







目录
项目链接
问题
问题1 这个reward_scale缩放系数是什么东西?
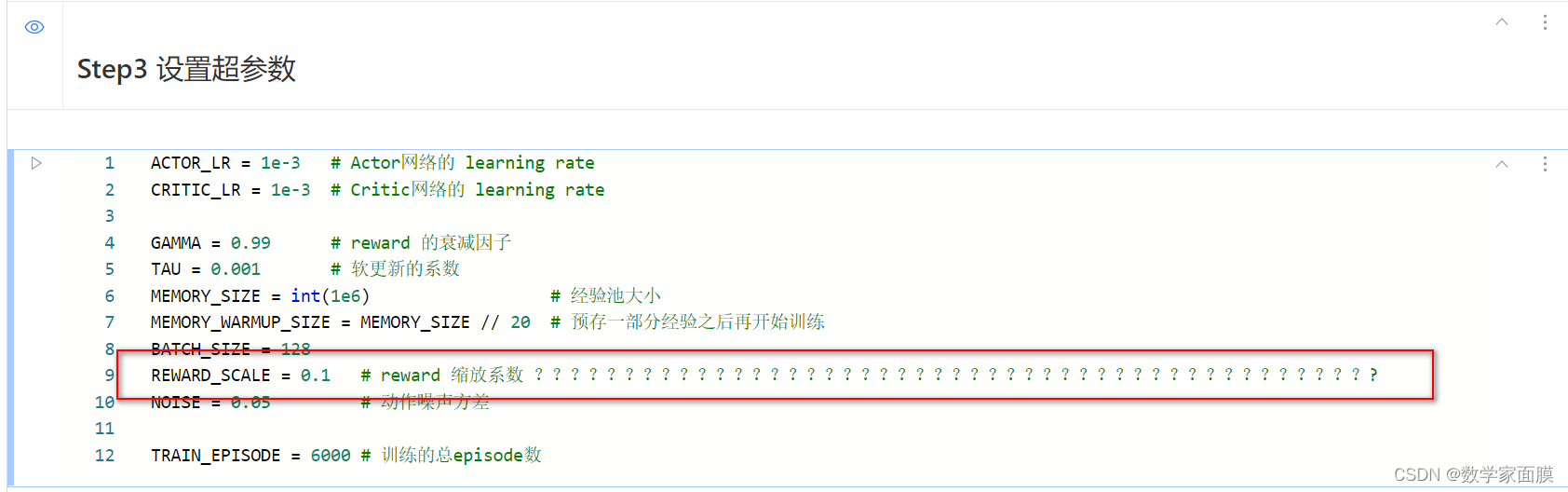
答:
在env返回的reward的基础上乘以这个系数,
在模型中,为了计算target_Q会用到reward, 对损失的计算会有一定影响,感觉和学习率会有差不多的作用吧。
问题2 means是输出的列表还是一个平均数?
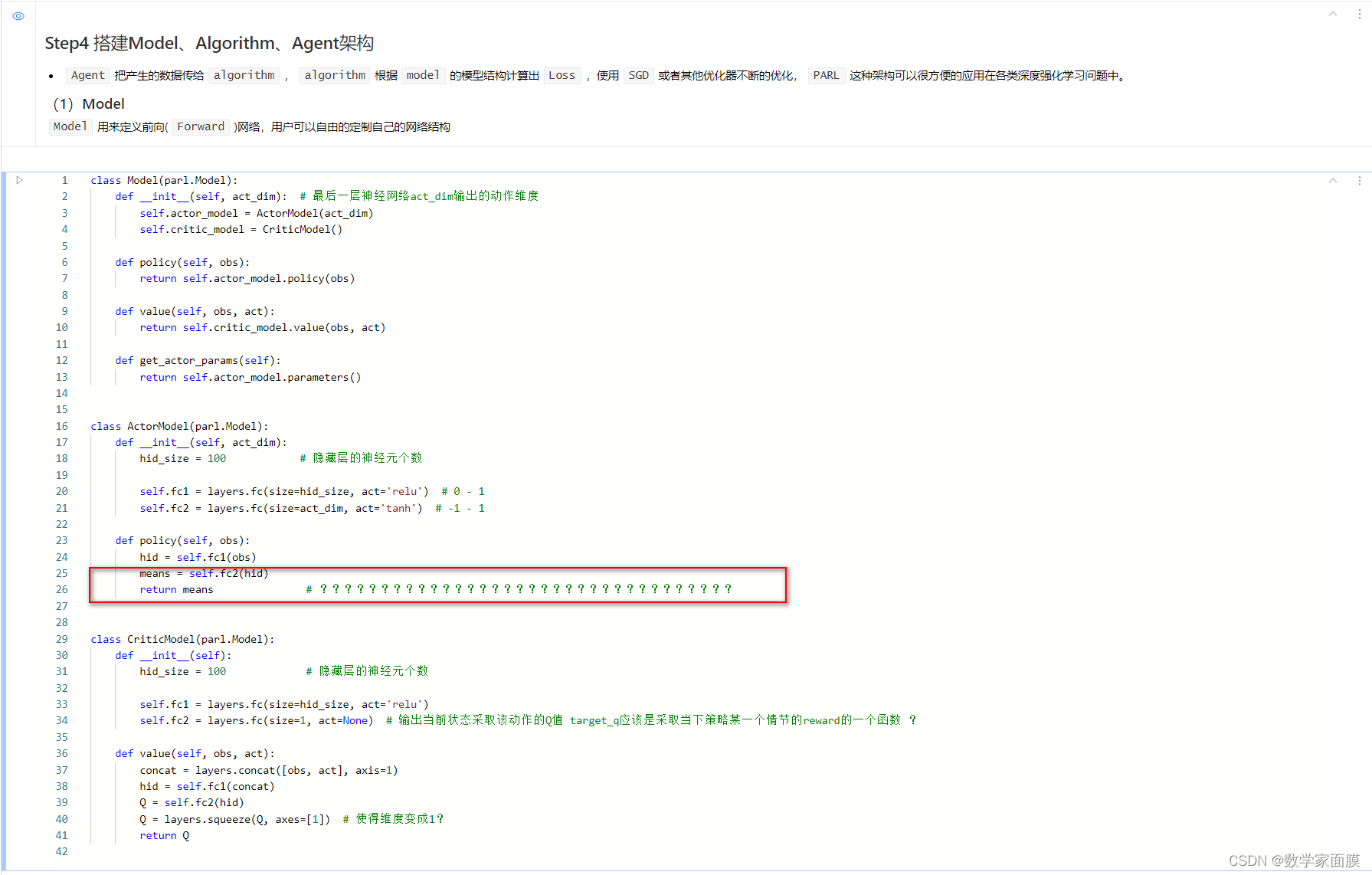
答:这直接就是DDPG输出的确定动作了吧。
问题4 为什么有了tau还要搞一个decay这样绕一下呢,decay是什么意思啊,小晕>_<
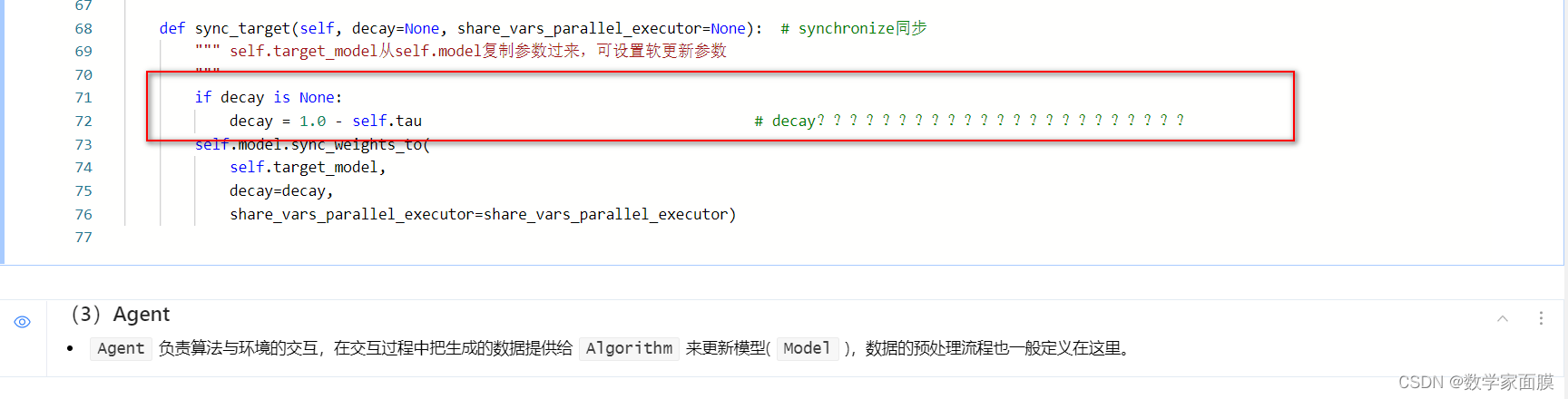

答:decay应该就是要废弃掉的更新参数,decay=0,就是一点都不舍弃,同步更新。
问题5 想自己建一个项目中的env,要学习什么?
答:自己搞一个env真地是会遇到很多问题和要注意的地方啊!!!有时候env的observation或者action设置太大之后,可能模型生成经验池的时候内存就直接爆炸了!内存是真的有限啊,感觉个人很难搞很大的数据集!
问题6 模型什么时候需要调参,怎么调参,要交叉验证什么的吗,感觉强化学习的训练时间都很长,调参是不是会很难?
不懂QAQ















 1626
1626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









