







OS和Linux笔记
操作系统
基本概念
- 用户态和内核态
- 用户态和内核态的区别
- 用户态和内核态是操作系统的两种运行级别,两者最大的区别就是特权级不同
- 用户态拥有最低的特权级,内核态拥有较高的特权级
- 运行在用户态的程序不能直接访问操作系统内核数据结构和程序
- 操作系统的数据都是存放于系统空间的,用户进程的数据是存放于用户空间的。 分开来存放,就让系统的数据和用户的数据互不干扰,保证系统的稳定性
- 分开存放,管理上很方便,而更重要的是,将用户的数据和系统的数据隔离开,就可以对两部分的数据的访问进行控制。这样就可以确保用户程序不能随便操作系统的数据,这样防止用户程序误操作或者是恶意破坏系统
- 用户态和内核态可以通过指针传递数据吗?
- 用户态不能访问内核态的指针
- 为了实现内存的保护,防止越界访问而造成受保护内存的被非法修改,甚至造成系统的崩溃,这种直接传递数据指针来传递数据的方式是被禁止的。
- 内核态可以访问用户态的指针(有前提)
- 必须保证用户态虚拟空间的指针(虚拟空间的地址),已经分配物理地址,否则指针传入内核态中将不会引发缺页异常而报错
- 内核中访问用户进程的地址的时候用copy_from_user,而不是用memcpy直接拷贝(或者说使用用户态指针)
- copy_from_user主要是这个函数提供了两个功能
- 对用户进程传过来的地址范围进行合法性检查
- 当用户传来的地址没有分配物理地址时,定义了缺页处理后的异常发生地址,保证程序顺利执行
- 对于用户进程访问虚拟地址,如果还未分配物理地址,就会触发内核缺页异常,接着内核会负责分配物理地址,并修改映射页表。这个过程对于用户进程是完全透明的。但是在内核空间发生缺页时,必须显式处理,否则会导致内核出现错误
- 直接使用memcpy时为什么没有出现异常
- 只有用户传来的地址空间没有分配对应的物理地址时才会进行修复,如果用户进程之前已经使用过这段空间,代表已经分配了物理地址,自然不会发生缺页异常
- copy_from_user主要是这个函数提供了两个功能
- 用户态不能访问内核态的指针
- 两种状态转换
- 系统调用
- 用户进程主动要求切换到内核态的一种方式,用户进程通过系统调用申请操作系统提供的服务程序完成工作
- 异常
- 当CPU在执行运行在用户态的程序时,发现了某些事件不可知的异常,这是会触发由当前运行进程切换到处理此异常的内核相关程序中,也就到了内核态,比如缺页异常。
- 外围设备中断
- 当外围设备完成用户请求的操作之后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条将要执行的指令,转而去执行中断信号的处理程序
- 比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等
- 系统调用
- 用户态和内核态的区别
- 程序计数器PC和指令指针寄存器IP
- 程序计数器PC
- 用指令事先编好的程序连续存放在内存程序区中,靠地址+1的方法连续取指执行”。在八位机8080CPU中是采用先取指后执行的串行操作的原理,而其中执行地址+1指令寻址的部件就是程序计数器PC。那么在程序的执行过程中,PC始终是指向下一条要执行的指令
- 结论:PC中的地址就是需要转移、循环、调用子程序和中断子程序等操作时的断点
- 指令指针寄存器IP
- 在向上兼容的十六位机8086CPU中首先分为两个功能部件,即总线接口部件BIU和执行部件EU,BIU负责取指令,EU负责译码执行。并且当BIU执行指令排队栈中的六个字节装满后,(8088CPU是4个字节),EU开始从指令排队栈的出栈口,取指令进行译码执行,同时BIU并行操作向入栈口补充一条取指令命令
- 指令指针IP则是指向下个条要取指的指令,而不是EU要执行的指令。而断点则应该是要执行的指令内存地址,而不是IP内的下一条要取指的指令地址
- PC是模型机中的概念,IP是实际使用的,调试时我们发现,IP实现的就是PC的功能
- 程序计数器PC
进程管理
进程和线程
-
进程的概念:进程是程序在某个数据集合上的一次运行活动,也是操作系统进行资源分配和保护的基本单位」。通俗来说,「进程就是程序的一次执行过程」,程序是静态的,它作为系统中的一种资源是永远存在的。而进程是动态的,它是动态的产生,变化和消亡的,拥有其自己的生命周期
-
进程的组成
- 进程控制块 PCB。包含如下几个部分:
- 进程描述信息
- 进程控制和管理信息
- 资源分配清单
- CPU 相关信息
- 数据段。即进程运行过程中各种数据(比如程序中定义的变量)
- 程序段。就是程序的代码(指令序列)
- 进程控制块 PCB。包含如下几个部分:
-
进程上下文切换
- 首先,将进程 A 的运行环境信息存入 PCB,这个运行环境信息就是进程的上下文(Context)
- 然后,将 PCB 移入相应的进程队列
