







序言
Go 语言迅速席卷了整个互联网后端开发领域,其社区里不断涌现出类似vitess、Docker、etcd、Consul 等重量级的开源项目。
Go 是一门开源的编程语言,目的在于降低构建简单、可靠、高效软件的门槛。尽管这门语言借鉴了很多其他语言的思想,但是凭借自身统一和自然的表达,Go 程序在本质上完全不同于用其他语言编写的程序。Go 平衡了底层系统语言的能力,以及在现代语言中所见到的高级特性。
你可以依靠Go 语言来构建一个非常快捷、高性能且有足够控制力的编程环境。使用Go 语言,可以写得更少,做得更多。
Go语言介绍
Go 语言对传统的面向对象开发进行了重新思考,并且提供了更高效的复用代码的手段。Go 语言还让用户能更高效地利用昂贵
服务器上的所有核心,而且它编译大型项目的速度也很快。
用Go 解决现代编程难题
作为一门语言,Go不仅定义了能做什么,还定义了不能做什么。Go 语言的语法简洁到只有几个关键字,便于记忆。Go 语言的编译器速度非常快,有时甚至会让人感觉不到在编译。所以,Go 开发者能显著减少等待项目构建的时间。因为Go 语言内置并发机制,所以不用被迫使用特定的线程库,就能让软件扩展,使用更多的资源。Go 语言的类型系统简单且高效,不需要为面向对象开发付出额外的心智,让开发者能专注于代码复用。Go 语言还自带垃圾回收器,不需要用户自己管理内存。
开发速度
Go 语言使用了更加智能的编译器,并简化了解决依赖的算法,最终提供了更快的编译速度。编译Go 程序时,编译器只会关注那些直接被引用的库,而不是像Java、C 和C++那样,要遍历依赖链中所有依赖的库。因此,很多Go 程序可以在1 秒内编译完。在现代硬件上,编译整个Go语言的源码树只需要20 秒。
并发
Go 语言对并发的支持是这门语言最重要的特性之一。goroutine 很像线程,但是它占用的内存远少于线程,使用它需要的代码更少。通道(channel)是一种内置的数据结构,可以让用户在不同的goroutine 之间同步发送具有类型的消息。这让编程模型更倾向于在goroutine之间发送消息,而不是让多个goroutine 争夺同一个数据的使用权。
1、goroutine
goroutine 是可以与其他goroutine 并行执行的函数,同时也会与主程序(程序的入口)并行执行。在其他编程语言中,你需要用线程来完成同样的事情,而在Go 语言中会使用同一个线程来执行多个goroutine。
在Go 语言中,net/http 库直接使用了内置的goroutine。每个接收到的请求都自动在其自己的goroutine 里处理。goroutine 使用的内存
比线程更少,Go 语言运行时会自动在配置的一组逻辑处理器上调度执行goroutine。每个逻辑处理器绑定到一个操作系统线程上。这让用户的应用程序执行效率更高,而开发工作量显著减少。

2、通道
通道是一种数据结构,可以让**goroutine 之间进行安全的数据通信**。通道可以帮用户避免其他语言里常见的共享内存访问的问题。
通道提供了一种新模式,从而保证并发修改时的数据安全。通道这一模式保证同一时刻只会有一个goroutine 修改数据。通道用于在几个运行的goroutine 之间发送数据。

需要强调的是,通道并不提供跨goroutine 的数据访问保护机制。如果通过通道传输数据的一份副本,那么每个goroutine 都持有一份副本,各自对自己的副本做修改是安全的。当传输的是指向数据的指针时,如果读和写是由不同的goroutine 完成的,每个goroutine 依旧需要额外的同步动作。
Go 语言的类型系统
Go 语言提供了灵活的、无继承的类型系统,无需降低运行性能就能最大程度上复用代码。这个类型系统依然支持面向对象开发,但避免了传统面向对象的问题。
Go 开发者使用组合(composition)设计模式,只需简单地将一个类型嵌入到另一个类型,就能复用所有的功能。其他语言也能使用组合,但是不得不和继承绑在一起使用,结果使整个用法非常复杂,很难使用。在Go 语言中,一个类型由其他更微小的类型组合而成,避免了传统的基于继承的模型。
另外,Go 语言还具有独特的接口实现机制,允许用户对行为进行建模,而不是对类型进行建模。在Go 语言中,不需要声明某个类型实现了某个接口,编译器会判断一个类型的实例是否符合正在使用的接口。
1、类型简单
Go 语言不仅有类似int 和string 这样的内置类型,还支持用户定义的类型。
2、Go 接口对一组行为建模
不需要去声明这个实例实现某个接口,只需要实现这组行为就好。
内存管理
Go 语言拥有现代化的垃圾回收机制
Go Playground
Go Playground 允许在浏览器里编辑并运行Go 语言代码。在浏览器中打开http://play.golang.org。浏览器里展示的代码是可编辑的。
Go语言的类型系统
Go 语言是一种静态类型的编程语言。这意味着,编译器需要在编译时知晓程序里每个值的类型
用户定义的类型
Go 语言里声明用户定义的类型有两种方法。最常用的方法是使用关键字struct,它可以让用户创建一个结构类型。
// user 在程序里定义一个用户类型
type user struct {
name string
email string
ext int
privileged bool
}
// 声明user 类型的变量
var bill user
这个声明以关键字**type** 开始,之后是新类型的名字,最后是关键字**struct**。
当声明变量时,这个变量对应的值总是会被初始化。这个值要么用指定的值初始化,要么用零值(即变量类型的默认值)做初始化。对数值类型来说,零值是0;对字符串来说,零值是空字符串;对布尔类型,零值是false。任何时候,创建一个变量并初始化为其零值,习惯是使用关键字**var。这种用法是为了更明确地表示一个变量被设置为零值**。。如果变量被初始化为某个非零值,就配合结构字面量和短变量声明操作符(:=)来创建变量。
结构字面量可以对结构类型赋值采用两种形式。
- 在不同行声明每个字段的名字以及对应的值。字段名与值用冒号分隔,每一行以逗号结尾。这种形式对字段的声明顺序没有要求。
- 没有字段名,只声明对应的值,值的顺序很重要,必须要和结构声明中字段的顺序一致。每个值也可以分别占一行,不过习惯上这种形式会写在一行里,结尾不需要逗号。
// 声明user 类型的变量,并初始化所有字段
lisa := user {
name: "Lisa",
email: "lisa@email.com",
ext: 123,
privileged: true,
}
//或者
lisa := user {"Lisa", "lisa@email.com", 123, true}
当声明结构类型时,字段的类型并不限制在内置类型,也可以使用其他用户定义的类型。
// admin 需要一个user 类型作为管理者,并附加权限
type admin struct {
person user
level string
}
// 声明admin 类型的变量
fred := admin{
person: user{
name: "Lisa",
email: "lisa@email.com",
ext: 123,
privileged: true,
},
level: "super",
}
另一种声明用户定义的类型的方法是,基于一个已有的类型,将其作为新类型的类型说明。当需要一个可以用已有类型表示的新类型的时候,这种方法会非常好用。跟C的 typedef 类似。
type Duration int64
在
Duration类型的声明中,我们把int64类型叫作Duration的基础类型。不过,虽然int64是基础类型,Go 并不认为Duration 和int64是同一种类型。这两个类型是完全不同的有区别的类型。
方法
方法能给用户定义的类型添加新的行为。方法实际上也是函数,只是在声明时,在关键字func 和方法名之间增加了一个参数。关键字func 和函数名之间的参数被称作接收者,将函数与接收者的类型绑在一起。如果一个函数有接收者,这个函数就被称为方法。
Go 语言里有两种类型的接收者:值接收者和指针接收者。
如果使用值接收者声明方法,调用时会使用这个值的一个副本来执行。为了支持指针传给值接收者这种方法调用,Go 语言调整了指针的值,来符合方法接收者的定义。Go 编译器为了支持这种方法调用背后做的事情。指针 被 解引用 为 值,这样就符合了值接收者的要求。
//Go 在代码背后的执行动作
(*lisa).notify()
总结一下,对于变量是指针类型,值接收者使用值的副本来调用方法,而指针接受者使用实际值来调用方法。
使用一个值来调用 使用指针接收者声明 的方法。Go 语言再一次对值做了调整,使之符合函数的接收者,进行调用。Go 编译器为了支持这种方法调用在背后做的事情。首先引用 值变量 得到一个指针,这样这个指针就能够匹配方法的接收者类型,再进行调用。
//Go 在代码背后的执行动作
(&bill).changeEmail ("bill@newdomain.com")
Go语言既允许使用值,也允许使用指针来调用方法,不必严格符合接收者的类型。这个支持非常方便开发者编写程序。
这个参数类似于JVM中的第一个接受者参数this,还有其他语言差不多。
// notify 使用值接收者实现了一个方法
func (u user) notify() {
fmt.Printf("Sending User Email To %s<%s>\n",
u.name,
u.email)
}
// changeEmail 使用指针接收者实现了一个方法
func (u *user) changeEmail(email string) {
u.email = email
}
// user 类型的值可以用来调用 使用值接收者声明的方法
bill := user{"Bill", "bill@email.com"}
bill.notify()
// 指向user 类型值的指针也可以用来调用 使用值接收者声明的方法
lisa := &user{"Lisa", "lisa@email.com"}
lisa.notify()
// user 类型的值可以用来调用 使用指针接收者声明的方法
bill.changeEmail("bill@newdomain.com")
bill.notify()
// 指向user 类型值的指针可以用来调用 使用指针接收者声明的方法
lisa.changeEmail("lisa@newdomain.com")
lisa.notify()
类型的本质
在声明一个新类型之后,声明一个该类型的方法之前,需要先回答一个问题:这个类型的本质是什么。如果给这个类型增加或者删除某个值,是要创建一个新值,还是要更改当前的值?如果是要创建一个新值,该类型的方法就使用值接收者。如果是要修改当前值,就使用指针接收者。这个答案也会影响程序内部传递这个类型的值的方式:是按值做传递,还是按指针做传递。保持传递的一致性很重要。这个背后的原则是,不要只关注某个方法是如何处理这个值,而是要关注这个值的本质是什么。
内置类型
内置类型是由语言提供的一组类型。这些类型本质上是原始的类型。因此,当对这些值进行增加或者删除的时候,会创建一个新值。基于这个结论,当把这些类型的值传递给方法或者函数时,应该传递一个对应值的副本。
- 数值类型
- 字符串类型
- 和布尔类型
- String
引用类型
Go 语言里的引用类型有如下几个:
- 切片
- 映射
- 通道
- 接口
- 函数
当声明上述类型的变量时,创建的变量被称作标头(header)值。从技术细节上说,字符串也是一种引用类型。每个引用类型创建的标头值是包含一个指向底层数据结构的指针。每个引用类型还包含一组独特的字段,用于管理底层数据结构。因为标头值是为复制而设计的,所以永远不需要共享一个引用类型的值。标头值里包含一个指针,因此通过复制来传递一个引用类型的值的副本,本质上就是在共享底层数据结构。
结构类型
结构类型可以用来描述一组数据值,这组值的本质即可以是原始的,也可以是非原始的。
大多数情况下,结构类型的本质并不是原始的,而是非原始的。这种情况下,对这个类型的值做增加或者删除的操作应该更改值本身。当需要修改值本身时,在程序中其他地方,需要使用指针来共享这个值。
接口
多态是指代码可以根据类型的具体实现采取不同行为的能力。如果一个类型实现了某个接口,所有使用这个接口的地方,都可以支持这种类型的值。
实现
接口是用来定义行为的类型。这些被定义的行为不由接口直接实现,而是通过方法由用户定义的类型实现。如果用户定义的类型实现了某个接口类型声明的一组方法,那么这个用户定义的类型的值就可以赋给这个接口类型的值。这个赋值会把用户定义的类型的值存入接口类型的值。
对接口值方法的调用会执行接口值里存储的用户定义的类型的值对应的方法。因为任何用户定义的类型都可以实现任何接口,所以对接口值方法的调用自然就是一种多态。在这个关系里,用户定义的类型通常叫作实体类型,原因是如果离开内部存储的用户定义的类型的值的实现,接口值并没有具体的行为。
