







文章目录
路由多样分布感知专家进行长尾识别
0. Abstract
自然数据通常是长尾分布在语义类上。现有的识别方法通过将更多的重点放在尾部数据上来解决这种不平衡的分类,通过在不同的数据组上进行类重新平衡/重新加权或组合,从而导致尾部准确度增加但头部准确度降低。
我们对训练数据采取动态视图,并在训练数据波动时提供原则性的模型Bias和Variance分析:现有的长尾分类器总是增加模型的Variance和头-尾模型的Bias差距仍然很大,由于更多和更大的混乱与硬否定的尾巴。
我们提出了一个新的长尾分类称为路由多样性专家 RIDE。该算法采用多专家模型降低模型Variance,采用分布感知的多样性损失降低模型Bias,采用动态专家路由模块降低计算量。RIDE在CIFAR 100-LT、ImageNet-LT和iNaturalist 2018基准测试中的表现优于最先进的5%至7%。它也是一个通用框架,适用于各种骨干网络,如ResNet,ResNeXt和Swin Transformer,长尾算法和训练机制,以获得一致的性能增益。我们的代码可从以下网址获得:https://github.com/frank-xwang/RIDE-LongTailRecognition。
提出一种新的长尾分类器,称为路由多样性专家(RIDE)。通过动态专家路由模块降低计算成本,并减少了多专家的模型Variance以及基于分布感知的多样性损失的模型Bias。
1. Introduction
真实世界的数据通常是长尾分布在语义类上的:一些类包含许多实例,而大多数类只包含几个实例。长尾识别具有挑战性,因为它不仅需要处理尾类上的大量小数据学习问题,而且需要处理所有类上的极端不平衡分类。
有两种方法可以防止分类器训练目标中的许多头部实例压倒少数尾部实例:1)类别重新平衡/重新加权,其给予尾部实例更大的重要性(Cao等人,2019; Kang等人,2020; Liu等人,2019),2)在不同的数据分布上集成,将长尾数据重新组织成组,训练每组模型,然后在多专家框架中组合各个模型(Zhou et al.2020; Xiang等人,2020年)。
我们将三种最先进的(SOTA)长尾分类器与标准交叉熵(CE)分类器进行比较:采用两阶段优化,首先是表示学习,然后是分类学习的cRT和τ-范数(Kang等人,2020),以及训练端到端的边际损失的LDAM(Cao等人,2019年)。在分类准确性方面,固定训练集上的模型选择常见的度量,图1a表明,所有这些现有的长尾方法提高了overall,medium-shot和few-shot的精度CE,但降低了many-shot精度。
这些直观的解决方案和他们的实验结果似乎表明,长尾识别中存在一个头尾性能权衡。我们需要一个原则性的性能分析方法,可以揭示这样的限制,如果它存在,并提供如何克服它的指导。
我们的洞察力来自于训练集的动态视图:它仅仅是一些底层数据分布的样本集。我们不是评估长尾分类器在固定训练集上的表现,而是评估它在训练集根据数据分布波动时的表现。
(a) 比较基线和RIDE方法的平均准确度,每个类的Bias和Variance。比分布未知交叉熵(CE)参考更好(更差)的度量以绿色(红色)标记。

(b) 其他类(最难的负样本)每个实例的的最大softmax得分的直方图。
图1 RIDE通过减少模型Bias和Variance优于SOTA。a)在20个独立训练的模型上评估这些度量,每个模型在CIFAR 100的随机采样集上进行评估,对于类别0具有100和300个样本的不平衡比率。与标准CE分类器相比,现有的SOTA方法几乎总是增加Variance,并且一些以增加头部Bias为代价来减少尾部Bias。B)在CIFAR 100-LT Liu等人上评估度量。(2019年)。LDAM更容易将尾部(而不是头部)类与最难的负类混淆,平均得分为0.59。使用LDAM的RIDE可以大大减少与最近的负类的混淆,特别是对于来自少数类别的样本。
将训练数据
D
D
D 视为随机变量。模型
h
h
h 在实例
x
x
x 上的预测误差随
D
D
D 的实现而变化,输出为
Y
Y
Y 。关于变量
D
D
D 的期望Variance具有众所周知的bias-Variance分解:

对于上述回归
h
(
x
)
→
Y
h(x)→Y
h(x)→Y的L2损失,模型bias测量预测相对于真值的准确性;variance测量预测的稳定性;irreducible error测量预测的精度,并且与模型
h
h
h 无关。
经验上,对于
n
n
n 个随机样本数据集
D
(
1
)
,
.
.
.
,
D
(
n
)
D^{(1)},...,D^{(n)}
D(1),...,D(n),在
D
(
k
)
D^{(k)}
D(k)上训练的第
k
k
k 个模型对实例
x
x
x 预测为
y
(
k
)
y^{(k)}
y(k) ,并且它们具有预测的平均值
y
m
y_m
ym。对于 L2 regression loss,模型bias简单地是
y
m
y_m
ym 和ground-truth
t
=
E
[
Y
]
t=E[Y]
t=E[Y] 之间的 L2 loss,而模型Variance是
y
(
k
)
y^{(k)}
y(k) 相对于其均值
y
m
y_m
ym 的Variance:

如上图所示,这些概念可以完全用 L2 loss
L
\mathcal L
L 来表示。因此,我们可以通过用
L
0
−
1
\mathcal L_{0-1}
L0−1替换
L
\mathcal L
L 来将它们扩展到分类(Domingos,2000)

