







向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT机器学习 公众号: datayx
词向量
word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。
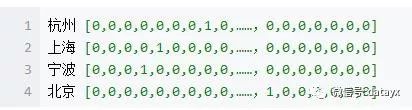
比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。

我们可以发现,华盛顿和纽约聚集在一起,北京上海聚集在一起,且北京到上海的距离与华盛顿到纽约的距离相近。也就是说模型学习到了城市的地理位置,也学习到了城市地位的关系。
模型拆解
word2vec模型其实就是简单化的神经网络。
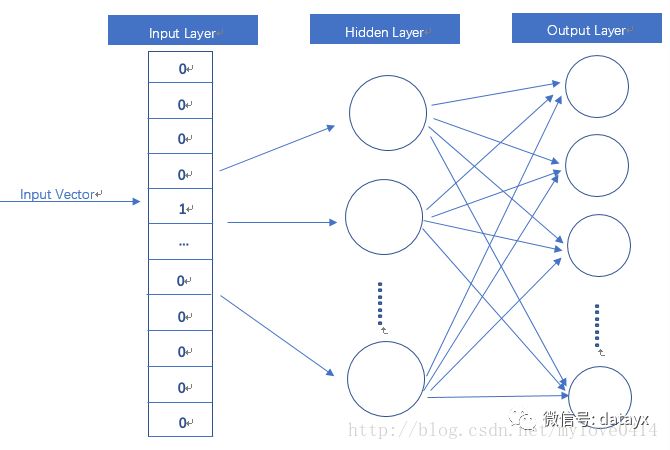
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。有的地方定为Input Layer和Hidden Layer之间的权重,其实说的是一回事。 
CBOW与Skip-Gram模式
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
训练优化
额,到这里,你可能会注意到,这个训练过程的参数规模非常巨大。假设语料库中有30000个不同的单词,hidden layer取128,word2vec两个权值矩阵维度都是[30000,128],在使用SGD对庞大的神经网络进行学习时,将是十分缓慢的。而且,你需要大量的训练数据来调整许多权重,避免过度拟合。数以百万计的重量数十亿倍的训练样本意味着训练这个模型将是一个野兽。
一般来说,有Hierarchical Softmax、Negative Sampling等方式来解决。
基于word2vec的文档语义分析
处理金庸小说文档
主要分析使用word2vec进行文档(此处指由字符串表示的文档)的与语义分析。使用gensim包的word2vec模型对文库进行训练,得到目标模型后,我们可进一步作如下研究:
1)判断任意两个词汇的相似度。此处的相似度指余弦相似度【1,similarity(w1, w2)】。
2)给定一个词汇,找到与之最相似的n个词汇。
3)对词汇进行聚类,例如kMeans聚类,层次聚类等。因为word2vec的目标向量空间是对词汇语义的相对准确描述,因此聚类时可以得到较好的结果。
1.2开发环境
本文所述算法以Python实现。所用到的包如下:
1)scipy:科学计算
2)matplotlib:绘图
3)gensim:语义分析
4)sklearn:机器学习
5)jieba:中文分词
1.3 实验环境
本文对金庸小说进行人物、功夫、帮派的语义上下文分析。事先准备的实验资源为:
1)金庸小说的本文文件
2)人名列表
3)功夫名称列表
4)帮派名称列表
二样本
本章可参考【2】。
2.1 文档
文档(Document)可描述为一个由单词组成的集合。而多个文档则组成文档集合。例如:
["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"]
每一行是一个文档,而所有的文档组成一个文档集合。这些文档可以作为训练语义模型的样本。
2.2 分词
文档必须分割为单词序列。
对于英文文档,可直接使用split()方法,依据空格进行分割。
对于中文,则必须用词库进行匹配。此处使用的是jieba分词包。如果希望给jieba提供自定义此库,可用以下方法实现:
for wordin words:
jieba.add_word(word)
使用cut方法进行分词:
jieba.cut(line)
分词之后将得到以下对象(此例子是从【2】中参考的,其中英文介词已经被去掉):
[['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'],
['system', 'human', 'system', 'eps'],
['user', 'response', 'time'],
['trees'],
['graph', 'trees'],
['graph', 'minors', 'trees'],
['graph', 'minors', 'survey']]
三 word2vec训练
3.1 实现
直接调用gensim的相应方法即可:
model = gensim.models.Word2Vec(sentences,
size=100,
window=5,
min_count=5,
workers=4)
该方法的参数如下:
sentences:训练集,即前述2.2中的分词结果列表。
Size:目标向量的长度。如果取100,则生成长度为100的向量。
Window:窗口大小,计算时所用的控制参数。控制当前词汇和预测词汇之间可能的最大距离。Window值越大,所需要枚举的预测词汇越多,计算时间越长。