PS:接口值,类型的值 其实可以理解为面向对象中接口实例和类实例。
接口值是一个两个字长度的数据结构,第一个字包含一个指向内部表的指针。这个内部表叫作iTable,包含了所存储的值的类型信息。iTable 包含了已存储的值的类型信息以及与这个值相关联的一组方法。第二个字是一个指向所存储值的指针。将类型信息和指针组合在一起,就将这两个值组成了一种特殊的关系。
PS:
itable可以参考C++等面向对象语言的 虚函数表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tym9suBF-1612671282894)(E:\books\typora\images\image-20210121205333902.png)]
方法集
方法集定义了接口的接受规则。
// 这个示例程序展示Go 语言里如何使用接口
package main
import (
"fmt"
)
// notifier 是一个定义了通知类行为的接口
type notifier interface {
notify()
}
// user 在程序里定义一个用户类型
type user struct {
name string
email string
}
// notify 是使用指针接收者实现的方法
func (u *user) notify() {
fmt.Printf("Sending user email to %s<%s>\n",
u.name,
u.email)
}
func main() {
u := user{"Bill", "bill@email.com"}
sendNotification(u)
// ./listing36.go:32: 不能将u(类型是user)作为sendNotification 的参数类型notifier:
// user 类型并没有实现notifier(notify 方法使用 指针接收者 声明)
}
// sendNotification 接受一个实现了notifier 接口的值并发送通知
func sendNotification(n notifier) {
n.notify()
}
上面示例中,user 类型已经实现了接口 notifier,但是仍然不能编译通过。提示 user 类型的值(实例)没有实现 notifier接口。
要了解用指针接收者来实现接口时为什么user 类型的值无法实现该接口,需要先了解方法集。方法集定义了一组关联到给定类型的值或者指针的方法。定义方法时使用的接收者的类型决定了这个方法是关联到值,还是关联到指针,还是两个都关联。
Go 语言规范里定义的方法集的规则:
| Values | Method Receivers |
|---|---|
| T | (t T) |
| *T | (t T) ,(t *T) |
T 类型的值的方法集只包含值接收者声明的方法。而指向T 类型的指针的方法集既包含值接收者声明的方法,也包含指针接收者声明的方法。
从接收者类型的角度来看方法集:
| Method Receivers | Values |
|---|---|
| (t T) | T,*T |
| (t *T) | *T |
这个规则说,如果使用指针接收者来实现一个接口,那么只有指向那个类型的指针才能够实现对应的接口。如果使用值接收者来实现一个接口,那么那个类型的值和指针都能够实现对应的接口。
// 使用user 类型创建一个值,并发送通知
u := user{"Bill", "bill@email.com"}
// 传入地址,不再有错误
sendNotification( &u ) // 传入地址,不再有错误
多态
面向对象特性。略过。
嵌入类型
Go 语言允许用户扩展或者修改已有类型的行为。这个功能对代码复用很重要,在修改已有类型以符合新类型的时候也很重要。这个功能是通过嵌入类型(type embedding)完成的。嵌入类型是将已有的类型直接声明在新的结构类型里。被嵌入的类型被称为新的外部类型的内部类型。
通过嵌入类型,与内部类型相关的标识符会提升到外部类型上。这些被提升的标识符就像直接声明在外部类型里的标识符一样,也是外部类型的一部分。这样外部类型就组合了内部类型包含的所有属性,并且可以添加新的字段和方法。外部类型也可以通过声明与内部类型标识符同名的标识符来覆盖内部标识符的字段或者方法。这就是扩展或者修改已有类型的方法。
// 这个示例程序展示如何将一个类型嵌入另一个类型,以及内部类型和外部类型之间的关系
package main
import (
"fmt"
)
// user 在程序里定义一个用户类型
type user struct {
name string
email string
}
// notify 实现了一个可以通过user 类型值的指针 调用的方法
func (u *user) notify() {
fmt.Printf("Sending user email to %s<%s>\n",
u.name,
u.email)
}
// admin 代表一个拥有权限的管理员用户
type admin struct {
// 嵌入类型
user // 嵌入类型
level string
}
// main 是应用程序的入口
func main() {
// 创建一个admin 用户
ad := admin{
user: user{
name: "john smith",
email: "john@yahoo.com",
},
level: "super",
}
// 我们可以直接访问内部类型的方法
ad.user.notify() //类似于JAVA 组合,代理
/**
* 内部类型的方法也被提升到外部类型。直接作为外部类型的域。与其他语言的区别。
*/
ad.notify()
}
由于内部类型的提升,内部类型实现的接口会自动提升到外部类型。这意味着由于内部类型的实现,外部类型也同样实现了这个接口。
如果外部类型实现了某个方法(此方法内部类型也实现了),内部类型的实现就不会被提升。不过内部类型的值一直存在,因此还可以
通过直接访问内部类型的值,来调用没有被提升的内部类型实现的方法。
公开或未公开的标识符
Go 语言支持从包里公开或者隐藏标识符(java等使用public,private等关键字)。通过这个功能,让用户能按照自己的规则控制标识符的可见性。
当一个标识符的名字以小写字母开头时,这个标识符就是未公开的,即包外的代码不可见。如果一个标识符以大写字母开头,这个标识符就是公开的,即被包外的代码可见。(真是奇奇怪怪的东西)
将工厂函数命名为**New** 是Go 语言的一个习惯。这个New 函数做了些有意思的事情:它创建了一个未公开的类型的值,并将这个值返回给
调用者。(构造函数,单例模式相关)
// alertCounter 是一个未公开的类型
// 这个类型用于保存告警计数
type alertCounter int
// New 创建并返回一个未公开的
// alertCounter 类型的值
func New(value int) alertCounter {
return alertCounter(value)
}
// 使用counters 包公开的New 函数来创建
// 一个未公开的类型的变量
counter := counters.New(10)
New 函数返回的是一个未公开的 类型的值,而main 函数能够接受这个值并创建一个未公开的类型的变量。要让这个行为可行,需要两个理由。第一,公开或者未公开的标识符,不是一个值。第二,短变量声明操作符,有能力捕获引用的类型,并创建一个未公开的类型的变量。永远不能显式创建一个未公开的类型的变量,不过短变量声明操作符可以这么做。
对于嵌入类型,由于内部类型 是未公开的,代码无法直接通过结构字面量的方式初始化该内部类型。不过,即便内部类型是未公开的,内部类型里声明的字段依旧是公开的。既然内部类型的标识符提升到了外部类型,这些公开的字段也可以通过外部类型的字段的值来访问。
Go程序开发
程序架构
main 包
程序的主入口可以在main.go 文件里找到。
package main
import (
"log"
"os"
_ "github.com/goinaction/code/chapter2/sample/matchers"
"github.com/goinaction/code/chapter2/sample/search"
)
// init 在main 之前调用
func init() {
// 将日志输出到标准输出
log.SetOutput(os.Stdout)
}
// main 是整个程序的入口
func main() {
// 使用特定的项做搜索
search.Run("president")
}
语法:
使用
package定义包名使用
func定义main()函数
import导入其他代码,例如函数,接口,常量等。所有处于同一个文件夹里的代码文件,必须使用同一个包名。按照惯例,包和文件夹同名
为了让程序的可读性更强,Go 编译器不允许声明导入某个包却不使用。下划线让编译器接受这类导入,并且调用对应包内的所有代码文件里定义的
init函数。但是并不使用包里的标识符。
打包和工具链
包
所有 Go 语言的程序都会组织成若干组文件,每组文件被称为一个包。这样每个包的代码都可以作为很小的复用单元,被其他项目引用。
所有的.go 文件,除了空行和注释,都应该在第一行声明自己所属的包。每个包都在一个单独的目录里。不能把多个包放到同一个目录中,也不能把同一个包的文件分拆到多个不同目录中。这意味着,同一个目录下的所有.go 文件必须声明同一个包名。
包名惯例
给包命名的惯例是使用包所在目录的名字。这让用户在导入包的时候,就能清晰地知道包名。给包及其目录命名时,应该使用简洁、清晰且全小写的名字,这有利于开发时频繁输入包名。
记住,并不需要所有包的名字都与别的包不同,因为导入包时是使用全路径的,所以可以区分同名的不同包。一般情况下,包被导入后会使用包名作为默认的名字,不过导入后的名字可以修改。这个特性在需要导入不同目录的同名包时很有用。
main 包
在Go 语言里,命名为main 的包具有特殊的含义。Go 语言的编译程序会试图把这种名字的包编译为二进制可执行文件。所有用Go 语言编译的可执行程序都必须有一个名叫main 的包。
当编译器发现某个包的名字为main 时,它一定也会发现名为main()的函数,否则不会创建可执行文件。main()函数是程序的入口,所以,如果没有这个函数,程序就没有办法开始执行。
程序编译时,会使用声明main 包的代码所在的目录的目录名作为二进制可执行文件的文件名。
main包是在其他目录中,没有目录的名字叫main
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
获取包的文档:可以访问http://golang.org/pkg/fmt/或者在终端输入godoc fmt 来了解更多关于fmt 包的细节。
导入
import 语句告诉编译器到磁盘的哪里去找想要导入的包。导入包需要使用关键字 import,它会告诉编译器你想引用该位置的包内的代码。如果需要导入多个包,习惯上是将import 语句包装在一个导入块中。
import (
"fmt"
"strings"
)
编译器会使用Go 环境变量设置的路径,通过引入的相对路径来查找磁盘上的包。标准库中的包会在安装Go 的位置找到。Go 开发者创建的包会在GOPATH 环境变量指定的目录里查找。GOPATH 指定的这些目录就是开发者的个人工作空间。
查找顺序:
- 标准库(Go安装路径)
- 代码所在位置
GOPATH
一旦编译器找到一个满足 import 语句的包,就停止进一步查找。
远程导入
Go 工具链会使用导入路径确定需要获取的代码在网络的什么地方。
import "github.com/spf13/viper"
如果路径包含URL,可以使用Go 工具链从DVCS 获取包,并把包的源代码保存在GOPATH 指向的路径中与URL 匹配的目录里。这个获取过程
使用go get 命令完成。go get 将获取任意指定的URL 的包,或者一个已经导入的包所依赖的其他包。由于go get 的这种递归特性,这个命令会扫描某个包的源码树,获取能找到的所有依赖包。
命名导入
如果要导入的多个包具有相同的名字,重名的包可以通过命名导入来导入。命名导入是指,在import 语句给出的包路径的左侧定义一个名字,将导入的包命名为新名字。
package main
import (
"fmt"
myfmt "mylib/fmt" //myfmt 重命名
)
有时,用户可能需要导入一个包,但是不需要引用这个包的标识符。在这种情况,可以使用空白标识符_来重命名这个导入。
空白标识符:下划线字符(
_)在Go 语言里称为空白标识符,有很多用法。这个标识符用来抛弃不想继续使用的值,如给导入的包赋予一个空名字,或者忽略函数返回的你不感兴趣的值。
函数 init