平均预测
y
m
y_m
ym 最小化为
∑
k
=
1
n
L
0
−
1
(
y
(
k
)
;
y
m
)
\sum_{k=1}^n\mathcal L_{0-1}(y^{(k)}; y_m)
∑k=1nL0−1(y(k);ym)并成为最常见或最主要的预测。Bias和Variance项分别为:
L
0
−
1
(
y
m
;
t
)
\mathcal L_{0-1}(y_m; t)
L0−1(ym;t)和
1
n
∑
k
=
1
n
L
0
−
1
(
y
(
k
)
;
y
m
)
\frac1n\sum_{k=1}^n\mathcal L_{0-1}(y^{(k)}; y_m)
n1∑k=1nL0−1(y(k);ym);
我们将这种bias和Variance分析应用于 CE 和长尾分类器。我们根据长尾分布多次采样CIFAR100(Krizhevesky,2009)。对于每种方法,我们对每个长尾采样数据集都训练出一个模型,然后在CIFAR100-LT Liu等人的平衡测试集上估计多个模型的每个类的bias和Variance。(2019)。图1a表示:
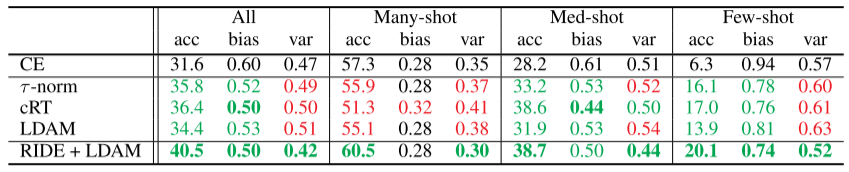
- 关于模型Bias:头部bias显著小于尾部bias,CE分别为0.3 VS 0.9。所有现有的长尾方法都主要通过减少尾bias来减少总体bias。然而,头尾bias差距仍然很大,为0.3 VS 0.8.
- 关于模型Variance:现有的所有长尾方法都增加了所以类的模型Variance,只有cRT的 mediun-shot的Variance略有减少。
也就是说,现有的长尾方法以增加所有类别的模型Variance为代价,减少了尾部的模型Bias,而头尾模型的Bias差距仍然很大。
我们进行了进一步的统计分析来了解头尾模型的Bias差距。 我们测试了
c
:
c
≠
t
{c: c\neq t}
c:c=t的其他类中最大的softmax分数,其中
t
t
t 是一个实例的ground-truth类。最难负类的softmax分数越小,混淆越少,模型Bias越低。图1b表示从头类到尾类的混乱程度越来越大。
在模型的Bias/Variance和混淆模式分析的指导下,我们提出了一种新的长尾分类器,具有四个显著特征: 1)它减少了具有多个专家的所有类的模型Variance。2)它通过一个额外的分布感知多样性损失减少了的尾部的模型Bias。3)它降低了多个专家的计算复杂性,通过一个动态专家路由模块,只有在需要时,才会部署另一个训练有素的独特专家进行第二(或第三,…)意见。4)路由模块和一个降低复杂性的共享的专家架构有效地降低了我们的多专家模型的计算成本,甚至可以比通常采用的具有相同backbone的基线更低的水平。
我们所谓的RoutIng多样化专家(RIDE)不仅减少了所有类的模型Variance,而且显著减少了尾部类的模型Bias,提高了所有分割类的平均精度,而现有的长尾方法都无法实现。
在CIFAR100-LT、ImageNet-LT(Liu等,2019)和iNaturalist (Van Horn等,2018)上,RIDE比SOTA方法准确率高5%~7%。RIDE也是一个通用的框架,可以应用于不同的backbone网络,以改进现有的长尾算法,如焦点损失(Lin等人,2017)、LDAM(Cao等人,2019)、τ -norm (Kang等)。
2. Related Works
少样本学习:从小训练数据中概括,元学习和数据增强/生成是研究最多的两种方法。匹配网络和原型网络学习鉴别特征,这些特征可以通过没有大训练数据的元学习器转移到新的类。利用生成模型中的样本来增加训练数据。然而,少样本学习依赖于平衡的训练数据,而长尾识别必须处理高度不平衡的训练数据,例如从头部的数百个样本到尾部的几个样本。
重新平衡/重新加权:实现样本平衡的一个直接方法是根据类大小进行过采样/欠采样训练实例。另一种选择是数据增强,即生成额外的样本来补充尾类,有时直接在特征空间中增强。重加权可修改损失函数,并对尾部类施加更大的权重或随机忽略头部类的梯度。然而,样本级和损失级的平衡都集中在尾类上,导致对小尾类的波动更加敏感,从而大大增加了模型的方差图1a。
知识转移:OLTR和过度记忆使用记忆库存储并将中高级特征从头部转移到尾部类,增强了尾部的特征泛化。然而,这一工作方向通常不能有效控制知识转移过程,经常导致头部性能损失。
集成和分组:对抗不平衡的一种方法是将训练实例根据其类规模分成不同的组。在单个组上训练的模型通过一个多专家框架集成在一起。BBN(Zhou)自适应地融合了两个分支,每个分支分别聚焦于头部和尾部。LFME(Xiang)将多个教师模型提炼为一个统一的模型,每个教师都专注于一个相对平衡的群体,如 many-shot 类, medium-shot 类 , few-shot 类。BBN和LFME仍然失去了头部性能和整体通用性,因为没有专家能够平衡访问整个数据集。
RIDE:一种非传统的集成方法。1)专家们贡献backbone前面的层,减少了后面的通道,从而降低了过拟合的可能性;2)专家联合起来进行优化;3)通过动态专家分配模块根据需要为每个实例部署专家;4)以较小的模型复杂度和计算成本达到较高的精度。
3. RIDE:ROUTING DIVERSE DISTRIBUTION-AWARE EXPERTS
ogits
我们提出了一种共享的早期层
f
θ
f_θ
fθ 和
n
n
n 个独立的通道后期
Ψ
=
{
ψ
θ
1
,
.
.
.
,
ψ
θ
n
}
\Psi=\lbrace{\psi_{\theta_1},...,\psi_{\theta_n}}\rbrace
Ψ={ψθ1,...,ψθn}减少的新型多专家模型图2.它们在阶段1联合优化,在阶段2通过学习的专家分配模块动态部署。在推理阶段,将一共m个专家在logits后平均,以进行最终的集成softmax分类:

平均logits的Softmax等价于每个分类概率的乘积,如果个体专家做出独立的决策,它近似于它们的联合概率。
共享的前期骨干和减少的后期通道的专家。考虑 n n n 个具有相同卷积神经网络(CNN)体系结构的独立专家。由于CNN的早期层倾向于编码通用的低级特征,我们采用了迁移学习中的常见做法,并让所有的 n n n 个专家共享相同的主干 f θ f_θ fθ。.每个专家都保留了各自的后续层 ψ θ i , i = 1 , . . . , n \psi_{\theta_i}, i = 1,...,n ψθi,i=1,...,n. 为了减少对尾类训练数据的过拟合,我们将减少 ψ θ i \psi_{\theta_i} ψθi 中滤波通道的数量到1/4。所有的 n n n 位专家都在长尾数据上进行了分布感知多样性损失 L D − D i v e r s i f y \mathcal L_{D-Diversify} LD−Diversify和分类损失 L C l a s s i f y \mathcal L_{Classify} LClassify训练,如CE和LDAM。
个体专家的分类损失。组合多个专家的一种方法是将分类损失应用于个体专家的聚合logits。虽然这个想法适用于几个最近提出的多专家模型(Zhou),但它并不适用于我们的共享专家:它的性能与同等大小的单专家模型相当。
L
\mathcal L
L表示实例
x
x
x 及其标签
y
y
y 的分类损失。我们称这种聚合损失为
c
o
l
l
a
b
o
r
a
t
i
o
n
collaboration
collaboration
因为它产生相关的专家而不是互补的专家。为了降低相关性,我们要求每个专家都要自己做好工作。这种聚合损失本质上是一种个体损失,在我们的大多数实验中,它贡献了很大一部分的性能增益:

分布感知的多样性损失。个体分类损失和随机初始化产生了具有共享主干的多元化专家。对于长尾数据,我们添加了一个正则化项,以促进来自多个专家的互补决策。也就是说,在所有类 c c c实例 x x x 类别 y y y 上,我们最大化了不同专家分类概率之间的KL散度。
我们改变温度 T T T(Hadsell)应用于类 k k k 的 logit ψ θ i ( f θ ( x ) ) k \psi_{\theta_i}(f_{\theta}(x))_k ψθi(fθ(x))k :对于有 n k n_k nk 实例类 k k k , n k n_k nk 越小,温度 T k T_k Tk 越低,分类概率 p p p 对特征 ψ ψ ψ 的变化越敏感。
具体来说,T的变化与类的大小呈线性相关,确保了一个平衡集的 β k = 1 , T k = α β_k= 1, T_k=α βk=1,Tk=α。这种简单的改变使我们能够找到头部足够复杂和尾部足够稳健的分类器:一方面,我们需要强大的分类器来处理头部类的大样本变化;另一方面,这种分类器容易在尾部类中过拟合小的训练数据。在训练几个epoch的CNN网络和特征稳定后才调整温度,类似于延迟重加权的训练方案(Cao)。

联合专家优化。对于共享一个主干
θ
\theta
θ的
n
n
n 个专家
θ
1
,
.
.
.
,
θ
n
\theta_1, ..., \theta_n
θ1,...,θn ,我们优化了它们的个体分类损失(
L
C
l
a
s
s
i
f
y
=
L
\mathcal L_{Classify}=\mathcal L
LClassify=L,指任何分类损失,比如CE、LDAM和Focal loss)和它们的互补分布感知多样性损失 ,由超参数
λ
λ
λ 加权。由于这些损失项是完全对称的,在第一阶段中学到的
n
n
n 个专家都很好并且彼此不同。

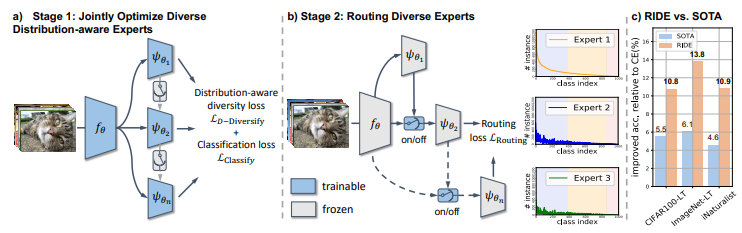
图2: RIDE分两个阶段学习专家及其路由。a)我们首先联合优化具有个体分类损失和共同的分布感知多样性损失的多个专家。b)然后,我们训练一个路由器,它可以根据需要动态地将模糊的样本分配给其他专家。每个专家所看到的实例分布表明,头部实例需要更少的专家,而后期专家之间的类之间的不平衡也会减少。在测试时,我们收集指定专家的logits输出来做出最终决定。c) RIDE的性能优于SOTA方法(LFME(Xiang):CIFAR100-LT,LWS(Kang):ImageNet-LT和BBN(Zhou):iNaturalist)的所有基准。
路由多样化的专家。为了减少多个专家附带的测试时计算成本,我们在第二阶段训练了一个路由器,以便根据需要依次部署这些(任意排序的)专家。假设已经为实例 x x x 部署了第 k k k 个专家。路由器接收从第 1 1 1 个专家到第 k k k 个专家的图像特征和平均logits,并关于是否部署 k + 1 k+1 k+1 专家做出一个二进制决策 y o n y_{on} yon。如果第 k k k 个专家错误地分类了 x x x ,但其余的 n − k n-k n−k 个专家之一正确地分类了 x x x ,理想情况下路由器应该打开,即输出 y o n = 1 y_{on}=1 yon=1,否则为 y o n = 0 y_{on}=0 yon=0 。我们构造了一个简单的二值分类器与两个全连接的层来学习每个路由器。 n n n 个专家的 n − 1 n-1 n−1 个路由器都有一个共享组件来减少特性维,还有一个单独的组件来做决策。
具体来说,我们将图像特征
f
θ
(
x
)
f_\theta(x)
fθ(x)归一化(用于训练稳定性),通过一个所有路由器共享的全连接层
W
1
W1
W1 减少特征维度(公式16),然后进行 ReLU 和 flattening,接着将第
1
1
1 到
k
k
k 个专家
1
k
∑
i
=
1
k
ψ
θ
i
(
f
θ
(
x
)
)
\frac1k\sum_{i=1}^k\psi_{\theta_i}(f_{\theta}(x))
k1∑i=1kψθi(fθ(x))中排名前
s
s
s 的平均logits连接。用一个独立于路由器的
W
2
(
k
)
W_2^{(k)}
W2(k) 将它投影到一个标量上,最后应用 Sigmoid 函数
S
(
x
)
=
1
1
+
e
−
x
S(x)=\frac1{1+e^{-x}}
S(x)=1+e−x1得到属于[0,1]的连续激活值:

这个路由器的大小和计算量可以忽略不计,其中
s
s
s 的范围从CIFAR100的 30 到iNaturalist(8142类)的 50。它采用二元 CE 损失的一个加权变体进行优化:
 其中
ω
o
n
ω_{on}
ωon控制路由器上开关的难易。我们发现在所有实验中,
ω
o
n
=
100
ω_{on}=100
ωon=100是分类精度和计算成本之间的一个很好的权衡。在测试时,我们只需令激活阈值为
0.5
0.5
0.5 :如果
r
(
x
)
<
0.5
r(x)<0.5
r(x)<0.5,分类器使用当前的collective logits做出最终决定,否则将继续给下一个专家。
其中
ω
o
n
ω_{on}
ωon控制路由器上开关的难易。我们发现在所有实验中,
ω
o
n
=
100
ω_{on}=100
ωon=100是分类精度和计算成本之间的一个很好的权衡。在测试时,我们只需令激活阈值为
0.5
0.5
0.5 :如果
r
(
x
)
<
0.5
r(x)<0.5
r(x)<0.5,分类器使用当前的collective logits做出最终决定,否则将继续给下一个专家。
可选的自蒸馏。现有的长尾分类器,如BBN(Zhou)和LFME(Xiang)有固定数量的专家,我们的方法可以有任意数量的专家来平衡分类准确度和计算成本。我们可以将一个拥有多专家(我们设置为6)的模型的自蒸馏应用到一个拥有少专家的相同模型中,以获得进一步的性能提高(大多数实验为0.4%~0.8%)。我们默认选择知识蒸馏(Hinton)。附录A.2节研究了实现细节和与各种蒸馏算法,如CRD(Tian)。
4. Experiments
我们在主要的长尾识别基准测试和各种主干网络上进行了实验。
- CIFAR100-LT(Cao): CIFAR100是按类别的指数递减采样的。我们选择不平衡因子为100和ResNet-32(He)骨干。
- ImageNet-LT(Liu):在ImageNetLT上实验了多个主干网络,包括ResNet10、ResNet-50和ResNeXt-50(Xie)。所有骨干网络在8 RTX 2080Ti GPU上使用SGD训练100 epoch,batch size为256,初始学习率为0.1,分别在60 epoch和80 epoch衰减0.1。附录中查看细节和结果。
- iNaturalist 2018(Van):这是一个自然不平衡的细粒度数据集,有8142个类别。我们使用ResNet-50作为骨干,并应用与ImageNet-LT相同的训练方法,除了batch size为512(Kangetal)。
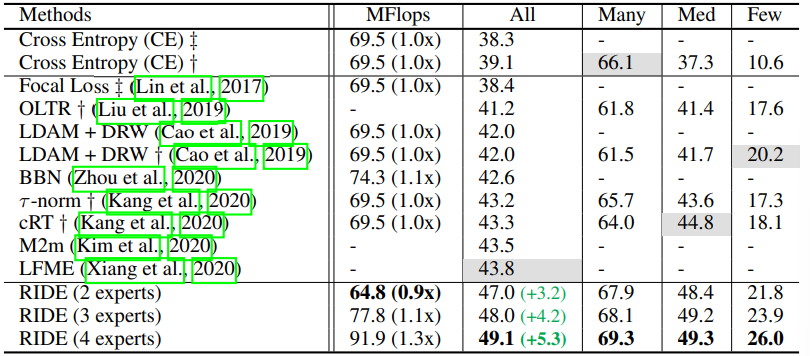
CIFAR100-LT上的结果。表1显示,RIDE在CIFAR100-LT上的性能大大优于SOTA。平均计算成本甚至比两位专家的基线模型低10%。RIDE分别超过多专家方法LFME(Xiang)和BBN(Zhoo)5.3%和6.5%。
表1:RIDE在CIFAR100-LT上实现了最先进的结果,而不像以前所有方法一样牺牲many-shot 类的性能。与BBN(Zhou)和LFME(Xiang)相比,后者也包含多个专家(或分支架构),RIDE(2名专家)使用更少的GFlops但性能远超他们。下面报告了相对于基线模型的相对计算成本(在测试集上的平均)和相对于SOTA的绝对改进(绿色框)。+表示我们复制发布代码的结果。++表示复制(Cao)的结果,不平衡比为100。
RIDE 是一个通用框架。图3表明,RIDE始终受益于更好的损失函数和训练过程。无论模型是端到端训练(焦点损失、CE、LDAM)还是两阶段(cRT、τ -norm、余弦),RIDE都提供了一致的准确率增益。特别是使用简单余弦分类器的RIDE,我们将分类器权值归一化,并使用长尾重采样策略(类似于cRT)进行再训练,实现了与当前SOTA方法相同的性能。图3还表明,两阶段方法一般优于单阶段方法。然而,由于它们需要一个额外的训练阶段,为了简单起见,在我们剩下的实验中,我们使用单阶段LDAM作为 RIDE 默认的
L
C
l
a
s
s
i
f
y
\mathcal L_Classify
LClassify。
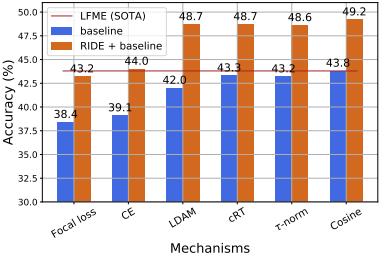
图3:RIDE是一个通用的框架,可以扩展到各种长尾识别方法,并获得一致的top-1准确率提高。在CIFAR100-LT上进行了实验,并应用于各种训练机制。在CIFAR100-LT上通过使用RIDE,交叉熵损失(没有任何重新平衡策略)甚至可以优于以前的SOTA方法。虽然使用蒸馏可以获得更高的准确率,但我们没有在这里应用它。
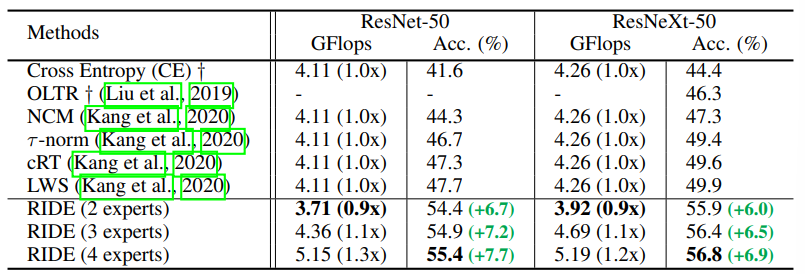