Min_count:最小出现次数。此处意为出现次数少于5次的词汇将被忽略。
Workers:训练时使用的线程数。
3.2 Word2vec原理
Word2vec是用来重构语义上下文的算法,它将词汇空间映射到一个高维实向量空间中(维度的典型大小是几百)。其发明者为Google的Tomas Mikolov,其原始论文在【3】。根据Mikolov,此系列算法非常注重词汇的上下文和语义,因此有别于传统NLP领域中将词汇看作是原子对象的做法,因而在NLP中取得了突破性的成功,而且被广泛应用。
其现在常用的实现方式是两层神经网络。它的基本思想是词汇的语义相似度,可以由其对应向量的余弦相似度表示。因此在目标空间中,相似的词汇其向量将聚集为一处。因为维度较高,所以向量对空间的填充密集度很小,因此模型的敏感度较高。对Word2vec的数学原理分析可见【4】。
对于Word2vec的形象解释可见【5】。请参见其中举的如下示例。
China:Taiwan::Russia:[Ukraine, Moscow, Moldova, Armenia] //Two large countries and their small, estranged neighbors
house:roof::castle:[dome, bell_tower, spire, crenellations, turrets]
前者China和Taiwan的关系,与Russia和例如Ukraine的关系相似。此处可以看到Word2vec的语义本质:它可以描述两个概念之间的语义关系,而这种语义关系完全是通过文档样本的学习来实现的,它不要求有任何对现实世界的语义建模输入(例如何为国家、国力、接壤等)。一方面在现阶段进行常识建模的计算量非常大以至于不切合实际,另外也说明足够量的样本已经可以暴露出蕴含在其中的深层次语义概念。
四获取相似度
4.1 获取两个词汇的相似度
给定两个词汇w1和w2,S=similarity(w1, w2),0<=S<=1为w1和w2的相似度。S=1为最相似,S=0为最不相似。
在实验中,我们设定:
name1=’小龙女’
names2=[‘李莫愁’, ‘周伯通’, ‘裘千尺’, ‘尼摩星’, ’杨过’,’黄蓉’,’郭靖’]
对[(w2,Si)]=S(w1, w2i)进行遍历:
results = {};
fori in range(0, len(names2)):
results[names2[i]] = model.similarity(name1, names2[i])
得到下面的结果。
李莫愁 0.894659744382
黄蓉 0.747729452107
尼摩星 0.562424555626
郭靖 0.714265416622
裘千尺 0.875459754365
周伯通 0.827707519769
杨过 0.969947306579
可以看到和“小龙女”最相关的人物为“杨过”。
4.2 给定词汇获取相似度列表
我们希望找到某一个词汇的相似词汇列表。例如寻找和“小龙女”最相关的30个人名,可以用以下方法实现:
for k, s in model.most_similar(positive=[u'小龙女'], topn=30):
if k in names:
print k, s
非人名词汇已经被过滤掉,因此列表中的人名不足30条。输出结果为:
杨过0.963029921055
李莫愁0.91172337532
郭芙0.906970024109
郭襄0.898455142975
裘千尺0.891280293465
周伯通0.855596780777
赵志敬0.850557327271
孙婆婆0.838372588158
陆无双0.836666166782
公孙止0.79715013504
完颜萍0.780711233616
武修文0.775943934917
耶律齐0.770159721375
黄蓉0.766984045506
洪七公0.763851702213
柯镇恶0.755305945873
朱子柳0.753480374813
4.3 匹配关系
此处叙述如何寻找匹配关系。所谓匹配关系,是指针对A和B之间的关系(A, B),如果给定C,求D,使得C和D之间的关系(C, D)是同性质的。例如【1】中most_similar中所举的示例:
trained_model.most_similar(positive=['woman', 'king'], negative=['man']) [('queen', 0.50882536), ...]
满足
man:king::wonen:queen
即(man, king)与(women, queen)两个关系的性质相同。另见【5】中Amusing Word2vec Results部分。
匹配关系的重构,可以看做是对潜在语义的发现。其原理仍然是根据向量的余弦相似性。即寻找一个词汇,其与women相关(性别),同时又与king相关(职位),但与man逆相关。
本实验中我们寻找如下的匹配关系:
小龙女:杨过::黄蓉:?
杨过:小龙女::郭靖:?