- 选择另一个进程 B 进行执行,并更新其 PCB 中的状态为运行态
- 当进程 A 被恢复运行的时候,根据它的 PCB 恢复进程 A 所需的运行环境
-
线程的概念:线程是独立调度的基本单位。一个进程中可以有多个线程,它们共享进程资源
-
同一进程中线程资源共享情况
- 线程共享的资源包括:进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理函数、进程的当前目录和进程用户ID与进程组ID
- 线程不共享的资源包括:
- 线程ID:每个线程都有自己的线程ID,这个ID在本进程中是唯一的。进程用此来标识线程
- 寄存器组的值:由于线程间是并发运行的,每个线程有自己不同的运行线索,当从一个线程切换到另一个线程上 时,必须将原有的线程的寄存器集合的状态保存,以便将来该线程在被重新切换到时能得以恢复
- 线程的堆栈:堆栈是保证线程独立运行所必须的。线程函数可以调用函数,而被调用函数中又是可以层层嵌套的,所以线程必须拥有自己的函数堆栈,使得函数调用可以正常执行,不受其他线程的影响
- 错误返回码(errno):由于同一个进程中有很多个线程在同时运行,可能某个线程进行系统调用后设置了errno值,而在该 线程还没有处理这个错误,另外一个线程就在此时被调度器投入运行,这样错误值就有可能被修改。所以,不同的线程应该拥有自己的错误返回码变量
- 线程的信号屏蔽码:由于每个线程所感兴趣的信号不同,所以线程的信号屏蔽码应该由线程自己管理。但所有的线程都共享同样的信号处理器
- 线程的优先级:由于线程需要像进程那样能够被调度,那么就必须要有可供调度使用的参数,这个参数就是线程的优先级
-
线程的优缺点
- 优点:
- 一个进程中可以同时存在多个线程,这些线程共享该进程的资源。进程间的通信必须请求操作系统服务(因为 CPU 要切换到内核态),开销很大。而同进程下的线程间通信,无需操作系统干预,开销更小。不过,需要注意的是:从属于不同进程的线程间通信,也必须请求操作系统服务
- 线程间的并发比进程的开销更小,系统并发性提升。同样,需要注意的是:从属于不同进程的线程间切换,它是会导致进程切换的,所以开销也大
- 缺点:
- 当进程中的一个线程奔溃时,会导致其所属进程的所有线程奔溃。举个例子,对于游戏的用户设计,就不应该使用多线程的方式,否则一个用户挂了,会影响其他同个进程的线程
- 优点:
-
进程和线程的区别
- 拥有资源
- 进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
- 调度
- 线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换
- 系统开销
- 进程在创建、切换和销毁时开销比较大,而线程比较小。进程创建的时候需要分配系统资源,而销毁的的时候需要释放系统资源。进程切换需要分两步:切换页目录、刷新TLB以使用新的地址空间;切换内核栈和硬件上下文(寄存器);而同一进程的线程间逻辑地址空间是一样的,线程切换时不需要切换页目录、刷新TLB,只需保存和设置少量寄存器内容,开销较小
- 进程在创建、销毁时开销比较大,而线程比较小。进程创建的时候需要分配虚拟地址空间、IO设备等系统资源,而销毁的的时候需要释放系统资源;线程只需要创建栈,栈指针,程序计数器,通用目的寄存器和条件码等,不需要创建独立的虚拟地址空间等系统资源
- 通信方面
- 线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC
- 拥有资源
-
多进程和多线程
- 多线程
- 多线程就是指一个进程中同时有多个线程正在执行
- 多线程原因
- 在一个程序中,有很多的操作是非常耗时的,如数据库读写操作,IO操作等,如果使用单线程,那么程序就必须等待这些操作执行完成之后才能执行其他操作。使用多线程,可以在将耗时任务放在后台继续执行的同时,同时执行其他操作,可以提高程序的效率
- 多线程优点
- 创建速度快,方便高效的数据共享
- 共享数据:多线程间可以共享同一虚拟地址空间;多进程间的数据共享就需要用到共享内存、信号量等IPC技术
- 较轻的上下文切换开销:不用切换地址空间(页表),不用更改CR3寄存器,不用刷新TLB
- 提供非均质的服务
如果全都是计算任务,但每个任务的耗时不都为1s,而是1ms-1s之间波动;这样,多线程相比多进程的优势就体现出来,它能有效降低“简单任务被复杂任务压住”的概率
- 多线程的缺点
- 使用太多线程,是很耗系统资源,因为线程需要开辟内存。更多线程需要更多内存
- 影响系统性能,因为操作系统需要在线程之间来回切换
- 需要考虑线程操作对程序的影响,如线程挂起,中止等操作对程序的影响,某个线程的崩溃会导致整个程序崩溃
- 多线程是异步的,但这不代表多线程真的是几个线程是在同时进行,实际上是系统不断地在各个线程之间来回的切换(因为系统切换的速度非常的快,所以给我们在同时运行的错觉)