每个包可以包含任意多个init 函数,这些函数都会在程序执行开始的时候被调用。所有被编译器发现的**init 函数都会安排在main 函数之前执行**。init 函数用在设置包、初始化变量或者其他要在程序运行前优先完成的引导工作。
package main
import (
"database/sql"
_ "github.com/goinaction/code/chapter3/dbdriver/postgres" //使用空白标识符导入包,避免编译错误。
)
func main() {
//调用 sql 包提供的Open 方法。该方法能工作的关键在于postgres 驱动通过自己的 init 函数将自身注册到了sql 包。
sql.Open("postgres", "mydb")
}
使用Go 的工具
go
go vet
依赖管理
第三方依赖
gb
import语句可以驱动go get,但是import 本身并没有包含足够的信息来决定到底要获取包的哪个修改的版本。go get 无法定位待获取代码的问题,导致Go 工具在解决重复构建时,不得不使用复杂且难看的方法。
gb 的创建源于上述理解。gb 既不包装Go 工具链,也不使用GOPATH。gb 基于工程将Go 工具链工作空间的元信息做替换。这种依赖管理的方法不需要重写工程内代码的导入路径。而且导入路径依旧通过go get 和GOPATH 工作空间来管理。
gb 工具首先会在$PROJECT/src/目录中查找代码,如果找不到,会在$PROJECT/vender/src/目录里查找。与工程相关的整个源代码都会在同一个代码库里。自己写的代码在工程目录的src/目录中,第三方依赖代码在工程目录的vender/src 子目录中。这样,不需要配合重写导入路径也可以完成整个构建过程,同时可以把整个工程放到磁盘的任意位置。这些特点,让gb 成为社区里解决可重复构建的流行工具。
还需要提一点:gb 工程与Go 官方工具链(包括go get)并不兼容。因为gb 不需要设置GOPATH,而Go 工具链无法理解gb 工程的目录结构,所以无法用Go 工具链构建、测试或者获取代码。构建和测试gb 工程需要先进入$PROJECT 目录,并使用gb工具。
gb build all
数组、切片和映射
数组
数组是切片和映射的基础数据结构。
内部实现
在Go 语言里,数组是一个长度固定的数据类型,用于存储一段具有相同的类型的元素的连续块。数组存储的类型可以是内置类型,如整型或者字符串,也可以是某种结构类型。
声明和初始化
声明数组时需要指定内部存储的数据的类型,以及需要存储的元素的长度
var array [5]int
一旦声明,数组里存储的数据类型和数组长度就都不能改变了。如果需要存储更多的元素,就需要先创建一个更长的数组,再把原来数组里的值复制到新数组里。
在 Go 语言中声明变量时,总会使用对应类型的零值来对变量进行初始化。
一种快速创建数组并初始化的方式是使用数组字面量。数组字面量允许声明数组里元素的数量同时指定每个元素的值。
如果使用...替代数组的长度,Go 语言会根据初始化时数组元素的数量来确定该数组的长度
也可以只指定部分元素的初始值
array := [5]int{10, 20, 30, 40, 50}
array := [...]int{10, 20, 30, 40, 50} //
array := [5]int{1: 10, 2: 20} //指定1,2 下标的元素的值
使用数组
//通过[]操作符进行下标访问
array[2] = 35
//声明包含5 个元素的指向整数的数组,用整型指针初始化索引为0 和1 的数组元素
array := [5]*int{0: new(int), 1: new(int)}
// 为索引为0 和1 的元素赋值
*array[0] = 10
*array[1] = 20
在 Go 语言里,数组是一个值。这意味着数组可以用在赋值操作中。变量名代表整个数组,因此,同样类型的数组可以赋值给另一个数组。
// 声明第一个包含5 个元素的字符串数组
var array1 [5]string
// 声明第二个包含5 个元素的字符串数组
// 用颜色初始化数组
array2 := [5]string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 把array2 的值复制到array1, 注意这个操作符是 (=)
array1 = array2
复制之后,两个数组的值完全一样。 这点与java,c等完全不一样,不是仅赋值引用。

数组变量的类型包括数组长度和每个元素的类型。只有这两部分都相同的数组,才是类型相同的数组,才能互相赋值
复制数组指针,只会复制指针的值,而不会复制指针所指向的值。
// 声明第一个包含3 个元素的指向字符串的指针数组
var array1 [3]*string
// 声明第二个包含3 个元素的指向字符串的指针数组
// 使用字符串指针初始化这个数组
array2 := [3]*string{new(string), new(string), new(string)}
// 使用颜色为每个元素赋值
*array2[0] = "Red"
*array2[1] = "Blue"
*array2[2] = "Green"
// 将array2 复制给array1
array1 = array2
复制之后,两个数组指向同一组字符串

多维数组
类似JAVA,C等
var array [4][2]int
array := [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
array := [4][2]int{1: {20, 21}, 3: {40, 41}}
// 设置每个元素的整型值
array[0][0] = 10
array[0][1] = 20
array[1][0] = 30
//只要类型一致,就可以将多维数组互相赋值,
// 声明两个不同的二维整型数组
var array1 [2][2]int
var array2 [2][2]int
// 为每个元素赋值
array2[0][0] = 10
array2[0][1] = 20
array2[1][0] = 30
array2[1][1] = 40
// 将array2 的值复制给array1
array1 = array2
在函数间传递数组
根据内存和性能来看,在函数间传递数组是一个开销很大的操作。在函数之间传递变量时,总是以值的方式传递的。如果这个变量是一个数组,意味着整个数组,不管有多长,都会完整复制,并传递给函数。有一种更好且更有效的方法来处理这个操作。可以只传入指向数组的指针,这样只需要复制8 字节的数据而不是8 MB 的内存数据到栈上。(类似JAVA 引用,搞不好就出错,感觉好别扭)
切片
切片是一种数据结构,这种数据结构便于使用和管理数据集合。切片是围绕动态数组的概念构建的,可以按需自动增长和缩小。切片的动态增长是通过内置函数append 来实现的。这个函数可以快速且高效地增长切片。还可以通过对切片再次切片来缩小一个切片的大小。因为切片的底层内存也是在连续块中分配的,所以切片还能获得索引、迭代以及为垃圾回收优化的好处。
内部实现
切片是一个很小的对象,对底层数组进行了抽象,并提供相关的操作方法。切片有3 个字段的数据结构,这些数据结构包含Go 语言需要操作底层数组的元数据。这 3 个字段分别是指向底层数组的指针、切片访问的元素的个数(即长度)和切片允许增长到的元素个数(即容量)。
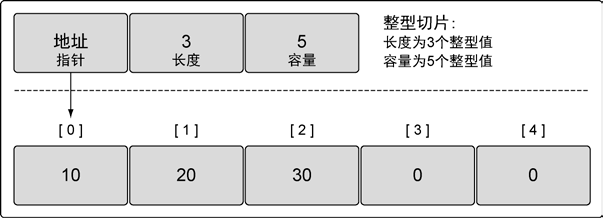
创建和初始化
Go 语言中有几种方法可以创建和初始化切片。是否能提前知道切片需要的容量通常会决定要如何创建切片。
make 和切片字面量
// 创建一个字符串切片,其长度和容量都是5 个元素。
//如果只指定长度,那么切片的容量和长度相等。
slice := make([]string, 5)
// 创建一个整型切片,其长度为3 个元素,容量为5 个元素
slice := make([]int, 3, 5)
分别指定长度和容量时,创建的切片,底层数组的长度是指定的容量,但是初始化后并不能访问所有的数组元素。
如果基于这个切片创建新的切片,新切片会和原有切片共享底层数组,也能通过后期操作来访问多余容量的元素。不允许创建容量小于长度的切片
// 创建字符串切片
// 其长度和容量都是5 个元素
slice := []string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 创建一个整型切片
// 其长度和容量都是3 个元素 。跟数组语法有什么区别?
slice := []int{10, 20, 30}
// 创建字符串切片 使用空字符串初始化第100 个元素
slice := []string{99: ""}
PS:如果在
[ ]运算符里指定了一个值,那么创建的就是数组而不是切片。只有不指定值的时候,才会创建切片
nil 和空切片
有时,程序可能需要声明一个值为nil 的切片(也称nil 切片)。只要在声明时不做任何初始化,就会创建一个nil 切片。
// 创建nil 整型切片
var slice []int
// 使用make 创建空的整型切片
slice := make([]int, 0)
// 使用切片字面量创建空的整型切片
slice := []int{}
在 Go 语言里,nil 切片是很常见的创建切片的方法。nil 切片可以用于很多标准库和内置函数。在需要描述一个不存在的切片时,nil 切片会很好用。空切片在底层数组包含0 个元素,也没有分配任何存储空间。想表示空集合时空切片很有用。不管是使用 nil 切片还是空切片,对其调用内置函数
append、len和cap的效果都是一样的。

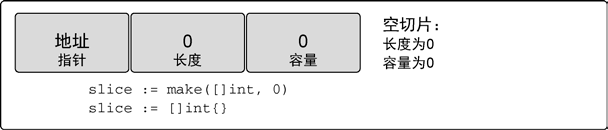
使用切片
赋值和切片
对切片里某个索引指向的元素赋值和对数组里某个索引指向的元素赋值的方法完全一样。使用**[ ]**操作符就可以改变某个元素的值。
// 创建一个整型切片
// 其容量和长度都是5 个元素
slice := []int{10, 20, 30, 40, 50}
// 改变索引为1 的元素的值
slice[1] = 25
// 创建一个新切片: 其长度为2 个元素,容量为4 个元素
newSlice := slice[1:3]
了两个切片,它们共享同一段底层数组,但通过不同的切片会看到底层数组的不同部分。如果一个切片修改了该底层数组的共享
部分,另一个切片也能感知到。

计算长度和容量:
对底层数组容量是k 的切片
slice[i:j]来说
长度: j - i j元素不包含在切片中。
容量: k - i k:原始切片的容量。
切片只能访问到其长度内的元素。试图访问超出其长度的元素将会导致语言运行时异常,与切片的容量相关联的元素只能用于增长切片。在使用这部分元素前,必须将其合并到切片的长度里。
切片增长
相对于数组而言,使用切片的一个好处是,可以按需增加切片的容量。Go 语言内置的append函数会处理增加长度时的所有操作细节。
要使用 append,需要一个被操作的切片和一个要追加的值。当append 调用返回时,会返回一个包含修改结果的新切片。函数append 总是会增加新切片的长度,而容量有可能会改变,也可能不会改变,这取决于被操作的切片的可用容量。
// 创建一个整型切片: 其长度和容量都是5 个元素
slice := []int{10, 20, 30, 40, 50}
// 创建一个新切片:其长度为2 个元素,容量为4 个元素
newSlice := slice[1:3]
// 使用原有的容量来分配一个新元素: 将新元素赋值为60
newSlice = append(newSlice, 60) //就增加一个元素。
如果切片的底层数组没有足够的可用容量,append 函数会**创建一个新的底层数组,将被引用的现有的值复制**到新数组里,再追加新的值,
// 创建一个整型切片 : 其长度和容量都是4 个元素
slice := []int{10, 20, 30, 40}
// 向切片追加一个新元素 : 将新元素赋值为50
newSlice := append(slice, 50)
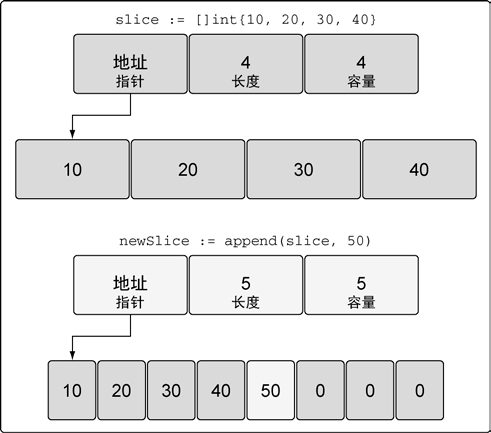
函数append 会智能地处理底层数组的容量增长。在切片的容量小于1000 个元素时,总是会成倍地增加容量。一旦元素个数超过1000,容量的增长因子会设为1.25,也就是会每次增加25%的容量。随着语言的演化,这种增长算法可能会有所改变。
创建切片时的3 个索引
在创建切片时,还可以使用之前我们没有提及的第三个索引选项。第三个索引可以用来控制新切片的容量。其目的并不是要增加容量,而是要限制容量。可以看到,允许限制新切片的容量为底层数组提供了一定的保护,可以更好地控制追加操作。
// 将第三个元素切片,并限制容量
// 其长度为1 个元素,容量为2 个元素。4表示下标4.
