{i=1}^N u_{ki}^m||x_i-c_k||^2 \\s.t\ \ \sum\limits_{k=1}^L u_{ki} &= 1,\ \ i = 1,2,\cdots,N\end{aligned}\tag{1*} Min J(uki,ck)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