- 适用场景
- 线程间有数据共享,并且数据是需要修改的(不同任务间需要大量共享数据或频繁通信时)
- 提供非均质的服务(有优先级任务处理)事件响应有优先
- 单任务并行计算,在非CPU Bound的场景下提高响应速度,降低时延
- 与人有IO交互的应用,良好的用户体验(键盘鼠标的输入,立刻响应)
- 多进程
- 多进程就是指计算机同时执行多个进程,一般是同时运行多个软件
- 优点
- 编程相对容易;通常不需要考虑锁和同步资源的问题
- 更强的容错性:比起多线程的一个好处是一个进程崩溃了不会影响其他进程
- 有内核保证的隔离:数据和错误隔离
- 对于使用如C/C++这些语言编写的本地代码,错误隔离是非常有用的:采用多进程架构的程序一般可以做到一定程度的自恢复;(master守护进程监控所有worker进程,发现进程挂掉后将其重启)
- 应用场景
- 多进程模型的优势是CPU
- 多线程模型主要优势为线程间切换代价较小,因此适用于I/O密集型的工作场景,因此I/O密集型的工作场景经常会由于I/O阻塞导致频繁的切换线程。同时,多线程模型也适用于单机多核分布式场景
- 多进程模型,适用于CPU密集型。同时,多进程模型也适用于多机分布式场景中,易于多机扩展
- 进程线程间创建的开销不足作为选择的依据,因为一般我们都是使用线程池或者进程池,在系统启动时就创建了固定的线程或进程,不会频繁的创建和销毁
- 首先,根据工作集(需要共享的内存)的大小来定;如果工作集较大,就用多线程,避免cpu cache频繁的换入换出;比如memcached缓存系统
- 其次,选择的依据根据以上多线程适用的场景来对比自身的业务场景,是否有这样场景需求:数据共享、提供非均质的服务,单任务拆散并行化等;
如果没有必要,或者多进程就可以很好的胜任,就多用多进程,享受单线程编程带来便利
- 多线程
-
高并发
- 高并发指的是是一种系统运行过程中遇到的一种“短时间内遇到大量操作请求”的情况,主要发生在web系统集中大量访问或者socket端口集中性收到大量请求(例如:12306的抢票情况;天猫双十一活动)。该情况的发生会导致系统在这段时间内执行大量操作,例如对资源的请求,数据库的操作等。如果高并发处理不好,不仅仅降低了用户的体验度(请求响应时间过长),同时可能导致系统宕机,严重的甚至导致OOM异常,系统停止工作等
-
多线程与高并发的联系
- 多线程只是在同/异步角度上解决高并发问题的其中的一个方法手段,是在同一时刻利用计算机闲置资源的一种方式
- 多线程在高并发问题中的作用就是充分利用计算机资源,使计算机的资源在每一时刻都能达到最大的利用率,不至于浪费计算机资源使其闲置
-
操作系统的设计,从进程和线程的角度来说,可以归结为三点:
- 以多进程形式,允许多个任务同时运行
- 以多线程形式,允许单个任务分成不同的部分运行
- 提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源
-
fork,vfork,clone
-
fork,vfork,clone都是linux的系统调用,这三个函数分别调用了sys_fork、sys_vfork、sys_clone,最终都调用了do_fork函数,差别在于参数的传递和一些基本的准备工作不同,主要用来linux创建新的子进程或线程(vfork创造出来的是线程)

-
fork
-
函数调用成功:返回两个值; 父进程:返回子进程的PID;子进程:返回0;失败:返回-1
-
写时复制技术(Copy-On-Write):其基础的观念是,如果有多个调用者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个调用者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到,这过程对其他的呼叫只都是通透的(transparently)。此作法主要的优点是如果呼叫者并没有修改该资源,就不会有副本(private copy)被建立
-
现在Linux系统调用fork利用COW技术,父进程和子进程共享页帧而不是复制页帧。然而,只要页帧被共享,它们就不能被修改,即页帧被保护。无论父进程还是子进程何时试图写一个共享的页帧,就产生一个异常,这时内核就把这个页复制到一个新的页帧中并标记为可写。原来的页帧仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页帧的唯一属主,如果是,就把这个页帧标记为对这个进程是可写的
-
fork前后内存关系
-
fork()创建了一个心的进程(child)信进程几乎是调用进程(父进程的翻版),理解fork()的关键是,在完成对其调用之后,会产生2个进程,且每个进程都会从fork()的返回处开始执行
-
这俩个进程将执行相同的程序段,但是拥有各自不同的堆段,栈段,数据段,每个子程序都可修改各自的数据段,堆段,和栈段