slice := source[2:3:4]
对于
slice[i:j:k]或[2:3:4]。K表示下标,不是容量。
长度: j – i 或3 - 2 = 1
容量: k – i 或4 - 2 = 2
内置函数append 也是一个可变参数的函数。这意味着可以在一次调用传递多个追加的值。如果使用...运算符,可以将一个切片的所有元素追加到另一个切片里,
// 创建两个切片,并分别用两个整数进行初始化
s1 := []int{1, 2}
s2 := []int{3, 4}
// 将两个切片追加在一起,并显示结果
fmt.Printf("%v\n", append(s1, s2...))
Output:
[1 2 3 4]
迭代切片
既然切片是一个集合,可以迭代其中的元素。Go 语言有个特殊的关键字range,它可以配合关键字for 来迭代切片里的元素。
当迭代切片时,关键字range 会返回两个值。第一个值是当前迭代到的索引位置,第二个值是该位置对应元素值的一份副本
// 创建一个整型切片
// 其长度和容量都是4 个元素
slice := []int{10, 20, 30, 40}
// 迭代每一个元素,并显示其值
for index, value := range slice {
fmt.Printf("Index: %d Value: %d\n", index, value)
}
Output:
Index: 0 Value: 10
Index: 1 Value: 20
Index: 2 Value: 30
Index: 3 Value: 40

需要强调的是,range 创建了每个元素的副本,而不是直接返回对该元素的引用,如果使用该值变量的地址作为指向每个元素的指针,就会造成错误。
因为迭代返回的变量是一个迭代过程中根据切片依次赋值的新变量,所以value 的地址总是相同的。要想获取每个元素的地址,可以使用切片变量和索引值。如果不需要索引值,可以使用占位字符来忽略这个值,
// 创建一个整型切片
// 其长度和容量都是4 个元素
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示其值
for _, value := range slice {
fmt.Printf("Value: %d\n", value)
}
Output:
Value: 10
Value: 20
Value: 30
Value: 40
关键字 range 总是会从切片头部开始迭代。如果想对迭代做更多的控制,依旧可以使用传统的for 循环,
// 从第三个元素开始迭代每个元素
for index := 2; index < len(slice); index++ {
fmt.Printf("Index: %d Value: %d\n", index, slice[index])
}
有两个特殊的内置函数
len和cap,可以用于处理数组、切片和通道。对于切片,函数len返回切片的长度,函数cap返回切片的容量。
多维切片
和数组一样,切片是一维的。不过,和之前对数组的讨论一样,可以组合多个切片形成多维切片。
// 创建一个整型切片的切片
slice := [][]int{{10}, {100, 200}}
在函数间传递切片
在函数间传递切片就是要在函数间以值的方式传递切片。由于切片的尺寸很小,在函数间复制和传递切片成本也很低。
由于与切片关联的数据包含在底层数组里,不属于切片本身,所以将切片复制到任意函数的时候,对底层数组大小都不会有影响。复制时只会复制切片本身,不会涉及底层数组。

映射
映射是一种数据结构,用于存储一系列无序的键值对。
参考JAVA的Map。
映射是一个集合,可以使用类似处理数组和切片的方式迭代映射中的元素。但映射是无序的集合,意味着没有办法预测键值对被返回的顺序。即便使用同样的顺序保存键值对,每次迭代映射的时候顺序也可能不一样。无序的原因是映射的实现使用了散列表,
映射的散列表包含一组桶。在存储、删除或者查找键值对的时候,所有操作都要先选择一个桶。把操作映射时指定的键传给映射的散列函数,就能选中对应的桶。这个散列函数的目的是生成一个索引,这个索引最终将键值对分布到所有可用的桶里。
映射使用两个数据结构来存储数据。第一个数据结构是一个数组,内部存储的是用于选择桶的散列键的高八位值。这个数组用于区分每个
键值对要存在哪个桶里。第二个数据结构是一个字节数组,用于存储键值对。该字节数组先依次存储了这个桶里所有的键,之后依次存储了这个桶里所有的值。实现这种键值对的存储方式目的在于减少每个桶所需的内存。

创建和初始化
Go 语言中有很多种方法可以创建并初始化映射,可以使用内置的make 函数,也可以使用映射字面量。
dict := make(map[string]int)
// 创建一个映射,键和值的类型都是string
// 使用两个键值对初始化映射
dict := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}
// 创建一个映射,使用字符串切片作为值
dict := map[int][]string{}
映射的键可以是任何值。这个值的类型可以是内置的类型,也可以是结构类型,只要这个值可以使用==运算符做比较。切片、函数以及包含切片的结构类型这些类型由于具有引用语义,不能作为映射的键,使用这些类型会造成编译错误,
使用映射
键值对赋值给映射,是通过指定适当类型的键并给这个键赋一个值来完成的,
// 创建一个空映射,用来存储颜色以及颜色对应的十六进制代码
colors := map[string]string{}
// 将Red 的代码加入到映射
colors["Red"] = "#da1337"
可以通过声明一个未初始化的映射来创建一个值为nil 的映射(称为nil 映射)。nil 映射不能用于存储键值对,否则,会产生一个语言运行时错误
// 通过声明映射创建一个nil 映射
var colors map[string]string //不带{}
// 将Red 的代码加入到映射
colors["Red"] = "#da1337"
Runtime Error:
panic: runtime error: assignment to entry in nil map
从映射取值时有两个选择。第一个选择是,可以同时获得值,以及一个表示这个键是否存在的标志,另一个选择是,只返回键对应的值,然后通过判断这个值是不是零值来确定键是否存在(这种方法只能用在映射存储的值都是非零值的情况)。
// 获取键Blue 对应的值,以及是否存在标志。
value, exists := colors["Blue"]
// 获取键Blue 对应的值
value := colors["Blue"]
在 Go 语言里,通过键来索引映射时,即便这个键不存在也总会返回一个值。在这种情况下,返回的是该值对应的类型的零值。
迭代映射里的所有值和迭代数组或切片一样,使用关键字range。但对映射来说,range 返回的不是索引和值,而是键值对。
// 创建一个映射,存储颜色以及颜色对应的十六进制代码
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
// 删除键为Coral 的键值对
delete(colors, "Coral")
在函数间传递映射
在函数间传递映射并不会制造出该映射的一个副本。实际上,当传递映射给一个函数,并对这个映射做了修改时,所有对这个映射的引用都会察觉到这个修改。
并发
Go 语言里的并发指的是能让某个函数独立于其他函数运行的能力。当一个函数创建为goroutine时,Go 会将其视为一个独立的工作单元。这个单元会被调度到可用的逻辑处理器上执行。Go 语言运行时的调度器是一个复杂的软件,能管理被创建的所有goroutine 并为其分配执行时间。这个调度器在操作系统之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine。调度器在任何给定的时间,都会全面控制哪个goroutine 要在哪个逻辑处理器上运行。
Go 语言的并发同步模型来自一个叫作通信顺序进程(Communicating Sequential Processes,CSP)的范型(paradigm)。CSP 是一种消息传递模型,通过在goroutine 之间传递数据来传递消息,而不是对数据进行加锁来实现同步访问。用于在goroutine 之间同步和传递数据的关键数据类型叫作通道(channel)。使用通道可以使编写并发程序更容易,也能够让并发程序出错更少。
操作系统会在物理处理器上调度线程来运行,而Go 语言的运行时会在逻辑处理器上调度goroutine来运行。每个逻辑处理器都分别绑定到单个操作系统线程。在1.5 版本中,可以看到操作系统线程、逻辑处理器和本地运行队列之间的关系。如果创建一个goroutine 并准备运行,这个goroutine 就会被放到调度器的全局运行队列中。之后,调度器就将这些队列中的goroutine 分配给一个逻辑处理器,并放到这个逻辑处理器对应的本地运行队列上,Go语言的运行时默认会为每个可用的物理处理器分配一个逻辑处理器。在1.5 版本之前的版本中,默认给整个应用程序只分配一个逻辑处理器。这些逻辑处理器会用于执行所有被创建的goroutine。即便只有一个逻辑处理器,Go也可以以神奇的效率和性能,并发调度无数个goroutine。

如果一个 goroutine 需要做一个网络I/O 调用,流程上会有些不一样。在这种情况下,goroutine会和逻辑处理器分离,并移到集成了网络轮询器的运行时。一旦该轮询器指示某个网络读或者写操作已经就绪,对应的goroutine 就会重新分配到逻辑处理器上来完成操作。调度器对可以创建的逻辑处理器的数量没有限制,但语言运行时默认限制每个程序最多创建10 000 个线程。这个限制值可以通过调用runtime/debug 包的SetMaxThreads 方法来更改。如果程序试图使用更多的线程,就会崩溃。
如果希望让goroutine 并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器时,调度器会将goroutine 平等分配到每个逻辑处理器上。这会让goroutine 在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕Go 语言运行时使用多个线程,goroutine 依然会在同一个物理处理器上并发运行,达不到并行的效果。
goroutine
通过关键字go 创建goroutine来执行不同线程。
关键字 defer 会修改函数调用时机,在正在执行的函数返回时才真正调用defer 声明的函数。
func main() {
// 分配一个逻辑处理器给调度器使用
runtime.GOMAXPROCS(1)
// wg 用来等待程序完成
// 计数加 2,表示要等待两个goroutine
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Start Goroutines")
// 声明一个匿名函数,并创建一个goroutine
go func() {
// 在函数退出时调用Done 来通知main 函数工作已经完成
defer wg.Done()
// 显示字母表3 次
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
// 声明一个匿名函数,并创建一个goroutine
go func() {
// 在函数退出时调用Done 来通知main 函数工作已经完成
defer wg.Done()
// 显示字母表3 次
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
// 等待 goroutine 结束
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("\nTerminating Program")
}
竞争状态
如果两个或者多个goroutine 在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这个资源,就处于相互竞争的状态,这种情况被称作竞争状态(race candition)
锁住共享资源
Go 语言提供了传统的同步goroutine 的机制,就是对共享资源加锁。如果需要顺序访问一个整型变量或者一段代码,atomic 和sync 包里的函数提供了很好的解决方案。
原子函数
原子函数能够以很底层的加锁机制来同步访问整型变量和指针。
// incCounter 增加包里counter 变量的值
func incCounter(id int) {
// 在函数退出时调用Done 来通知main 函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
//*********************************************************************************
// 安全地对counter 加1
//*********************************************************************************
atomic.AddInt64(&counter, 1)
// 当前 goroutine 从线程退出,并放回到队列
runtime.Gosched()
}
}
互斥锁
另一种同步访问共享资源的方式是使用互斥锁(mutex)。互斥锁这个名字来自互斥(mutual exclusion)的概念。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个goroutine 可以执行这个临界区代码。
