







 在一次并发压测中,由于系统物理内存耗尽,Tomcat进程被Linux内核的OOM Killer杀死。分析发现,系统无交换分区空间,导致在内存不足时无法分配临时空间。解决方案包括启用Swap文件和调整Apache的最大连接数及内存限制。
在一次并发压测中,由于系统物理内存耗尽,Tomcat进程被Linux内核的OOM Killer杀死。分析发现,系统无交换分区空间,导致在内存不足时无法分配临时空间。解决方案包括启用Swap文件和调整Apache的最大连接数及内存限制。
背景描述
某项目结构图如下(前端交互式体验及对象存储为主,redis 及 rds 负载较小没有画出):
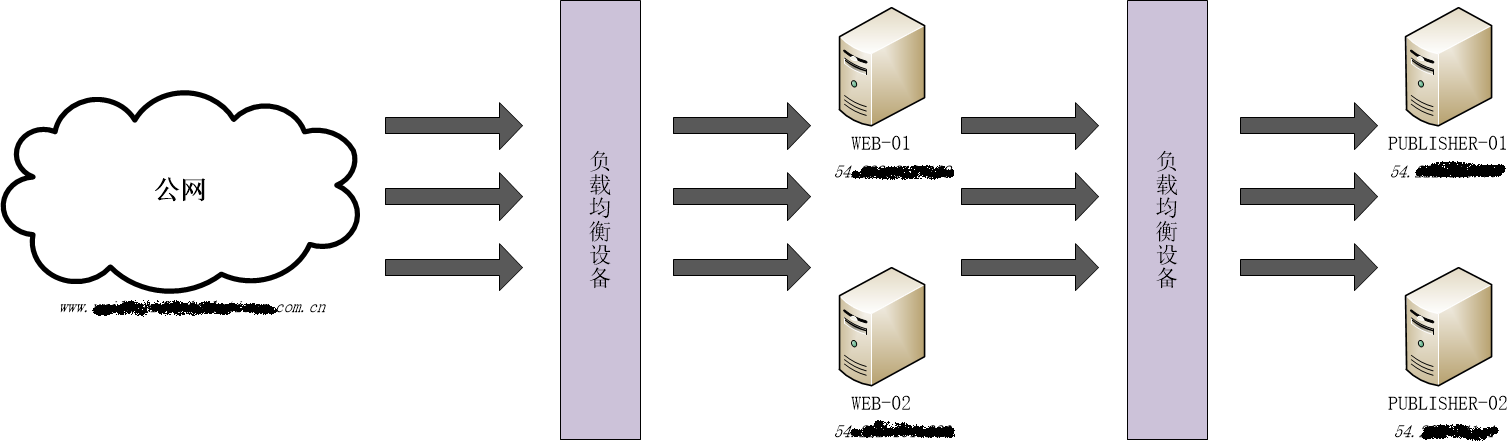
web1 和 web2 是两个 Apache,publisher1 和 publisher2 是两个 Tomcat 容器下的 app 应用服务器。
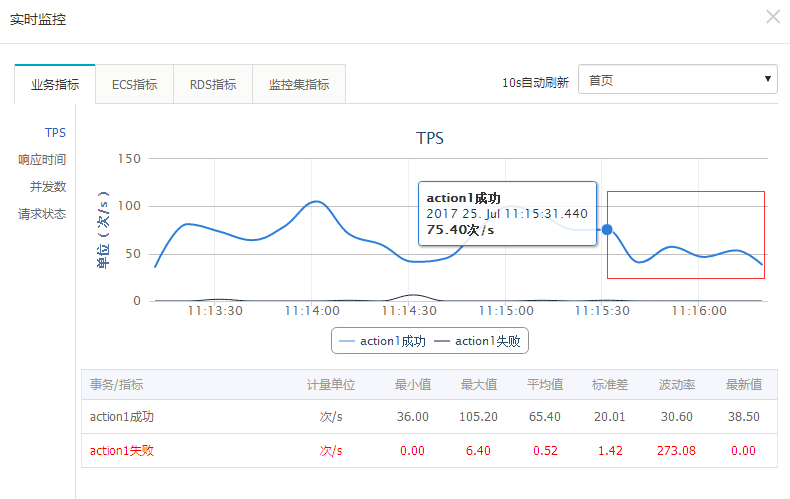
在对该项目进行压测时,并发数加到 750 左右,阿里云 PTS 压测工具监测到在某个时间点后 tps 呈下降趋势:
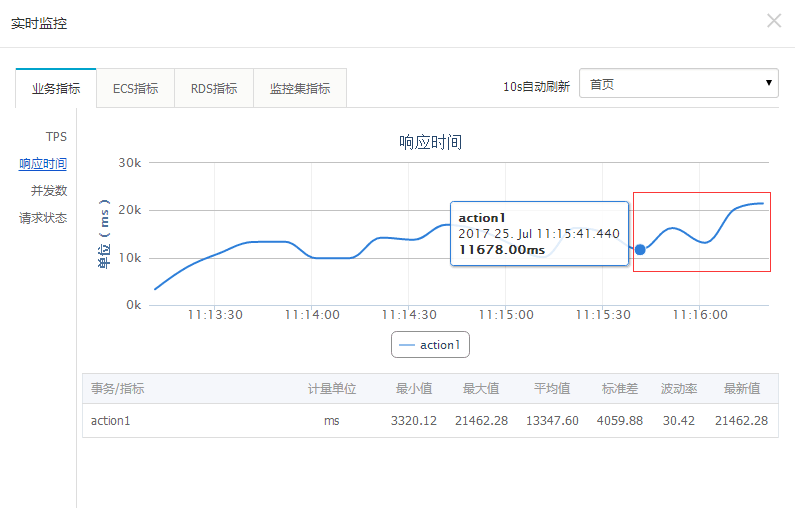
作为对应指标的响应时间(rt)在这个时间点呈上升趋势:
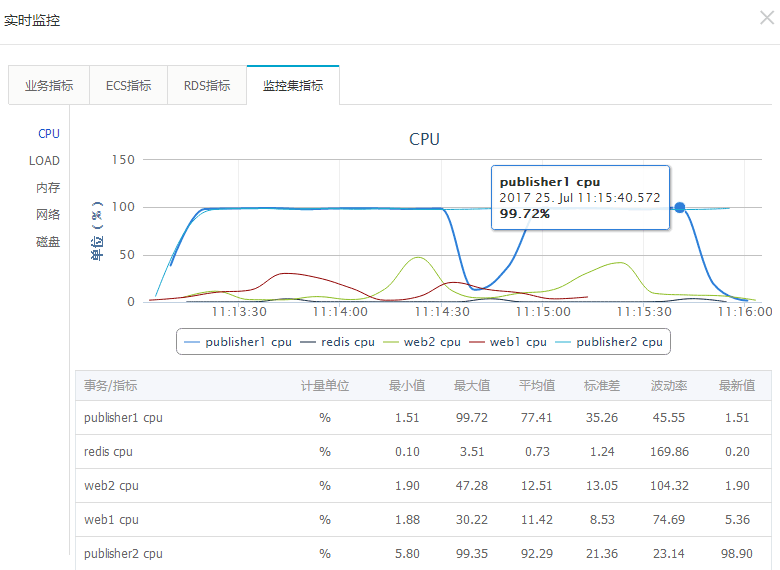
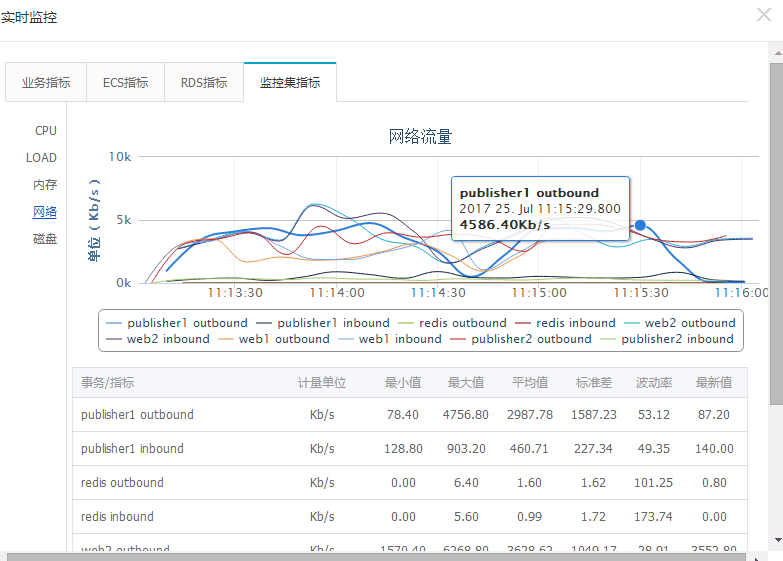