-
调用fork()之后先执行哪个进程的是由Linux下专有文件/proc/sys/kernel/sched_child_runs_first的值来确定的(值为0父进程先执行,非0子进程先执行)
-
fork后子进程只复制父进程的页表,父子进程的代码段是相同的,所以代码段是没必要复制的,因此内核将代码段标记为只读,这样父子进程就可以安全的共享此代码段了。fork之后在进程创建代码段时,新子进程的进程级页表项都指向和父进程相同的物理页帧

-
而对于父进程的数据段,堆段,栈段中的各页,由于父子进程要相互独立,所以我们采用写实复制的技术,来最大化的提高内存以及内核的利用率。刚开始,内核做了一些设置,令这些段的页表项指向父进程相同的物理内存页。调用fork之后,内核会捕获所有父进程或子进程针对这些页面的修改企图(说明此时还没修改)并为将要修改的页面创建拷贝。系统将新的页面拷贝分配给被内核捕获的进程,还会对子进程的相应页表项做适当的调整,现在父子进程就可以分别修改各自的上述段,不再互相影响了
-
COW前

-
COW后

-
-
-
vfork
- 是一个过时的应用,vfork也是创建一个子进程,但是子进程共享父进程的空间。在vfork创建子进程之后,父进程阻塞,直到子进程执行了exec()或者exit()
- vfork最初是因为fork没有实现COW机制,而很多情况下fork之后会紧接着exec,而exec的执行相当于之前fork复制的空间全部变成了无用功,所以设计了vfork。而现在fork使用了COW机制,唯一的代价仅仅是复制父进程页表的代价,所以vfork不应该出现在新的代码之中
- 由vfork创建的子进程要先于父进程执行,子进程执行时,父进程处于挂起状态,子进程执行完,唤醒父进程。除非子进程exit或者execve才会唤起父进程
- vfork()用法与fork()相似,但是也有区别,具体区别归结为以下3点
- fork() 子进程拷贝父进程的数据段,代码段,vfork() 子进程与父进程共享数据段
- fork() 父子进程的执行次序不确定,vfork(),保证子进程先运行
- vfork()保证子进程先运行,在它调用exec或_exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁
-
clone
- 是Linux为创建线程设计的(虽然也可以用clone创建进程)。所以可以说clone是fork的升级版本,不仅可以创建进程或者线程,还可以指定创建新的命名空间(namespace)、有选择的继承父进程的内存、甚至可以将创建出来的进程变成父进程的兄弟进程等等
- clone函数功能强大,带了众多参数,它提供了一个非常灵活自由的常见进程的方法。因此由他创建的进程要比前面2种方法要复杂。clone可以让你有选择性的继承父进程的资源,你可以选择想vfork一样和父进程共享一个虚存空间,从而使创造的是线程,你也可以不和父进程共享,你甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg); // fn为函数指针,此指针指向一个函数体,即想要创建进程的静态程序(我们知道进程的4要素,这个就是指向程序的指针,就是所谓的“剧本", ); // child_stack为给子进程分配系统堆栈的指针(在linux下系统堆栈空间是2页面,就是8K的内存,其中在这块内存中,低地址上放入了值,这个值就是进程控 // 制块task_struct的值); // arg就是传给子进程的参数一般为(0); // flags为要复制资源的标志,描述你需要从父进程继承那些资源以下是flags可取的值

-
clone和fork的区别:
- clone和fork的调用方式很不相同,clone调用需要传入一个函数,该函数在子进程中执行
-
-
clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。 (void *child_stack)也就是第二个参数,需要分配栈指针的空间大小,所以它不再是继承或者复制,而是全新的创造
协程
-
基本概念
-
**协程,英文Coroutines,是一种比线程更加轻量级的存在。**正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程

-
-
进程,线程,协程的上下文切换
- 进程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户是无感知的。进程的切换内容包括页全局目录、内核栈、硬件上下文,切换内容保存在内存中。进程切换过程是由“用户态到内核态到用户态”的方式,切换效率低
- 线程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户无感知。线程的切换内容包括内核栈和硬件上下文。线程切换内容保存在内核栈中。线程切换过程是由“用户态到内核态到用户态”, 切换效率中等
