









背景引入
实习过程中,接到一个需求,里面有个要计算中位数的字段,之前没见过,遂记录。
愣头青方法
一切的一切数据先排序。
常规不用hive的解决方法是:首先添加两列字段,这两列分别是score所在的位置、总数据个数。然后可以对数据(为位置+1和位置+2)进行平均分,然后用where in进行过滤筛选。这里的逻辑筛选后,可以得到得到一行数据和两行数据(分别对应奇数和偶数,如果是偶数的话,你这样+2然后除2得到是个带小数点的数值,筛选就找不到她了),然后用对筛选出来的数据进行一个avg( )就可以了。
with data1 as (
select 1 as uid, 65 as score union all
select 1 as uid, 68 as score union all
select 1 as uid, 76 as score union all
select 1 as uid, 95 as score union all
select 1 as uid, 68 as score union all
select 1 as uid, 84 as score union all
select 1 as uid, 79 as score
),
data2 as (
select * from data1 order by score desc
),
-- 得到分数在对应数列的位置,以及计算出总位数
data3 as (
select
uid,
score,
row_number() over (partition by uid order by score desc) as score_rnk,
count(*) over() as total_score_num
from data2
)
select
avg(score) as median
from (
select
uid,
score
from data3
where score_rnk in ((total_score_num+1)/2, (total_score_num+2)/2)
)a
group by uid
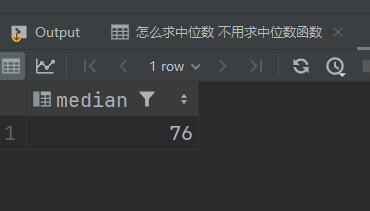
Hive自带函数
这两个函数都可以用来求中位数(这两个函数其实是用来在p分为上的值)。
percentile( )
这个函数相比下面那个更加精确,但是内存消耗也会偏大计算速率也会较为低下。
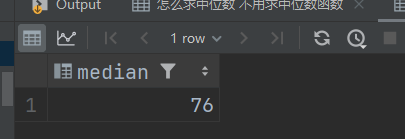
展现一样的结果
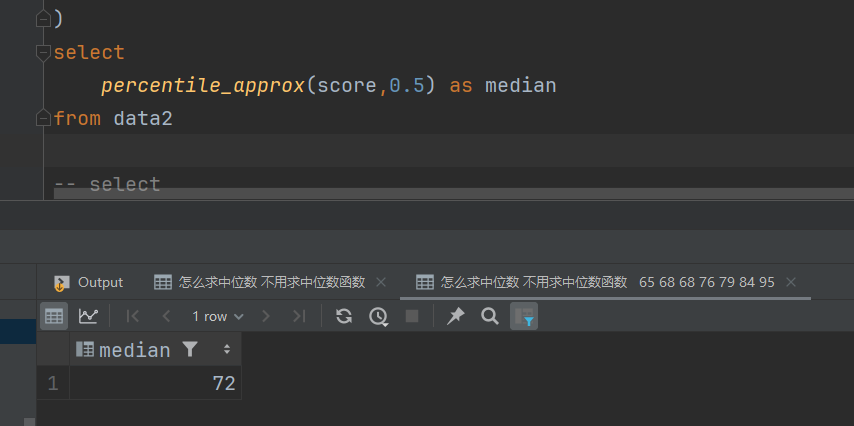
percentile_approx( )
这一个函数则是得到近似分布的值,相对没那么精确,但是他比较适合大规模数据集,数据仓库ETL中可能用它更加合适。















 5202
5202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