ImageNet-LT的结果。表2显示,RIDE比SOTA、LWS和cRT好,比ResNet-50好7.7%以上。基于组卷积(Xie)的ResNeXt-50,它将所有过滤器划分为几个组,并聚合来自多个组的信息。ResNeXt-50在多个任务上的表现通常比ResNet-50更好。它为ImageNet-LT提供了6.9%的收益。
表2: RIDE在ImageNet-LT(Liu)上取得了最先进的结果,并在各种骨干上获得了一致的性能改进。以ResNet-50和ResNeXt50为骨干网络,我们在ImageNet-LT上与最先进的方法比较top-1准确率和计算成本。用 + 标记的结果来自(Kang)。每个split类的详细结果列在附录材料中。
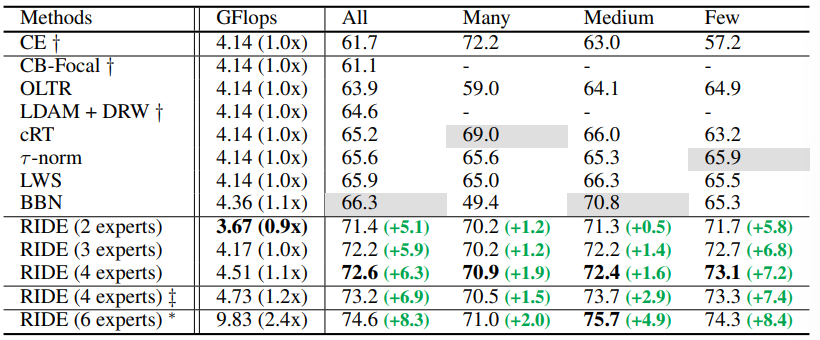
iNaturalist 2018的结果。表3显示,RIDE的性能比当前的SOTA高出6.3%。令人惊讶的是,RIDE在 many-shots,medium-shots,few-shots中获得了非常相似的结果,这是长尾识别的理想选择。目前的SOTA方法BBN也使用了多位专家;然而,它显著的使多镜头的性能降低约23%。RIDE 在不降低many-shots准确率的情况下提高few-shots准确率方面性能是显著的。随着训练时间的延长,RIDE得到了更大的改进。
表3: RIDE在挑战iNaturalist 2018(van)数据集上优于以前的最先进方法,该数据集包含8142个类。还列出了每个split类的SOTA结果的相对改进(灰色),最大的提升来自 few-shot类。与之前的SOTA方法包含多个“专家”的BBN相比,RIDE在 many-shot类上的 top-1准确率提高了20%以上。用 + 标记的结果来自BBN(Zhou)和Decouple(Kang)。BBN的结果来自于已发布的检查点。++:训练200个epoch。*:训练300个epoch,没有专家分配模块。 方法 GFlops 所有许多中,少数
与 iNaturalist 和 ImageNet-LT 上的SOTA上的比较。如图4所示。我们的方法为所有 many-shots,medium-shots,few-shots提供了全面的处理,在所有方面实现了对当前最先进的技术的实质性改进。与cRT降低了many-shots类的性能相比,RIDE可以在不损害many-shots类的情况下,在few-shots类上获得显著更好的性能。通过与最先进的方法BBN(Zhou)的比较,也可以得到类似的观察结果。
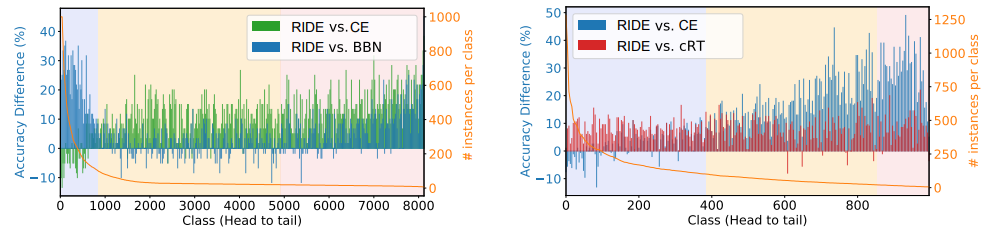
图4:与SOTA相比,RIDE在所有三个splits(many/med/few-shot)上都提高了top1准确率。RIDE(蓝色)与目前iNaturalist上最先进的方法BBN(Zhou)(左)和目前ImageNet-LT最先进的方法cRT(Kang)(右)的绝对精度差异如图所示。RIDE在不牺牲many-shot精度的情况下,提高了med和few-shot类的性能,并且在many-shot上的性能大大超过了BBN。
训练
RIDE各组件的贡献。RIDE是与分布感知多样性损失
L
D
−
D
i
v
e
r
s
i
f
y
\mathcal L_{D-Diversify}
LD−Diversify和分类损失
L
C
l
a
s
s
i
f
y
\mathcal L_{Classify}
LClassify联合训练,默认使用LDAM来表示
L
C
l
a
s
s
i
f
y
\mathcal L_{Classify}
LClassify。表4显示,从原来的ResNet-32到有2~4 位专家的RIDE架构变化贡献了2.7%和4.3%的增益。 采用Individual loss而不是collaboration classification loss可以获得1.5%的收益。增加diversify loss进一步提高了约0.9%。通过添加动态专家路由器,大大降低了计算成本。从6位专家的RIDE知识蒸馏中,再获得0.6%的收益。所有这些组件比基线LDAM增加7.1%。
表4:各组件对CIFAR100-LT有效性的消融研究。LDAM被用作我们的分类损失。前3个RIDE模型只有体系结构上的变化,而没有改变训练方法。没有LIndividual的性能表示直接将分类损失应用到最终的模型输出平均专家logits上。这在上面被称为collaboration loss。相比之下,如果有LIndividual我们将对每个专家应用Individual loss。collaboration loss和Individual loss的差异如上所述。通过添加路由器模块,可以显著降低RIDE的计算成本,而准确率的下降可以忽略不计。如果需要进一步的改进,知识蒸馏步骤是可选的。在附录中比较了各种知识蒸馏技术。