- 协程的切换者是用户(编程者或应用程序),切换时机是用户自己的程序所决定的。协程的切换内容是硬件上下文,切换内存保存在用户自己的变量(用户栈或堆)中。协程的切换过程只有用户态,即没有陷入内核态,因此切换效率高
- 协程是轻量级线程,拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈
- 协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态
-
协程相比进程和线程的优势
- 协程拥有极高的执行效率。因为子程序切换不是线程切换,协程不是被操作系统内核所管理,而是由程序自身完全控制(完全运行在用户态),因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显
- 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多
-
应用场景
- I/O 密集型任务
- 这一点与多线程有些类似,但协程调用是在一个线程内进行的,是单线程,切换的开销小,因此效率上略高于多线程
- 当程序在执行 I/O 时操作时,CPU 是空闲的,此时可以充分利用 CPU 的时间片来处理其他任务。在单线程中,一个函数调用,一般是从函数的第一行代码开始执行,结束于 return 语句、异常或者函数执行(也可以认为是隐式地返回了 None )
- 有了协程,我们在函数的执行过程中,如果遇到了耗时的 I/O 操作,函数可以临时让出控制权,让 CPU 执行其他函数,等 I/O 操作执行完毕以后再收回控制权
- I/O 密集型任务
-
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能
-
python协程完成生产者-消费者问题例子(Python对协程的支持还非常有限,用在generator中的yield可以一定程度上实现协程)
import time def consumer(): r = '' while True: n = yield r if not n: return print('[CONSUMER] Consuming %s...' % n) time.sleep(1) r = '200 OK' def produce(c): c.next() n = 0 while n < 5: n = n + 1 print('[PRODUCER] Producing %s...' % n) r = c.send(n) print('[PRODUCER] Consumer return: %s' % r) c.close() if __name__=='__main__': c = consumer() produce(c)注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
- 首先调用c.next()启动生成器;
- 然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
- consumer通过yield拿到消息,处理,又通过yield把结果传回;
- produce拿到consumer处理的结果,继续生产下一条消息;
- produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务
-
支持协程的编程语言
- Lua语言
- Python语言
- Go语言
- Java语言(Kilim框架)
同步互斥
-
生产者-消费者问题(C++11实现)
#include <thread> #include <mutex> #include <condition_variable> #include <queue> #include <cstdlib> #include <iostream> std::mutex mtx; std::condition_variable prodCond; std::condition_variable consCond; const int QSIZE = 50; std::queue<int> blockQueue; volatile bool isClose = false; void producer(int id){ while(!isClose){ long item = 1 + rand() % 99; // produce item in range [1,100] std::unique_lock<std::mutex> locker(mtx); while(blockQueue.size() >= QSIZE) prodCond.wait(locker); // 释放锁,等待,醒来时获得锁 std::cout<<"Producer " << id <<" produces item "<< item <<std::endl; blockQueue.push(item); // insert item locker.unlock(); consCond.notify_all(); } std::cout<<"Producer " << id <<" finished!"