






 本文介绍了如何使用Python的jieba库进行中文文本分词,并利用Word2Vec模型进行词嵌入。步骤包括数据预处理、模型选择与配置,以及实际应用中的词向量获取和相似词语查找。
本文介绍了如何使用Python的jieba库进行中文文本分词,并利用Word2Vec模型进行词嵌入。步骤包括数据预处理、模型选择与配置,以及实际应用中的词向量获取和相似词语查找。
一、技术路线
使用Python中的jieba库来进行中文分词和文本预处理。
首先准备数据集,本数据集是从微信推送中选取的一篇推送,链接为:
其次,使用jieba库进行分词,文本进行中文分词,将文本分解成单词或词语,移除停用词和标点符号。然后,将处理后的文本写入新文本文件中,其中不包含“的”、“地”、“得”、逗号、句号等不需要的词语和标点符号,分段新文本用于进行词嵌入模型。
然后,选择词嵌入模型,本次使用的是Word2Vec模型。并配置模型参数,比如词向量维度、上下文窗口大小等。
最后,使用训练好的词嵌入模型可以来获取词语的向量表示。这些向量可以用于各种自然语言处理任务,如文本分类、情感分析、文档相似性计算等。
二、jieba库
jieba(结巴)是一款流行的中文分词工具,用于将中文文本切分成词语。它支持全模式、精确模式和搜索引擎模式等多种分词模式,适用于各种自然语言处理任务。jieba库是基于Python实现的,可帮助研究人员和开发人员在中文文本处理中轻松进行分词和词汇处理,可以用于文本挖掘、信息检索和文本分析等任务。
tips:AttributeError: partially initialized module 'jieba' has no attribute 'cut' (most likely due to a circular import)是什么错误?
这个错误通常是因为在导入 jieba 模块时发生了循环引用,或者在某种方式下未正确导入模块。这个错误可能是由不正确的模块导入顺序或配置问题引起的。
1检查模块导入顺序:确保你在使用 jieba 之前正确导入它。2检查模块名字:确保你没有将自己的脚本或文件命名为与标准库模块相同的名字(比如,不要将你的脚本命名为jieba.py),因为这可能会导致混淆。3重新安装jieba。4检查python环境
三、Word2Vec模型
Word2Vec是一种用于学习词嵌入的深度学习模型,用于将单词映射到连续的向量空间中。这种向量表示捕捉了单词之间的语义关系,使得相似含义的单词在向量空间中更加接近。Word2Vec有两种主要训练算法:CBOW(Continuous Bag of Words)和Skip-Gram。它在自然语言处理任务中广泛应用,如文本分类、情感分析、推荐系统等。 Word2Vec通过学习上下文信息和词语共现关系,提高文本数据的表征能力。
四、Python文件
使用jieba库和Word2Vec模型实现词嵌入的python代码为:
1、导入必要的库和模块
import jieba
import numpy as np
from gensim.models import Word2Vec
import string2、准备中文数据集
# 定义要跳过的停用词和标点符号
stopwords = set(["的""地""得""了"])
punctuation = set(string.punctuation) # 包括所有标点符号
# 打开原始文本文件和新文本文件
with open('chinese_corpus.txt', 'r', encoding='utf-8') as file, open('chinese_corpus1.txt', 'w', encoding='utf-8') as new_file:
for line in file:
# 分词并移除停用词和标点符号
words = jieba.cut(line)
filtered_words = [word for word in words if word not in stopwords and word not in punctuation]
# 将处理后的文本写入新文件
new_line = ' '.join(filtered_words)
new_file.write(new_line + '\n')3、使用jieba库对文本进行分词
# 重新打开已处理的文本文件,构建tokenized_corpus
with open('chinese_corpus1.txt', 'r', encoding='utf-8') as file:
tokenized_corpus = [list(jieba.cut(line)) for line in file]4、构建词嵌入模型。在这里使用Word2Vec
# 设置Word2Vec模型的参数
embedding_size = 100 # 词向量的维度
window_size = 5 # 上下文窗口的大小
min_word_count = 1 # 最小词频
sg = 0 # 使用CBOW模型
# 构建Word2Vec模型
model = Word2Vec(sentences=tokenized_corpus, vector_size=embedding_size, window=window_size, min_count=min_word_count, sg=sg)5、训练词嵌入模型
model.train(tokenized_corpus, total_examples=len(tokenized_corpus), epochs=10)6、现在已经训练好了词嵌入模型,可以使用它来获取词向量,并输出获取向量后请写出其获取与查找到的东西
# 获取某个词的词向量
word_vector = model.wv['网球']
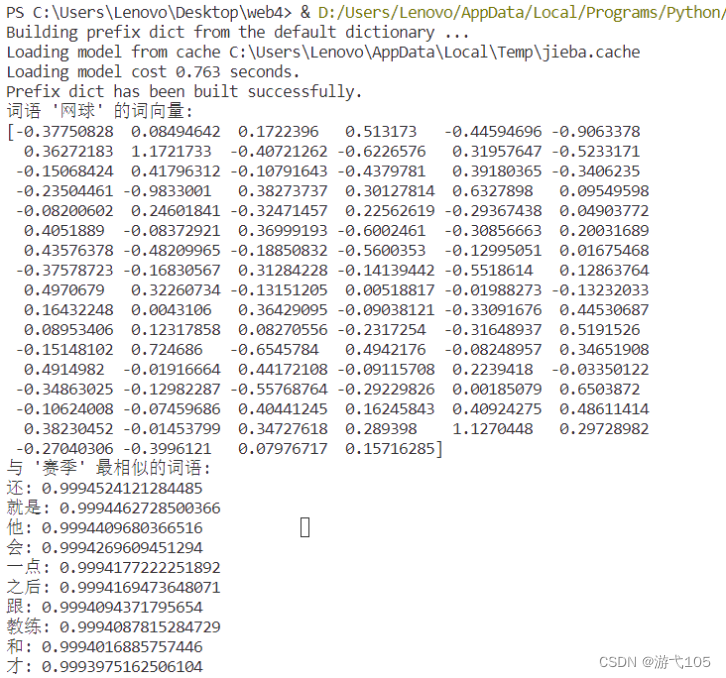
print("词语 '网球' 的词向量:")
print(word_vector)
# 查找与某个词语最相似的词语
similar_words = model.wv.most_similar('赛季')
print("与 '赛季' 最相似的词语:")
for word, score in similar_words:
print(f"{word}: {score}")五、结果
输出的词语 '网球' 的词向量及与 '赛季' 最相似的词语,结果如下:

















 5992
5992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