对专家数量的影响。图5表明,无论是相对收益还是绝对收益,专家更多时,很难收益更多。例如,相对收益为16%时medium-shots 和 few-shots分别为3.8%。在这个比较中没有应用蒸馏。
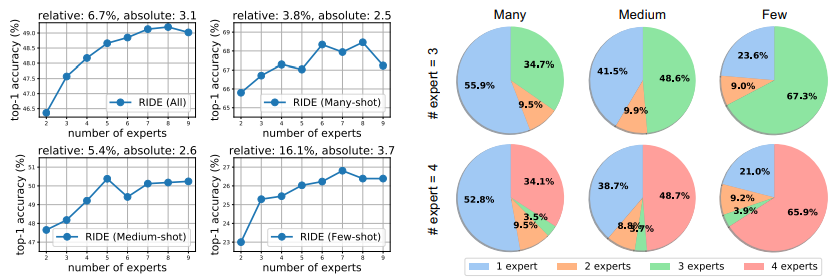
图5(左):专家vs每个split(all/many/med/few)在CIFAR100LT上的top-1准确率。与many-shot相比增加更多专家相对提高了3.8%,few-shot可以获得更多的好处,即相对提高了16.1%.
图6(右):CIFAR100-LT上分配给每个split的专家数量的比例。对于有3或4个专家的RIDE,超过一半的many-shot样本只需要一个专家。相反,超过76%的few-shot样本需要其他专家的意见。
分配给每个split的专家数量。图6表明,few-shot样本需要更多的专家,而many-shot的大多数样本只需要一个专家。也就是说,在尾部实例中的低可信度通常需要模型寻求第二个(或第三个,……)的意见。
在ImageNet-NT上使用vision transformer的结果。由于最初的 vision transformer ViT(2021)不能很好地用于中或小尺寸的数据集,我们使用能有效改进ViT的SwinTransformer(Liu)以研究我们的方法在VIT上的有效性。我们选择ImageNet-LT是因为CIFAR 100-LT太小了,即使是Swin-T也不能表现得很好。我们保持前两个阶段的完整,并从第三阶段开始使用多专家结构。与ResNe-50类似,我们在后两个阶段使用了原始的3/4维。由于我们发现swinin-S已经过拟合了数据集,所以我们不报告使用更大的swin-T的结果。为简单起见,我们不使用蒸馏法。我们遵循原始的训练方法,除了我们的模型使用更高的权重衰减,因为我们有更大的模型能力来减少过拟合。我们这个模型训练了300 epoch,然后在240epoch重新加权LDAM-DRW。
表5:在ImageNet-LT(Liu)上与Swin-Transformer(Liu)比较top-1个准确率。同时还提供了Many-shot (>100),Medum-shot (≤100 & >20), Few-shot (≤20)的性能。Swin-T: 小Swin-Transformer。Swin-S:大 Swin-Transformer
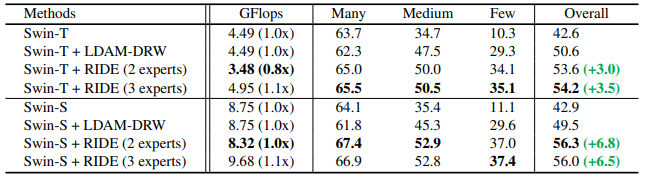
在表5中,我们发现没有任何修改的Swin-T在ImageNet-LT上的表现略优于ResNet-50。然而,这可能是由于在GFLops方面的模型大小的增加(4.49 vs 4.11 GFlops)。由于 VIT 具有相对较小的感应偏差,因此可以看到重新加权和边际正则化的巨大改进(LDAM-DRW),它为模型提供了数据集分布的知识。 即使在对训练数据集进行建模之后,添加我们的方法仍然可以得到大约3%~6%的改进。我们在CNN上观察到的结果仍然成立:虽然我们在few-shot上改进了一点,但我们的方法在三个 splits 上改进了模型。相比之下,在训练中重加权训练数据集可以通过提高medium和few-shot来提高整体准确率,但降低了many-shot的准确率。然而,在原始的ImageNet上通常适用的趋势并不总是在长尾设置中遵循。在Swin-S中,与没有修改的Swin-T相比,性能保持不变,尽管Swin-S大约是Swin-T的两倍大。我们的方法对数据集进行了更好的建模,改进了大量改进,特别是few-shot类,2位专家达到了6.8%的改进。我们的方法没有通过3位专家进行进一步的改进,我们认为这是由于ImageNet-LT数据集的大小,因为ImageNet-LT的大小只有原始ImageNet大小的一小部分。如果没有足够的数据,大型SwinTransformer很容易过拟合。在Liu的SwinTransformer论文在平衡ImageNet-1k上从Swin-S到Swin-B的有限收益也支持了这一点。(2021).
5. Summary
我们动态看待训练数据,并通过模型偏差和方差分析来研究长尾识别。现有的长尾分类器在增加模型方差的同时,并没有充分减少头尾模型的偏差差距。我们提出了一个新的多专家模型,称为RIDE,以减少模型的偏差和方差。它训练出不同的部分共享分布感知专家,并在必要时将一个实例路由给额外的专家,其计算成本与单个专家相当。RIDE的表现大大优于SOTA。它也是一个通用的框架,可以与各种骨干和训练方法一起进行,以获得一致的收益。
论文总结
RIDE在包括CIFAR-LT, ImageNet-LT, iNaturalist在内的benchmark上,相较于之前的水平获得了5.3%~7.7%的准确率提升。To our best knowledge,RIDE同时也是第一个在多个数据集上同时提升many-shot,medium-shot和few-shot class准确率的方法。我们的方法不但适用于ResNet/ResNext等CNN backbone,而且可以在transformer-based框架上获得普适性的提升。代码已开源:
长尾数据分布 (Long-tailed Data Distribution)
-
长尾数据分类的一般设定为:
训练数据:如上图所示,训练集中的少数类别(head class)含有训练集中的多数标注数据,而大量其余类别(tail class)仅有少数标注数据。
测试数据:所有类别含有相同数量的测试数据。为了进一步分析模型的分类能力,测试数据按照训练集中每一类含有训练数据的数量分为many:samples>100,medium:20<samples<100,few-shot :samples<20。 -
为什么需要研究长尾场景?
由于自然场景中,物体的出现频率一般遵循长尾分布,所以为了保证模型在实际应用场景下不单可以对head class有较高的准确率,同时对训练集中出现频率较低的tail class可以维持较高的准确度,研究如何提升模型在长尾数据上的表现是非常重要的。
这一问题在很多数据集上没有得到体现的原因是,包括cifar,imagenet在内的数据集均人为进行了数据筛选,从而使得训练集中,每一类别拥有几乎一致的数据量。但是,人为筛选后的训练集显然与实际应用场景是不相符的。 -
为了研究长尾数据问题,2018年前后相继有一些长尾数据集被提出,包括研究分类问题的CIFAR-LT, ImageNet-LT 以及 iNaturalist,研究检测及分割问题的LVIS等,从而导致这一让工业界较为困扰的问题开始受到学界的关注。
-
为什么主流方法基本都以降低many-shot classes的准确率为代价提升few-shot classes准确率?
目前的主流长尾数据分类的算法虽然在最终的overall准确率都可以提升(当然啦,不然怎么发出来论文捏),但是基本都是以牺牲many-shot class为代价提升medium-shot及few-shot classes。在实际应用中,尽管我们希望模型对tail-class的准确率进行提升,但是,模型更经常遇到的是head-class,因而,以牺牲head-class 的准确率为代价来提升tail-class其实是并不可取的!由于长尾数据集的测试集均为balanced,因而这一问题被很大程度上掩盖了。
RIDE
为了探究产生这种现象的原因,这篇文章首先将模型损失分解为bias和variance:

公式 1 中的不可约误差irreducible error和模型本身不相关,因而在这里不进行分析;bias主要衡量模型的mean preidctions相较于ground truth的距离;variance主要衡量模型的predictions的稳定程度。
具体怎么去进行定量计算呢?
1)我们首先随机从CIFAR100采样20次分别构建20个CIFAR100-LT数据集。
2)分别在这20个数据集上独立训练20个model。
3)根据公式 4 和公式 5 进行bias和vairance的计算。
最终选择了五种方法进行了分析,每种训练20个model:
1)Cross-entropy:baseline method
2)
τ
\tau
τ-norm:2-stage
3)cRT:2-stage, re-sampling
4)LDAM:1-stage,margin-loss based
5)本文提出的RIDE
最终结果如下表所示:
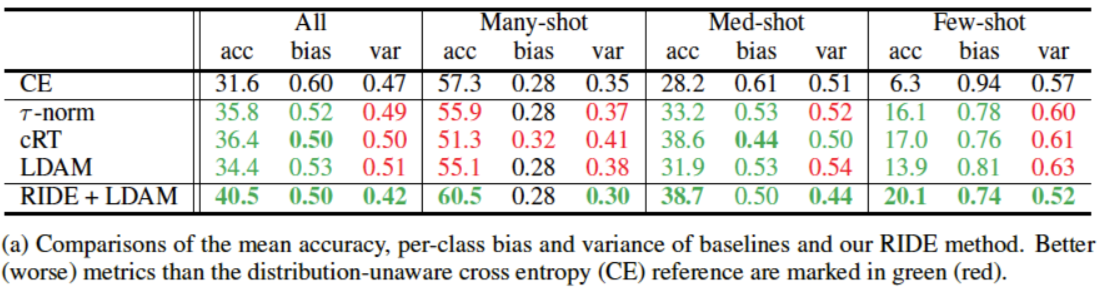
红色:相较于CE更差;绿色:相较于CE更优。
由于bias,variance为越低越好,accuracy为越高越好,我们统一用红色代表相较于CE表现更差,绿色表示相较于CE表现更优。我们可以得到如下结论:
- Bias:所有之前的长尾方法均可以减少few-shot class bias,但是many-shot class bias基本保持不变,并未改善。
- Variance:目前所有的长尾方法均提升了few-shot和many-shot class的variance,所以模型在所有的splits上均更不稳定。
- Accuracy:由于many-shot class的bias部分未被改善,variance部分大幅增加,因而many-shot由于拥有更差的bias-variance权衡,准确率降低。而few-shot尽管也增加了variance,但是bias term得到了降低,因而通过获得更优的bias-variance权衡,使得准确率得到了提升。
通过以上分析,如果希望避免降低many-shot的准确率,同时进一步提升few-shot的准确率,核心点就是降低variance?
无论是通过re-sampling/re-weighting来迫使模型在训练过程中对few-shot classduplicate tail-class sample或施加更大的penalty,还是通过marginal loss使得few-shot class与相邻class间的margin更大,都会导致模型过多关注数据量极小的few-shot class。而模型在小数据量的情况下极容易过拟合,进而导致variance增大。