<<std::endl; } void consumer(int id){ while(!isClose){ std::unique_lock<std::mutex> locker(mtx); while(blockQueue.size() == 0) consCond.wait(locker); int item = blockQueue.front(); // consumes item std::cout<<"Consumer " << id <<" cosumes item "<< item << std::endl; blockQueue.pop(); // remove item locker.unlock(); prodCond.notify_all(); } std::cout<<"Consumer " << id <<" finished!"<<std::endl; } int main(int argc, char * argv[]){ const int num = 2; std::vector<std::thread> producers(num); std::vector<std::thread> consumers(num); for(int i = 0; i < num; i++){ producers[i] = std::thread(producer, i+1); consumers[i] = std::thread(consumer, i+1); } sleep(1); isClose = true; for(int i = 0; i < num; i++){ producers[i].join(); consumers[i].join(); } return 0; } -
读者-写者问题
#include <thread> #include <mutex> #include <iostream> std::mutex mtx; std::mutex cntMtx; size_t readCount = 0; // std::atomic<size_t> readCount; volatile bool isClose = false; void reader(int id){ while(!isClose){ std::unique_lock<std::mutex> cntLock(cntMtx); // 用于读者互斥计数 readCount++; if(readCount == 1) mtx.lock(); // 第一个读者,加锁 cntLock.unlock(); std::cout<<"Reader " << id <<" reads "<< item <<std::endl; cntLock.lock(); readCount--; if(readCount == 0) // 已无读者,解锁唤醒写者 mtx.unlock(); cntLock.unlock(); } std::cout<<"Reader " << id <<" finished!"<<std::endl; } void writer(int id){ while(!isClose){ mtx.lock(); // 读写互斥锁 std::cout<<"Writer " << id <<" writes "<< item << std::endl; mtx.unlock(); // 解锁 } std::cout<<"Writer " << id <<" finished!"<<std::endl; } int main(int argc, char * argv[]){ const int num = 2; std::vector<std::thread> writers(num); std::vector<std::thread> readers(num); for(int i = 0; i < num; i++){ writers[i] = std::thread(writer, i+1); readers[i] = std::thread(reader, i+1); } sleep(1); isClose = true; for(int i = 0; i < num; i++){ writers[i].join(); readers[i].join(); } return 0; }
死锁
-
死锁