// incCounter 使用互斥锁来同步并保证安全访问,
// 增加包里counter 变量的值
func incCounter(id int) {
// 在函数退出时调用Done 来通知main 函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
//*********************************************************************************
// 同一时刻只允许一个goroutine 进入 这个临界区
mutex.Lock()
//******* 使用大括号只是为了让临界区看起来更清晰,并不是必需的。
{
// 捕获 counter 的值
value := counter
// 当前 goroutine 从线程退出,并放回到队列
runtime.Gosched()
// 增加本地 value 变量的值
value++
// 将该值保存回counter
counter = value
}
//*********************************************************************************
// 释放锁,允许其他正在等待的goroutine 进入临界区
mutex.Unlock()
}
}
通道
原子函数和互斥锁都能工作,但是依靠它们都不会让编写并发程序变得更简单,更不容易出错,或者更有趣。在Go 语言里,你不仅可以使用原子函数和互斥锁来保证对共享资源的安全访问以及消除竞争状态,还可以使用通道,通过发送和接收需要共享的资源,在goroutine 之间做同步。
当一个资源需要在goroutine 之间共享时,通道在goroutine 之间架起了一个管道,并提供了确保同步交换数据的机制。声明通道时,需要指定将要被共享的数据的类型。可以通过通道共享内置类型、命名类型、结构类型和引用类型的值或者指针。在 Go 语言中需要使用内置函数make 来创建一个通道。
通道定义:
var 通道变量 chan 通道类型
- 通道类型:通道内的数据类型。
- 通道变量:保存通道的变量。
chan 类型的空值是 nil,声明后需要配合 make 后才能使用。
// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓冲的字符串通道
buffered := make(chan string, 10)
向通道发送值或者指针需要用到<-操作符。为了让另一个goroutine 可以从该通道里接收到这个字符串,我们依旧使用<-操作符,但这次是一元运算符,
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher"
// 从通道接收一个字符串
value := <-buffered
通道是否带有缓冲,其行为会有一些不同。
无缓冲的通道
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送goroutine 和接收goroutine 同时准备好,才能完成发送和接收操作。如果两个goroutine没有同时准备好,通道会导致先执行发送或接收操作的goroutine 阻塞等待。这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
PS:类似 JAVA
SyncronizedBlockingQueue。
有缓冲的通道
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
PS:类似
java阻塞队列。
并发模式
runner
runner 包用于展示如何使用通道来监视程序的执行时间,如果程序运行时间太长,也可以用runner 包来终止程序。当开发需要调度后台处理任务的程序的时候,这种模式会很有用。这个程序可能会作为cron 作业执行,或者在基于定时任务的云环境(如iron.io)里执行。
pool
pool包用于展示如何使用有缓冲的通道实现资源池,来管理可以在任意数量的goroutine之间共享及独立使用的资源。这种模式在需要共享一组静态资源的情况(如共享数据库连接或者内存缓冲区)下非常有用。如果goroutine需要从池里得到这些资源中的一个,它可以从池里申请,使用完后归还到资源池里。
本书是以Go 1.5 版本为基础写作而成的。在Go 1.6 及之后的版本中,标准库里自带了资源池的实现(
sync.Pool)。推荐使用
work
work 包使用无缓冲的通道来创建一个goroutine 池,这些goroutine 执行并控制一组工作,让其并发执行。在这种情况下,使用无缓冲的通道要比随意指定一个缓冲区大小的有缓冲的通道好,因为这个情况下既不需要一个工作队列,也不需要一组goroutine 配合执行。无缓冲的通道保证两个goroutine 之间的数据交换。这种使用无缓冲的通道的方法允许使用者知道什么时候goroutine 池正在执行工作,而且如果池里的所有goroutine 都忙,无法接受新的工作的时候,也能及时通过通道来通知调用者。使用无缓冲的通道不会有工作在队列里丢失或者卡住,所有工作都会被处理。
反射
Go程序在运行期使用reflect包访问程序的反射信息。
Go 程序的反射系统无法获取到一个可执行文件空间中或者是一个包中的所有类型信息,需要配合使用标准库中对应的词法、语法解析器和抽象语法树(AST)对源码进行扫描后获得这些信息。
reflect 包
Go语言中的反射是由 reflect 包提供支持的,它定义了两个重要的类型 Type 和 Value 任意接口值在反射中都可以理解为由 reflect.Type 和 reflect.Value 两部分组成,并且 reflect 包提供了 reflect.TypeOf 和 reflect.ValueOf 两个函数来获取任意对象的 Value 和 Type。
反射的类型对象(reflect.Type)
在Go语言程序中,使用 reflect.TypeOf() 函数可以获得任意值的类型对象(reflect.Type),程序通过类型对象可以访问任意值的类型信息。
var a int
typeOfA := reflect.TypeOf(a)
fmt.Println(typeOfA.Name(), typeOfA.Kind())
反射的类型(Type)与种类(Kind)
Go语言程序中的类型(Type)指的是系统原生数据类型,如 int、string、bool、float32 等类型,以及使用 type 关键字定义的类型,这些类型的名称就是其类型本身的名称。例如使用 type A struct{} 定义结构体时,A 就是 struct{} 的类型。
type Kind uint
const (
Invalid Kind = iota // 非法类型
Bool // 布尔型
Int // 有符号整型
... ...
Array // 数组
Chan // 通道
Func // 函数
Interface // 接口
Map // 映射
Ptr // 指针
Slice // 切片
String // 字符串
Struct // 结构体
UnsafePointer // 底层指针
)
Map、Slice、Chan 属于引用类型,使用起来类似于指针,但是在种类常量定义中仍然属于独立的种类,不属于 Ptr。type A struct{} 定义的结构体属于 Struct 种类,*A 属于 Ptr。
reflect.Type 中的 Name() 方法,返回表示类型名称的字符串
指针与指针指向的元素
Go语言程序中对指针获取反射对象时,可以通过 reflect.Elem() 方法获取这个指针指向的元素类型,这个获取过程被称为取元素,等效于对指针类型变量做了一个*操作.
使用反射获取结构体的成员类型
任意值通过 reflect.TypeOf() 获得反射对象信息后,如果它的类型是结构体,可以通过反射值对象 reflect.Type 的 NumField() 和 Field() 方法获得结构体成员的详细信息。
与成员获取相关的 reflect.Type 的方法如下表所示。
| 方法 | 说明 |
|---|---|
| Field(i int) StructField | 根据索引返回索引对应的结构体字段的信息,当值不是结构体或索引超界时发生宕机 |
| NumField() int | 返回结构体成员字段数量,当类型不是结构体或索引超界时发生宕机 |
| FieldByName(name string) (StructField, bool) | 根据给定字符串返回字符串对应的结构体字段的信息,没有找到时 bool 返回 false,当类型不是结构体或索引超界时发生宕机 |
| FieldByIndex(index []int) StructField | 多层成员访问时,根据 []int 提供的每个结构体的字段索引,返回字段的信息,没有找到时返回零值。当类型不是结构体或索引超界时发生宕机 |
| FieldByNameFunc(match func(string) bool) (StructField,bool) | 根据匹配函数匹配需要的字段,当值不是结构体或索引超界时发生宕机 |
- 结构体字段类型
reflect.Type 的 Field() 方法返回 StructField 结构,这个结构描述结构体的成员信息,通过这个信息可以获取成员与结构体的关系,如偏移、索引、是否为匿名字段、结构体标签(StructTag)等,而且还可以通过 StructField 的 Type 字段进一步获取结构体成员的类型信息。
type StructField struct {
Name string // 字段名
PkgPath string // 字段路径
Type Type // 字段反射类型对象
Tag StructTag // 字段的结构体标签
Offset uintptr // 字段在结构体中的相对偏移
Index []int // Type.FieldByIndex中的返回的索引值
Anonymous bool // 是否为匿名字段
}
结构体标签(Struct Tag)
通过 reflect.Type 获取结构体成员信息 reflect.StructField 结构中的 Tag 被称为结构体标签(StructTag)。结构体标签是对结构体字段的额外信息标签。
JSON、BSON 等格式进行序列化及对象关系映射(Object Relational Mapping,简称 ORM)系统都会用到结构体标签,这些系统使用标签设定字段在处理时应该具备的特殊属性和可能发生的行为。这些信息都是静态的,无须实例化结构体,可以通过反射获取到。
inject库
略
标准库
文档与源代码
标准库里包含众多的包,不可能在一章内把这些包都讲一遍。目前,标准库里总共有超过100 个包,这些包被分到38 个类别里。不管用什么方式安装Go,标准库的源代码都会安装在**$GOROOT/src/pkg** 文件夹中。这些预编译后的文件,称作归档文件(archive file),可以在$GOROOT/pkg 文件夹中找到已经安装的各目标平台和操作系统的归档文件。(扩展名是.a 的文件,这些就是归档文件)
参见http://golang.org/pkg/
archive bufio bytes compress container crypto database
debug encoding errors expvar flag fmt go
hash html image index io log math
mime net os path reflect regexp runtime
sort strconv strings sync syscall testing text
time unicode unsafe
记录日志
log 包
定制的日志记录器
要想创建一个定制的日志记录器,需要创建一个Logger 类型值。可以给每个日志记录器配置一个单独的目的地,并独立设置其前缀和标志。
编码/解码
解码JSON
编码JSON
输入和输出
Writer 和Reader 接口
io 包是围绕着实现了io.Writer 和io.Reader 接口类型的值而构建的。由于io.Writer和io.Reader 提供了足够的抽象,这些io 包里的函数和方法并不知道数据的类型,也不知道这些数据在物理上是如何读和写的。
测试和性能
单元测试
在 Go 语言里有几种方法写单元测试。基础测试(basic test)只使用一组参数和结果来测试一段代码。表组测试(table test)也会测试一段代码,但是会使用多组参数和结果进行测试。
基础单元测试
Go 语言的测试工具只会认为以_test.go 结尾的文件是测试文件。如果没有遵从这个约定,在包里运行go test 的时候就可能会报告没有测试文件。一旦测试工具找到了测试文件,就会查找里面的测试函数并执行。
一个测试函数必须是公开的函数,并且以Test 单词开头。不但函数名字要以Test 开头,而且函数的签名必须接收一个指向testing.T 类型的指针,并且不返回任何值。如果没有遵守这些约定,测试框架就不会认为这个函数是一个测试函数,也不会让测试工具去执行它。
指向testing.T类型的指针很重要。这个指针提供的机制可以报告每个测试的输出和状态。测试的输出格式没有标准要求。
表组测试
如果测试可以接受一组不同的输入并产生不同的输出的代码,那么应该使用表组测试的方法进行测试。表组测试除了会有一组不同的输入值和期望结果之外,其余部分都很像基础单元测试。测试会依次迭代不同的值,来运行要测试的代码。每次迭代的时候,都会检测返回的结果。这便于在一个函数里测试不同的输入值和条件。
模仿调用
标准库包含一个名为httptest 的包,它让开发人员可以模仿基于HTTP 的网络调用。模仿(mocking)是一个很常用的技术手段,用来在运行测试时模拟访问不可用的资源。包httptest 可以让你能够模仿互联网资源的请求和响应。