如上表总结所示,RIDE获得了最优的情况,即variance在所有splits上均得到了降低。同时,对bias也有小幅度降低。因而,RIDE在所有的splits上均得到了准确率的提升。overall accuracy相较于LDAM可以提升近6%。
方法及模型
我们希望提出一个尽可能简单的方法,能够达到降低variance的目的。模型总共包括两个部分:

1. Multi-expert framework
(1)降低variance:通过含有多个experts的multi-expert framework来降低模型的variance。
(2)降低计算量:每一个expert的filter数量均相较于baseline有所降低,同时共享大部分参数,从而大大降低了模型总参数。
(3)多专家:此外,由于多个experts共享了大部分参数并且jointly训练,为了促使experts更为diversified,RIDE采用了independent loss来训练每一个expert,同时提出了diversity loss。diversity loss (公式10-12) 通过调节temperature (公式13-14)的大小来促使不同experts之间在few-shot上的prediction更为diverse。
第一阶段的loss如下,其中classify loss可以为任何loss function,比如focal loss,CE,LDAM等。其中
λ
\lambda
λ同于调节模型准确率和diversity之间的权衡:

2. Routing diversified experts
为了进一步减少多个experts带来的计算成本增加问题,我们在第二阶段训练了一个routing module,以根据当前模型对于测试数据的confidence score来选择是否使用更多的experts参与决策。此时,除routing module以外的所有模型组成部分都是不进一步fine-tune的。
如何设定ground truth?我们将当前预测错误,但是使用余下experts参与后预测正确的sample设定为y=1(swith on),其余的设定为0(swith off)。Routing loss可以看作weighted binary cross-entropy。这部分的优化目标是尽可能少使用experts来达到一致的准确率,我们通过
w
o
n
w_{on}
won 调节 swith on/off 的难易程度。

训练之后我们发现一个很有意思的现象,尽管我们的第二阶段的loss并非是distribution-aware,few-shot却在训练后有更大比例被assign更多的experts,而many-shot有超过一半的数据只需要一个expert参与预测。具体结果如下图所示。也就是说,routing module认为更多的many-shot class属于easy case,因而只需要一个专家进行决策即可。而绝大部分few-shot数据属于hard case,因而需要更多专家参与决策。

实验结果
- RIDE在所有的benchmark上相较于之前的state-of-the-art均获得了5%~7.7%的准确率提升;
2)RIDE同时也是第一个在多个数据集上同时提升many-shot,medium-shot和few-shot class准确率的方法; - RIDE可以和多个现有的方法结合获得稳定的准确率提升。
-
在CIFAR100-LT数据集,RIDE和多个主流方法结合获得了普遍的准确率提升。值得一提的是,RIDE使用cross-entropy训练已经可以超过CIFAR100-LT上的SOTA方法LFME。

-
CIFAR100-LT (100 类): 5.3%的准确率提升。RIDE w/ 2 experts的GFLOPs甚至低于baseline。RIDE 是唯一一个在many-shot上获得高于CE准确率的方法。

-
ImageNet-LT (1000 类): 7.7%的准确率提升。RIDE在多种backbone上均可获得提升。

-
iNaturalist-2018 (8142 类): 6.3%的准确率提升。相较于同样使用多个experts的方法BBN, RIDE在many-shot class上提升了近22%,同时总准确率提升了6.3%。















 3580
3580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