使用如下的方法:
items = model.most_similar(positive=[u'黄蓉', u'杨过'], negative=[u'小龙女'])
forr,s in items:
if r in names:
print r, s
得到的结果为:
1)
郭芙0.888121366501
郭靖0.8785790205
武修文0.872470200062
周伯通0.865872621536
丘处机0.861464202404
赵志敬0.861455023289
陆无双0.851740598679
朱子柳0.849289953709
2)
黄蓉0.875000953674
黄药师0.835819602013
丘处机0.828815102577
朱子柳0.803559422493
完颜萍0.802824795246
洪七公0.79979300499
可以看到匹配结果基本准确。
五人物姓名聚类分析
5.1 前提
在此我们以Word2vec产生的词汇向量对《神雕侠侣》中的人物姓名作kMeans聚类。一个词汇的Word2vec向量紧凑地表示了它所处的上下文环境和基本语义,因此用它作为聚类的输入,可预期相关人物将会被归为一类。一般在小说情节上,我们可以列举出如下的常见聚类方式:
1) 自然亲属关系:类别中的人物具有夫妻、父子、妇女、母子、母女等亲属关系。
2) 社区关系:类别中的人物同属于一个社区(Community),例如公司、组织、派别、阵营等。
3) 意识形态关系:类别中的人物具有基本相同的意识形态或政治取向。
4) 性格关系:类别中的人物同属于基本相同的性格特质或人格特征。例如进取、冒险、独断、勇敢,或懦弱、虚伪、顺从、自大、贪婪等。
5) 经历关系:类别中的人物具有类似的人生经历。例如深入敌方卧底、被国君冤杀、从草根到英雄等小说中的常见套路。
现阶段从Word2vec的表象来看,Word2vec的训练算法对一个词汇只能产生一个向量,即它对词汇的语义归属只具有单一的解释。它对语义的分析并非根据常识建模,也非根据自然语言的语法规则,而是根据词汇的统计学规律对词汇单元做出的统计性散列。根据聚类结果,我们无从直观上判断某一类别的归类法则。因此对Word2vec向量聚类的实际语义取向以及其潜在分析价值,有待于对Word2vec方法作进一步深入研究后,方可得出准确结论。
5.2 实验设计
1)对《神雕侠侣》中的所有人物姓名集合S,首先以K=5运行kMeans聚类。
2)认为越小的类别其类别内聚性越大。因此去掉最大的两个类别中的人物,将其余人物收集为一个新的集合S1(kMeans聚类算法本身无法判断离群点的存在,因此需要集合其他统计性方法识别并过滤离群点)。
3)对S1以K=8运行kMeans聚类,得到类别C0-C7。
使用sklearn进行kMean聚类的代码段如下:
names = [name for name in load_names()[u'神雕侠侣'] if name in model]
name_vectors = [model[name] for name in names]
n = 5
label = KMeans(n).fit(name_vectors).labels_
首先获取到小说中的所有人物姓名,即names。
然后创建names对应的Word2vec向量列表name_vectors。Model即实现训练好的Word2vec模型。
最后调用KMeans的fit方法进行聚类。Fit仍然返回KMeans对象,其labels_属性范围对每一个向量的分类标号组成的列表。
5.3 实验结果
第1遍
类别0:
子聪丁大全人厨子小棒头尹志平王十三小王将军王惟忠无常鬼申志凡
史伯威史仲猛圣因师太祁志诚吊死鬼百草仙陆二娘阿根张志光陆冠英
陈大方觉远大师沙通天张一氓灵智上人耶律楚材丧门鬼青灵子柔儿郭破虏
宋五笑脸鬼崔志方鄂尔多萨多彭连虎韩无垢童大海瘦丐蒙哥
煞神鬼蓝天和
类别1:
公孙止尹克西尼摩星达尔巴朱子柳完颜萍武三通武敦儒忽必烈耶律齐
洪凌波柯镇恶洪七公黄药师潇湘子霍都樊一翁
类别2:
小龙女孙婆婆李莫愁陆无双杨过武修文周伯通赵志敬郭芙郭襄
裘千尺
类别3:
马钰大头鬼一灯大师王处一王志坦天竺僧少妇公孙绿萼孙不二冯默风
史叔刚史季强刘处玄李志常宋德方张君宝林朝英耶律燕点苍渔隐鹿清笃
鲁有脚彭长老裘千仞
类别4:
丘处机郭靖黄蓉 42
去掉类别0和3
第2遍
类别0:
丘处机朱子柳黄药师
类别1:
孙婆婆武修文裘千尺
类别2:
小龙女杨过
类别3:
公孙止尹克西达尔巴完颜萍武三通武敦儒忽必烈洪凌波柯镇恶洪七公
霍都樊一翁
类别4:
陆无双郭芙郭襄
类别5:
尼摩星潇湘子
类别6:
郭靖黄蓉
类别7:
李莫愁耶律齐周伯通赵志敬
六结语
6.1 结论
本文通过使用Word2vec模型作为实验工具,对金庸小说《神雕侠侣》进行了人物相似度和人物聚类分析。
6.2 进一步工作
1)本实验在此方面留下很多问题,需对其做进一步深入研究。对Word2vec的语义取向方式尚不明晰,有很多可能的解释方式:a)Word2vec忽略了语义相似定义的场合(语义上下文),b)Word2vec的散列方式是对所有可能语义取向方式的加权平均函数,因此并没有忽略场合,c)Word2vec的语义相似定义方式与常识并无必然联系。另有研究者表明对Word2vec在语义重构方面成功的原因表示尚不清楚【6】。因此还有待研究本文中提出的问题与前述研究者所表述是否为同一概念。另外对【7】的研究可能会解释前述的某些问题,因为该文章中说明了在NLP领域中研究者所关注的“语义”的真实含义。
2)有待于在小说文本中挖掘更多的可能性。例如把人物归属为帮派等,但此工作与本文中所述直接使用Word2vec的向量有明显区别。现考虑此工作可能需要结合人工特征工程方法实现。
https://zhuanlan.zhihu.com/p/21457407
搜索公众号添加: datayx
不断更新资源
深度学习、机器学习、数据分析、python

长按图片,识别二维码,点关注














 2539
2539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