测试服务端点
服务端点(endpoint)是指与服务宿主信息无关,用来分辨某个服务的地址,一般是不包含宿主的一个路径。如果在构造网络API,你会希望直接测试自己的服务的所有服务端点,而不用启动整个网络服务。包httptest 正好提供了做到这一点的机制。
附录
数据类型
整型
整型数据分为两类,有符号和无符号两种类型
有符号: int, int8, int16, int32, int64
无符号: uint, uint8, uint16, uint32, uint64, byte 不同位数的整型区别在于能保存整型数字范围的大小;
字符
Golang中没有专门的字符类型,如果要存储单个字符(字母),一般使用byte来保存。
字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的,也就是说对于传统的字符串是由字符组成的,而Go的字符串不同,它是由字节组成的。
- 字符只能被单引号包裹,不能用双引号,双引号包裹的是字符串
- 当我们直接输出type值时,就是输出了对应字符的ASCII码值
- 当我们希望输出对应字符,需要使用格式化输出
- Go语言的字符使用
UTF-8编码,英文字母占一个字符,汉字占三个字符 - 在Go中,字符的本质是一个整数,直接输出时,是该字符对应的
UTF-8编码的码值。 - 可以直接给某个变量赋一个数字,然后按格式化输出时%c,会输出该数字对应的
unicode字符 - 字符类型是可以运算的,相当于一个整数,因为它们都有对应的
unicode码
布尔型
布尔类型也叫做bool类型,bool类型数据只允许取值true或false。bool类型占1个字节。
字符串
字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8编码标识Unicode文本。
-
字符串一旦赋值了,就不能修改了:在Go中字符串是不可变的。
-
字符串的两种标识形式
-
双引号,会识别转义字符
var str = "abc\nabc" //输出时会换行 -
反引号,以字符串的原生形式输出,包括换行和特殊字符,可以实现防止攻击、输出源代码等效果
var str string = `abc\nabc` //输出时原样输出,不会转义
-
-
字符串拼接方式"+"
var str string = "hello " + "world" str += "!" -
当一行字符串太长时,需要使用到多行字符串,可以使用如下处理
//正确写法 str := "hello" + " world!" fmt.Println(str) //错误写法 str := "hello " + "world!" fmt.Println(str)
指针
- 基本数据类型,变量存的就是值,也叫值类型
- 获取变量的地址,用**
&** - 指针类型,指针变量存的是一个地址,这个地址指向的空间存的才是值,比如:var ptr
*int =&num - 获取指针类型所指向的值,比如,var ptr *int,使用
*ptr获取ptr指向的值
指针细节说明:
- 值类型,都有对应的指针类型,形式为**
*数据类型**,比如int对应的指针就是*int,float64对应的指针类型就是*float64,依此类推。 - 值类型包括:基本数据类型、数组和结构体
struct
值类型与引用类型
值类型和引用类型使用特点:
值类型:变量直接存储值,内存通常在栈中分配
引用类型:变量存储的是一个地址,这个地址对应的空间才真正存储数据(值),内存通常在堆上分配,当没有任何变量应用这个地址时,该地址对应的数据空间就成为一个垃圾,由GC来回收。
Golang中值类型和引用类型的区分
- 值类型:基本数据类型(int系列、float系列、
bool、string)、数组和结构体 - 引用类型:指针、slice切片、map、管道
chan、interface等都是引用类型
基本数据类型默认值
在Golang中,数据类型都有一个默认值,当程序员没有赋值时,就会保留默认值,在Golang中,默认值也叫做零值。
基本数据类型默认值如下:
| 数据类型 | 默认值 |
|---|---|
| 整型 | 0 |
| 浮点型 | 0 |
| 字符串 | “” |
| 布尔类型 | false |
基本数据类型相互转换
Golang和Java/C不同,Golang在不同类型的变量之间赋值时需要显式转换。也就是Golang中数据类型不能自动转换。
基本语法:
//var_type:就是数据类型,比如int32, int64, float32等等
//var_name:就是需要转换的变量
var_type(var_name)
注意事项
- Go中,数据类型的转换可以是从表示范围小–>表示范围大,也可以 范围大—>范围小
- 被转换的是变量存储的数据(即值),变量本身的数据类型并没有变化!
- 在转换中,比如将
int64转成int8,编译时不会报错,只是转换的结果是按溢出处理,和我们希望的结果不一样。- 数据的转换必须显式转换,不能自动转换
- 转换不会报错,如果出错,可能是弄成默认值。尤其注意!!!
数据类型
| 类型 | 描述 |
|---|---|
uint | 32位或64位 |
uint8 | 无符号 8 位整型 (0 到 255) |
uint16 | 无符号 16 位整型 (0 到 65535) |
uint32 | 无符号 32 位整型 (0 到 4294967295) |
uint64 | 无符号 64 位整型 (0 到 18446744073709551615) |
| int | 32位或64位 |
int8 | 有符号 8 位整型 (-128 到 127) |
int16 | 有符号 16 位整型 (-32768 到 32767) |
int32 | 有符号 32 位整型 (-2147483648 到 2147483647) |
int64 | 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
| byte | 类似 uint8 |
| rune | 类似 int32,表示一个unicode码 。如果需要使用到 4 字节,则使用\u前缀,如果需要使用到 8 个字节,则使用\U前缀。 |
uintptr | 无符号整型,用于存放一个指针是一种无符号的整数类型,没有指定具体的bit大小但是足以容纳指针。 uintptr类型只有在底层编程是才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方。 |
float32 | IEEE-754 32位浮点型数 |
float64 | IEEE-754 64位浮点型数 |
complex64 | 32 位实数和虚数 |
complex128 | 64 位实数和虚数 |
数据类型转换
由于Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明:
valueOfTypeB = typeB(valueOfTypeA)
//
a := 5.0
b := int(a)
只有相同底层类型的变量之间可以进行相互转换(如将 int16 类型转换成 int32 类型),不同底层类型的变量相互转换时会引发编译错误(如将 bool 类型转换为 int 类型)。
语法
变量声明
声明变量的一般形式是使用 var 关键字:
var 变量名 变量类型
//批量格式
var (
a int
b string
c []float32
d func() bool
e struct {
x int
}
)
//简短格式
名字 := 表达式
需要注意的是,简短模式(short variable declaration)有以下限制:
- 定义变量,同时显式初始化。
- 不能提供数据类型。
- 只能用在函数内部。
变量初始化
//标准格式
var 变量名 类型 = 表达式
//编译器推导类型的格式
var hp = 100
//短变量声明并初始化
hp := 100
注意:由于使用了
:=,而不是赋值的=,因此推导声明写法的左值变量必须是没有定义过的变量。若定义过,将会发生编译错误。
多个变量同时赋值
多重赋值时,变量的左值和右值按从左到右的顺序赋值。
var a int = 100
var b int = 200
b, a = a, b
fmt.Println(a, b)
匿名变量(没有名字的变量)
匿名变量的特点是一个下画线“”,“”本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。使用匿名变量时,只需要在变量声明的地方使用下画线替换即可。
a, _ := GetData()
变量的作用域
局部变量:作用域只在函数体内,函数的参数和返回值变量都属于局部变量。
全局变量:只需要在一个源文件中定义,就可以在所有源文件中使用。全局变量声明必须以 var 关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
形式参数(简称形参):形式参数只在函数调用时才会生效,函数调用结束后就会被销毁,在函数未被调用时,函数的形参并不占用实际的存储单元,也没有实际值。
指针
与 Java 和 .NET 等编程语言不同,Go语言为程序员提供了控制数据结构指针的能力,但是,并不能进行指针运算。Go语言允许你控制特定集合的数据结构、分配的数量以及内存访问模式。
指针(pointer)在Go语言中可以被拆分为两个核心概念:
- 类型指针,允许对这个指针类型的数据进行修改,传递数据可以直接使用指针,而无须拷贝数据,类型指针不能进行偏移和运算。
- 切片,由指向起始元素的原始指针、元素数量和容量组成。
受益于这样的约束和拆分,Go语言的指针类型变量即拥有指针高效访问的特点,又不会发生指针偏移,从而避免了非法修改关键性数据的问题。同时,垃圾回收也比较容易对不会发生偏移的指针进行检索和回收。
要明白指针,需要知道几个概念:指针地址、指针类型和指针取值
指针地址和指针类型
一个指针变量可以指向任何一个值的内存地址,每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用在变量名前面添加**&操作符**(前缀)来获取变量的内存地址(取地址操作),格式如下:
ptr := &v // v 的类型为 T
其中 v 代表被取地址的变量,变量 v 的地址使用变量 ptr 进行接收,ptr 的类型为***T,称做 T 的指针类型**,*代表指针。
从指针获取指针指向的值
当使用&操作符对普通变量进行取地址操作并得到变量的指针后,可以对指针使用*操作符,也就是指针取值
// 对指针进行取值操作
value := *ptr
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址操作使用
&操作符,可以获得这个变量的指针变量。 - 指针变量的值是指针地址。
- 对指针变量进行取值操作使用
*操作符,可以获得指针变量指向的原变量的值。
使用指针修改值
通过指针不仅可以取值,也可以修改值。
创建指针的另一种方法——new() 函数
Go语言还提供了另外一种方法来创建指针变量,格式如下:
new(类型)
str := new(string)*str = "Go语言教程"fmt.Println(*str)
常量
常量的定义格式和变量的声明语法类似:const name [type] = value,例如:
iota 常量生成器
常量声明可以使用 iota 常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。在一个 const 声明语句中,在第一个声明的常量所在的行,iota 将会被置为 0,然后在每一个有常量声明的行加一。
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
//可跳过的值
type AudioOutput int
const (
OutMute AudioOutput = iota // 0
OutMono // 1
OutStereo // 2
_ //跳过了
_
OutSurround // 5
)
//位掩码表达式
type Allergen int
const (
IgEggs Allergen = 1 << iota // 1 << 0 which is 00000001
IgChocolate // 1 << 1 which is 00000010
IgNuts // 1 << 2 which is 00000100
IgStrawberries // 1 << 3 which is 00001000
IgShellfish // 1 << 4 which is 00010000
)
//定义数量级
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
//定义在一行的情况
const (
Apple, Banana = iota + 1, iota + 2 //iota 在下一行增长,而不是立即取得它的引用。
Cherimoya, Durian
Elderberry, Fig
)
// Apple: 1
// Banana: 2
// Cherimoya: 2
// Durian: 3
// Elderberry: 3
// Fig: 4
//中间插队。中间插队时,iota 会被覆盖掉 不再继续自增。但是用另一个 iota 接一下,又会继续自增
const(
a = iota
b = 5
c = iota
d = 6
e
f
)
//0 5 2 6 6 6
iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次。
每次 const 出现时,都会让 iota 初始化为0.