查看实时监控-监控集指标,发现 publisher1 节点的 CPU 利用率已降为 1.9,在高并发的时候这个值肯定是有问题,很可能这个节点已经宕掉:
查看网络流量发现该节点果然已经没有了网络流量:
ssh 登录 publisher1 ps 证实 Tomcat 确实已经 crash。但查 Tomcat 日志、应用日志,没有任何异常,find 也没找到类似于 hs_err_pidNNN.log 之类的 crash 日志。Tomcat 内存分配情况:
JAVA_OPTS="-Xmx3072m"
系统物理内存 8G,看上去绰绰有余。真的是这样吗?
原因分析
一般来讲,诸如内存溢出之类常见的 Tomcat 崩溃都会在容器日志或者 crash 日志中记录原因。但不排除这种情况:Linux 允许系统中的进程申请比现有系统可用内存还要多的内存,但当整个系统内存不足的时候,Kernel 会将耗用内存最多的那个进程给干掉,就是 Tomcat 了,但这并不能说明 Tomcat 发生了某些运行时的致命错误,所以我们没有看到任何容器、应用甚至 jvm 级别的异常,Tomcat 来不及做任何日志处理就 Over 了。查看 /var/log/messages,在 PTS 指示的时间点找到了以下日志:
Jul 25 03:15:39
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