- 死锁是多线程中最差的一种情况,多个线程相互占用对方的资源的锁,而又相互等对方释放锁,此时若无外力干预,这些线程则一直处理阻塞的假死状态,形成死锁
-
死锁检测与避免
-
产生死锁的四大必要条件
- 资源互斥/资源不共享:每个资源要么已经分配给了一个进程,要么是可用的,只有这两种状态,资源不可以被共享使用,所以所谓的互斥是指:资源不共享,如果被使用,只能被一个进程使用
- 占有和等待/请求并保持:已经得到资源的进程还能继续请求新的资源
- 资源不可剥夺:当一个资源分配给了一个进程后,其它需要该资源的进程不能强制性获得该资源,除非该资源的当前占有者显示地释放该资源
- 环路等待:死锁发生时,系统中一定有由两个或两个以上的进程组成的一条环路,环路上的每个进程都在等待下一个进程所占有的资源
-
预防死锁
- 预防死锁的发生只需破坏死锁产生的四个必要条件之一即可
- 下面的方法开销非常之大,目前没有一个操作系统可以实现
- 破坏互斥条件:如果允许系统资源都能共享使用,则系统不会进入死锁状态; 缺点:有些资源根本不能同时访问,如打印机等临界资源只能互斥使用。所以,破坏互斥条件而预防死锁的方法不太可行,而且在有的场合应该保护这种互斥性
- 破坏请求并保持条件:釆用预先静态分配方法,即进程在运行前一次申请完它所需要的全部资源,在它的资源未满足前,不把它投入运行。一旦投入运行后,这些资源就一直归它所有,也不再提出其他资源请求,这样就可以保证系统不会发生死锁。缺点:系统资源被严重浪费,其中有些资源可能仅在运行初期或运行快结束时才使用,甚至根本不使用。而且还会**导致“饥饿”**现象,当由于个别资源长期被其他进程占用时,将致使等待该资源的进程迟迟不能开始运行
- 破坏不可剥夺条件:当一个已保持了某些不可剥夺资源的进程,请求新的资源而得不到满足时,它必须释放已经保持的所有资源,待以后需要时再重新申请。这意味着,一个进程已占有的资源会被暂时释放,或者说是被剥夺了,或从而破坏了不可剥夺条件。缺点:该策略实现起来比较复杂,释放已获得的资源可能造成前一阶段工作的失效,反复地申请和释放资源会增加系统开销,降低系统吞吐量。这种方法常用于状态易于保存和恢复的资源,如CPU的寄存器及内存资源,一般不能用于打印机之类的资源
- 破坏循环等待条件:为了破坏循环等待条件,可釆用顺序资源分配法。首先给系统中的资源编号,规定每个进程,必须按编号递增的顺序请求资源,同类资源一次申请完。也就是说,只要进程提出申请分配资源Ri,则该进程在以后的资源申请中,只能申请编号大于Ri的资源。缺点: 这种方法存在的问题是,编号必须相对稳定,这就限制了新类型设备的增加;尽管在为资源编号时已考虑到大多数作业实际使用这些资源的顺序,但也经常会发生作业使用资源的顺序与系统规定顺序不同的情况,造成资源的浪费;此外,这种按规定次序申请资源的方法,也必然会给用户的编程带来麻烦
- 因此,目前使用的方法是避免死锁,而不是预防死锁
-
避免死锁的算法
-
判断“系统安全状态”法:在进行系统资源分配之前,先计算此次资源分配的安全性。若此次分配不会导致系统进入不安全状态,则将资源分配给进程; 否则,让进程等待

- 图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
- 定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的
- 安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比
-
银行家算法
- 申请的贷款额度不能超过银行现有的资金总额
- 分批次向银行提款,但是贷款额度不能超过一开始最大需求量的总额
- 暂时不能满足客户申请的资金额度时,在有限时间内给予贷款
- 客户要在规定的时间内还款
-
单个资源银行家算法
-
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配
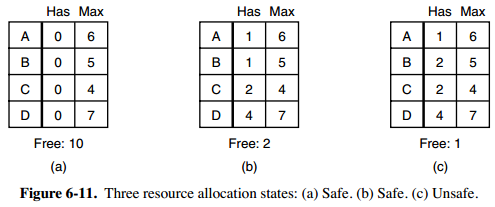
上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态
-
-
多个资源银行家算法

- 上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0
- 检查一个状态是否安全的算法如下:
- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的
- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中
- 重复以上两步,直到所有进程都标记为终止,则状态时安全的
- 如果一个状态不是安全的,需要拒绝进入这个状态
-
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