无类型常量
Go语言的常量有个不同寻常之处。虽然一个常量可以有任意一个确定的基础类型,但是许多常量并没有一个明确的基础类型。
编译器为这些没有明确的基础类型的数字常量提供比基础类型更高精度的算术运算,可以认为至少有 256bit 的运算精度。这里有六种未明确类型的常量类型,分别是无类型的布尔型、无类型的整数、无类型的字符、无类型的浮点数、无类型的复数、无类型的字符串。
通过延迟明确常量的具体类型,不仅可以提供更高的运算精度,而且可以直接用于更多的表达式而不需要显式的类型转换。
type关键字(类型别名)
在 Go 1.9 版本之前定义内建类型的代码是这样写的:
type byte uint8type rune int32
而在 Go 1.9 版本之后变为:
type byte = uint8type rune = int32
这个修改就是配合类型别名而进行的修改。
区分类型别名与类型定义
定义类型别名的写法为:
type TypeAlias = Type
类型定义
type TypeAlias Type
类型别名规定:TypeAlias 只是 Type 的别名,本质上 TypeAlias 与 Type 是同一个类型
非本地类型的别名不能定义方法
非本地指同一个包。
注释
单行://
多行:/* */
godoc 工具
godoc 工具会从 Go 程序和包文件中提取顶级声明的首行注释以及每个对象的相关注释,并生成相关文档,也可以作为一个提供在线文档浏览的 web 服务器。
关键字
| break | default | func | interface | select |
|---|---|---|---|---|
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
控制语句
if/else
if condition1 {
// do something
} else if condition2 {
// do something else
}else {
// catch-all or default
}
if ten > 10 {
fmt.Println(">10")
} else {
fmt.Println("<=10")
}
关键字 if 和 else 之后的左大括号
{必须和关键字在同一行,如果你使用了 else if 结构,则前段代码块的右大括号}必须和 else if 关键字在同一行,这两条规则都是被编译器强制规定的。在有些情况下,条件语句两侧的括号是可以被省略的。
if 还有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断。
if err := Connect(); err != nil { //特殊写法
fmt.Println(err)
return
}
switch
Go语言改进了 switch 的语法设计,case 与 case 之间是独立的代码块,不需要通过 break 语句跳出当前 case 代码块以避免执行到下一行。
var a = "hello"
switch a {
case "hello":
fmt.Println(1)
case "world":
fmt.Println(2)
default:
fmt.Println(0)
}
//分支多值。
var a = "mum"
switch a {
case "mum", "daddy":
fmt.Println("family")
}
//分支表达式
var r int = 11
switch {
case r > 10 && r < 20:
fmt.Println(r)
}
在Go语言中 case 是一个独立的代码块,执行完毕后不会像C语言那样紧接着执行下一个 case,但是为了兼容一些移植代码,依然加入了 fallthrough 关键字来实现这一功能。
var s = "hello"
switch {
case s == "hello":
fmt.Println("hello")
fallthrough //会继续执行下一个case。
case s != "world":
fmt.Println("world")
}
for
与多数语言不同的是,Go语言中的循环语句只支持 for 关键字,而不支持 while 和 do-while 结构。
可以通过break、continue、goto、return、panic 强制退出。
break,continue,goto 都支持调到label。 panic是异常处理。
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
for ; ; i++ {
if i > 10 {
break
}
}
//无限循环
sum := 0
for {
sum++
if sum > 100 {
break
}
}
// if 判断整合到 for 中
for i <= 10 {
i++
}
左花括号
{必须与 for 处于同一行。Go语言中的 for 循环与C语言一样,都允许在循环条件中定义和初始化变量,唯一的区别是,Go语言不支持以逗号为间隔的多个赋值语句,必须使用平行赋值的方式来初始化多个变量。
Go语言的 for 循环同样支持 continue 和 break 来控制循环,但是它提供了一个更高级的 break,可以选择中断哪一个循环,即break label。
函数
Go 语言支持普通函数、匿名函数和闭包(一般以lambda表达式表现),从设计上对函数进行了优化和改进,让函数使用起来更加方便。
Go 语言的函数属于“一等公民”(first-class),也就是说:
- 函数本身可以作为值进行传递。
- 支持匿名函数和闭包(closure)。
- 函数可以满足接口。
普通函数声明
func 函数名(形式参数列表)(返回值列表){
函数体
}
如果一组形参或返回值有相同的类型,我们不必为每个形参都写出参数类型,下面 2 个声明是等价的:
func f(i, j, k int, s, t string) { /* ... */ }
func f(i int, j int, k int, s string, t string) { /* ... */ }
空白标识符_可以强调某个参数未被使用。
func sub(x, y int) (z int) { z = x - y; return}
func first(x int, _ int) int { return x }
函数的类型被称为函数的标识符,如果两个函数形式参数列表和返回值列表中的变量类型一一对应,那么这两个函数被认为有相同的类型和标识符,形参和返回值的变量名不影响函数标识符也不影响它们是否可以以省略参数类型的形式表示。
Go语言没有默认参数值,也没有任何方法可以通过参数名指定形参,因此形参和返回值的变量名对于函数调用者而言没有意义。
在函数中,实参通过值传递的方式进行传递,因此函数的形参是实参的拷贝,对形参进行修改不会影响实参,但是,如果实参包括引用类型,如指针、slice(切片)、map、function、channel 等类型,实参可能会由于函数的间接引用被修改。
函数的返回值
Go语言支持**多返回值**,多返回值能方便地获得函数执行后的多个返回参数,Go语言经常使用多返回值中的最后一个返回参数返回函数执行中可能发生的错误。
conn, err := connectToNetwork()
Go语言既支持安全指针,也支持多返回值,因此在使用函数进行逻辑编写时更为方便。
- 同一种类型返回值
如果返回值是同一种类型,则用括号将多个返回值类型括起来,用逗号分隔每个返回值的类型。
func typedTwoValues() (int, int) {
return 1, 2
}
func main() {
a, b := typedTwoValues()
fmt.Println(a, b)
}
使用 return 语句返回时,值列表的顺序需要与函数声明的返回值类型一致。纯类型的返回值对于代码可读性不是很友好,特别是在同类型的返回值出现时,无法区分每个返回参数的意义。
- 带有变量名的返回值
Go语言支持对返回值进行命名,这样返回值就和参数一样拥有参数变量名和类型。
命名的返回值变量的默认值为类型的默认值,即数值为 0,字符串为空字符串,布尔为 false、指针为 nil 等。
func namedRetValues() (a, b int) {
a = 1
b = 2
return //返回时,会把a,b 返回。
//也可以指定返回值。
//return a,b
}
调用函数
返回值变量列表 := 函数名(参数列表)
//多个返回值之间用逗号分开。
函数变量
在Go语言中,函数也是一种类型,可以和其他类型一样保存在变量中。通过func()定义
func fire() {
fmt.Println("fire")
}
func main() {
var f func() //定义函数变量。
f = fire //给函数变量 赋值。
f()
}
匿名函数
//定义
func(参数列表)(返回参数列表){
函数体
}
- 在定义时调用匿名函数
func(data int) {
fmt.Println("hello", data)
}(100) //此处进行调用。类似 JavaScript。
- 将匿名函数赋值给变量
// 将匿名函数体保存到f()中
f := func(data int) {
fmt.Println("hello", data)
}
// 使用f()调用
f(100)
3)匿名函数用作回调函数
// 使用匿名函数打印切片内容
visit([]int{1, 2, 3, 4}, func(v int) {
fmt.Println(v)
})
4)使用匿名函数实现操作封装
下面这段代码将匿名函数作为 map 的键值,通过命令行参数动态调用匿名函数。
var skill = map[string]func(){
"fire": func() {
fmt.Println("chicken fire")
},
"run": func() {
fmt.Println("soldier run")
},
"fly": func() {
fmt.Println("angel fly")
},
}
if f, ok := skill[*skillParam]; ok {
f()
} else {
fmt.Println("skill not found")
}
以上特性类似于JavaScript语言。
函数类型实现接口
函数和其他类型一样都属于“一等公民”,其他类型能够实现接口,函数也可以。
结构体实现接口
// 调用器接口
type Invoker interface {
// 需要实现一个Call方法
Call(interface{})
}
// 结构体类型
type Struct struct {
}
// 实现Invoker的Call
func (s *Struct) Call(p interface{}) {
fmt.Println("from struct", p)
}
// 声明接口变量
var invoker Invoker
// 实例化结构体
s := new(Struct)
// 将实例化的结构体赋值到接口
invoker = s
// 使用接口调用实例化结构体的方法Struct.Call
invoker.Call("hello")
以上类似于JVM,JavaScript等,第一个参数作为Callee。
函数体实现接口
// 函数定义为类型
type FuncCaller func(interface{})
// 实现Invoker的Call。
//与struct不同之处就在于参数的类型。
func (f FuncCaller) Call(p interface{}) {
// 调用f()函数本体
f(p)
}
// 声明接口变量
var invoker Invoker
// 将匿名函数转为FuncCaller类型, 再赋值给接口。此处有函数转换。
invoker = FuncCaller(func(v interface{}) {
fmt.Println("from function", v)
})
// 使用接口调用FuncCaller.Call, 内部会调用函数本体
invoker.Call("hello")
闭包
闭包(Closure)——引用了外部变量的匿名函数。
Go语言中闭包是引用了自由变量的函数,被引用的自由变量和函数一同存在,即使已经离开了自由变量的环境也不会被释放或者删除,在闭包中可以继续使用这个自由变量,因此,简单的说:
函数 + 引用环境 = 闭包
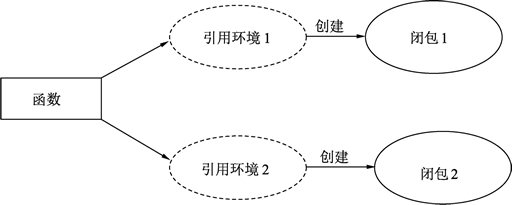
同一个函数与不同引用环境组合,可以形成不同的实例。一个函数类型就像结构体一样,可以被实例化,函数本身不存储任何信息,只有与引用环境结合后形成的闭包才具有“记忆性”,函数是编译期静态的概念,而闭包是运行期动态的概念。
闭包(Closure)在某些编程语言中也被称为 Lambda 表达式。
在闭包内部修改引用的变量
闭包对它作用域上的变量可以进行修改,修改引用的变量会对变量进行实际修改。
// 准备一个字符串
str := "hello world"
// 创建一个匿名函数
foo := func() {
// 匿名函数中访问str
str = "hello dude"
}
// 调用匿名函数
foo()
//输出:
// hello dude
闭包的记忆效应
被捕获到闭包中的变量让闭包本身拥有了记忆效应,闭包中的逻辑可以修改闭包捕获的变量,变量会跟随闭包生命期一直存在,闭包本身就如同变量一样拥有了记忆效应。
package main
import (
"fmt"
)
// 提供一个值, 每次调用函数会指定对值进行累加
func Accumulate(value int) func() int {
// 返回一个闭包
return func() int {
// 累加
value++
// 返回一个累加值
return value
}
}
func main() {
// 创建一个累加器, 初始值为1
accumulator := Accumulate(1)
// 累加1并打印
fmt.Println(accumulator()) //打印2
fmt.Println(accumulator()) //打印3
// 打印累加器的函数地址
fmt.Printf("%p\n", &accumulator)
// 创建一个累加器, 初始值为10
accumulator2 := Accumulate(10)
// 累加1并打印
fmt.Println(accumulator2()) //打印11
// 打印累加器的函数地址
fmt.Printf("%p\n", &accumulator2)
}
可变参数类型
可变参数是指函数传入的参数个数是可变的,为了做到这点,首先需要将函数定义为可以接受可变参数的类型:
func myfunc(args ...int) { //args 关键字
for _, arg := range args {
fmt.Println(arg)
}
}
defer(延迟执行语句)
Go语言的 defer 语句会将其后面跟随的语句进行延迟处理,在 defer 归属的函数即将返回时,将延迟处理的语句按 defer 的逆序进行执行,也就是说,先被 defer 的语句最后被执行,最后被 defer 的语句,最先被执行。
关键字 defer 的用法类似于面向对象编程语言 Java 和 C# 的 finally 语句块,它一般用于释放某些已分配的资源,典型的例子就是对一个互斥解锁,或者关闭一个文件。
多个延迟执行语句的处理顺序
当有多个 defer 行为被注册时,它们会以逆序执行(类似栈,即后进先出)。
使用延迟执行语句在函数退出时释放资源
递归函数
func fibonacci(n int) (res int) {
if n <= 2 {
res = 1
} else {
res = fibonacci(n-1) + fibonacci(n-2)
}
return
}
多个函数组成递归
Go语言中也可以使用相互调用的递归函数,多个函数之间相互调用形成闭环,因为Go语言编译器的特殊性,这些函数的声明顺序可以是任意的。
处理运行时错误
Go语言的错误处理思想及设计包含以下特征:
- 一个可能造成错误的函数,需要返回值中返回一个错误接口(error),如果调用是成功的,错误接口将返回 nil,否则返回错误。
- 在函数调用后需要检查错误,如果发生错误,则进行必要的错误处理。
Go语言希望开发者将错误处理视为正常开发必须实现的环节,正确地处理每一个可能发生错误的函数,同时,Go语言使用返回值返回错误的机制,也能大幅降低编译器、运行时处理错误的复杂度,让开发者真正地掌握错误的处理。
宕机(panic)——程序终止运行
虽然Go语言的 panic 机制类似于其他语言的异常,但 panic 的适用场景有一些不同,由于 panic 会引起程序的崩溃,因此 panic 一般用于严重错误,如程序内部的逻辑不一致。任何崩溃都表明了我们的代码中可能存在漏洞,所以对于大部分漏洞,我们应该使用Go语言提供的错误机制,而不是 panic。
手动触发宕机
package main
func main() {
panic("crash")
}
宕机恢复(recover)——防止程序崩溃
Go语言没有异常系统,其使用 panic 触发宕机类似于其他语言的抛出异常,recover 的宕机恢复机制就对应其他语言中的 try/catch 机制。
panic 和 recover 的关系
panic 和 recover 的组合有如下特性:
- 有 panic 没 recover,程序宕机。
- 有 panic 也有 recover,程序不会宕机,执行完对应的 defer 后,从宕机点退出当前函数后继续执行。
提示:
虽然 panic/recover 能模拟其他语言的异常机制,但并不建议在编写普通函数时也经常性使用这种特性。
在 panic 触发的 defer 函数内,可以继续调用 panic,进一步将错误外抛,直到程序整体崩溃。
如果想在捕获错误时设置当前函数的返回值,可以对返回值使用命名返回值方式直接进行设置。
结构
Go 语言通过用自定义的方式形成新的类型,结构体是类型中带有成员的复合类型.
Go 语言中的类型可以被实例化,使用new或&构造的类型实例的类型是类型的指针。
关于 Go 语言的类(class)
Go 语言中没有“类”的概念,也不支持“类”的继承等面向对象的概念。
Go 语言的结构体与“类”都是复合结构体,但 Go 语言中结构体的内嵌配合接口比面向对象具有更高的扩展性和灵活性。
Go 语言不仅认为结构体能拥有方法,且每种自定义类型也可以拥有自己的方法。
结构体定义
type 类型名 struct {
字段1 字段1类型
字段2 字段2类型
…
}
struct{}:表示结构体类型
实例化
//一般形式
var ins T
//创建指针类型的结构体
ins := new(T)
//取结构体的地址实例化
ins := &T{}
//示例:
type Command struct {
Name string // 指令名称
Var *int // 指令绑定的变量
Comment string // 指令的注释
}
var version int = 1
cmd := &Command{}
在Go语言中,对结构体进行&取地址操作时,视为对该类型进行一次 new 的实例化操作。
初始化结构体的成员变量
结构体在实例化时可以直接对成员变量进行初始化,初始化有两种形式分别是以字段“键值对”形式和多个值的列表形式,键值对形式的初始化适合选择性填充字段较多的结构体,多个值的列表形式适合填充字段较少的结构体。
键值对
ins := 结构体类型名{
字段1: 字段1的值,
字段2: 字段2的值,
…
}
type People struct {
name string
child *People
}
relation := &People{
name: "爷爷",
child: &People{
name: "爸爸",
child: &People{
name: "我",
},
},
}
多个值的列表
//所有字段必须初始化;
//字段顺序保持一致。
ins := 结构体类型名{
字段1的值,
字段2的值,
…
}
初始化匿名结构体
ins := struct {
// 匿名结构体字段定义
字段1 字段类型1
字段2 字段类型2
…
}{
// 字段值初始化
初始化字段1: 字段1的值,
初始化字段2: 字段2的值,
…
}
接口
Go 语言中使用组合实现对象特性的描述。对象的内部使用结构体内嵌组合对象应该具有的特性,对外通过接口暴露能使用的特性。
Go 语言的接口设计是非侵入式的,接口编写者无须知道接口被哪些类型实现。而接口实现者只需知道实现的是什么样子的接口,但无须指明实现哪一个接口。编译器知道最终编译时使用哪个类型实现哪个接口,或者接口应该由谁来实现。
非侵入式设计是 Go 语言设计师经过多年的大项目经验总结出来的设计之道。只有让接口和实现者真正解耦,编译速度才能真正提高,项目之间的耦合度也会降低不少。
接口声明的格式
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
接口类型名:使用 type 将接口定义为自定义的类型名。Go语言的接口在命名时,一般会在单词后面添加 er,如有写操作的接口叫 Writer,有字符串功能的接口叫 Stringer,有关闭功能的接口叫 Closer 等
实现条件
如果一个任意类型 T 的方法集为一个接口类型的方法集的超集,则我们说类型 T 实现了此接口类型。T 可以是一个非接口类型,也可以是一个接口类型。实现关系在Go语言中是隐式的。两个类型之间的实现关系不需要在代码中显式地表示出来。Go语言中没有类似于 implements 的关键字。 Go编译器将自动在需要的时候检查两个类型之间的实现关系。
接口定义后,需要实现接口,调用方才能正确编译通过并使用接口。接口的实现需要遵循两条规则才能让接口可用。
1、接口的方法与实现接口的类型方法格式一致
在类型中添加与接口签名一致的方法就可以实现该方法。签名包括方法中的名称、参数列表、返回参数列表。也就是说,只要实现接口类型中的方法的名称、参数列表、返回参数列表中的任意一项与接口要实现的方法不一致,那么接口的这个方法就不会被实现
2、接口中所有方法均被实现
类型与接口的关系
- 一个类型可以实现多个接口
- 多个类型可以实现相同的接口
类型断言
类型断言(Type Assertion)是一个使用在接口值上的操作,用于检查接口类型变量所持有的值是否实现了期望的接口或者具体的类型。
在Go语言中类型断言的语法格式如下:
value, ok := x.(T)
//需要注意如果不接收第二个参数也就是上面代码中的 ok,断言失败时会直接造成一个 panic。如果 x 为 nil 同样也会 panic。
其中,x 表示一个接口的类型,T 表示一个具体的类型(也可为接口类型)。
该断言表达式会返回 x 的值(也就是 value)和一个布尔值(也就是 ok),可根据该布尔值判断 x 是否为 T 类型:
- 如果 T 是具体某个类型,类型断言会检查 x 的动态类型是否等于具体类型 T。如果检查成功,类型断言返回的结果是 x 的动态值,其类型是 T。
- 如果 T 是接口类型,类型断言会检查 x 的动态类型是否满足 T。如果检查成功,x 的动态值不会被提取,返回值是一个类型为 T 的接口值。
- 无论 T 是什么类型,如果 x 是 nil 接口值,类型断言都会失败。
类型分支
switch 接口变量.(type) {
case 类型1:
// 变量是类型1时的处理
case 类型2:
// 变量是类型2时的处理
…
default:
// 变量不是所有case中列举的类型时的处理
}
error接口
type error interface {
Error() string
}
操作符
运算符优先级和结合性
| 优先级 | 分类 | 运算符 | 结合性 |
|---|---|---|---|
| 1 | 逗号运算符 | , | 从左到右 |
| 2 | 赋值运算符 | =、+=、-=、*=、/=、 %=、 >=、 <<=、&=、^=、|= | 从右到左 |
| 3 | 逻辑或 | || | 从左到右 |
| 4 | 逻辑与 | && | 从左到右 |
| 5 | 按位或 | | | 从左到右 |
| 6 | 按位异或 | ^ | 从左到右 |
| 7 | 按位与 | & | 从左到右 |
| 8 | 相等/不等 | ==、!= | 从左到右 |
| 9 | 关系运算符 | <、<=、>、>= | 从左到右 |
| 10 | 位移运算符 | <<、>> | 从左到右 |
| 11 | 加法/减法 | +、- | 从左到右 |
| 12 | 乘法/除法/取余 | *(乘号)、/、% | 从左到右 |
| 13 | 单目运算符 | !、*(指针)、& 、++、–、+(正号)、-(负号) | 从右到左 |
| 14 | 后缀运算符 | ( )、[ ]、-> | 从左到右 |














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









