







- 提示需要修改URL,照片中显示三个数字238,38在2的右上角表示次方,修改URL地址为http://www.pythonchallenge.com/pc/def/274877906944.html
- 图片提示显示K→M,O→Q,E→G,观察获得替换规律:将每个字母向后两位的字母替换原字母组成新的字符串。
`def solve_1(string):
letters = "abcdefghijklmnopqrstuvwxyz"
ret = []
for item in list(string):
if item in letters:
chan = letters.index(item)+2
if chan <= len(letters)-1:
pass
else:
chan = chan - len(letters)
item = letters[chan]
ret.append(item)
print(''.join(ret))
solve_1("g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.")`
输出结果为:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
将函数应用到URL上,map转换为orc,获得下一题的URL。http://www.pythonchallenge.com/pc/def/ocr.html
- 页面提示:recognize the characters. maybe they are in the book,but MAYBE they are in the page source.;提示应该在page source里,打开网页源代码,发现存在一段很长的注释,包含很多特殊符号,根据提示应该是需要匹配这段内容里的字母。
def rec_characters():
with open("./pythonchallenge_2.txt", "r")as f:
data = f.readlines()
ret = []
for line in data:
letter = re.findall(r"[a-zA-Z]+", line)
if len(letter)>0:
ret += letter
print(''.join(ret))
rec_characters()
输出结果为:
equality
获得下一题的URL为http://www.pythonchallenge.com/pc/def/equality.html
- 提示为One small letter, surrounded by EXACTLY three big bodyguards on each of its sides.打开页面源代码又看到最后有一段注释,即需要寻找三个大写字母+一个小写字母+三个大写字母的字符串,且前后必须有且仅有三个大写字母,使用正则表达式匹配:
def find_pa():
with open("./pychallenge_3.txt", "r") as f:
data = f.read().replace('\n', '')
letter = re.findall(r"[a-z]+[A-Z]{3}([a-z])[A-Z]{3}[a-z]+", data)
print(''.join(letter))
输出结果为:
linkedlist
获得下一题URL为http://www.pythonchallenge.com/pc/def/linkedlist.php(输入文件后缀为html跳转页面会提示是.php文件)
- 页面标题提示follow the chain,查看源代码,注释提示:urllib may help. DON’T TRY ALL NOTHINGS, since it will never end. 400 times is more than enough.点击图片提示:and the next nothing is 44827;URL增加?nothing=12345;尝试将12345修改为44827,跳转页面显示next nothing is 45439.应该是需要用urlib库模拟该过程,直到获取最后的数据,大概需要400次。中途发现存在仅包含字符的页面,因此修改代码,在找不到数字时暂停判断一下:最后在450左右输出peak.html
from urllib import request
def get_nothing():
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345"
nothing = ""
time =1
while nothing != "quit":
req = request.Request(url)
with request.urlopen(req) as web:
text = web.read().decode('utf-8')
nothing = ''.join(re.findall(r"[0-9]+", text))
time+=1
print(time, text)
if nothing:
index = url.index("=")
else:
nothing = input("input nothing:")
url = url[:index + 1] + nothing
获取下一题URL为http://www.pythonchallenge.com/pc/def/peak.html
- 注释里有:peak hell sounds familiar,peak hell念快了听起来像pickle,查看网页源代码,有文件banner.p,使用pickle库将banner.p文件内的内容序列化
import pickle
#用于序列化和反序列化的库
def pickle_text():
text = pickle.load(request.urlopen("http://www.pythonchallenge.com/pc/def/banner.p"))
for item in text:
for tup in item:
print(tup[0]*tup[1],end='')
print('')
pickle_text()
输出结果为:
##### #####
#### ####
#### ####
#### ####
#### ####
#### ####
#### ####
#### ####
### #### ### ### ##### ### ##### ### ### ####
### ## #### ####### ## ### #### ####### #### ####### ### ### ####
### ### ##### #### ### #### ##### #### ##### #### ### ### ####
### #### #### ### ### #### #### #### #### ### #### ####
### #### #### ### #### #### #### #### ### ### ####
#### #### #### ## ### #### #### #### #### #### ### ####
#### #### #### ########## #### #### #### #### ############## ####
#### #### #### ### #### #### #### #### #### #### ####
#### #### #### #### ### #### #### #### #### #### ####
### #### #### #### ### #### #### #### #### ### ####
### ## #### #### ### #### #### #### #### #### ### ## ####
### ## #### #### ########### #### #### #### #### ### ## ####
### ###### ##### ## #### ###### ########### ##### ### ######
获得下一题URL为:http://www.pythonchallenge.com/pc/def/channel.html
- 源代码包含提示zip,将html修改为zip后下载压缩文件channel.zip,打开readme.txt,提示从90052开始,打开90052.txt,文件内容为next nothing is 94191.和follow the chain差不多,只是现在是在压缩文件内寻找:
import zipfile
def zip_find_nothing():
zf = zipfile.ZipFile("./channel.zip", 'r')
comments = ""
file_name = '90052'
while file_name != "quit":
text = zf.read(file_name+".txt").decode('utf-8')
info = zf.getinfo(file_name+'.txt')
print(info.comment)
comments += info.comment.decode('utf-8')
nothing = ''.join(re.findall(r"[0-9]+", text))
if nothing:
print(nothing)
else:
print(text)
break
file_name = nothing
print(comments)
第一次仅遍历文件,最后出现文件内容显示:Collect the comments,zipfile可以获取文件说明,属性名即为comment,所以重新开始遍历,每次获取文件的comment,最后显示结果为:
****************************************************************
****************************************************************
** **
** OO OO XX YYYY GG GG EEEEEE NN NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN NN **
** OO OO XXX XXX YYY YY GG GG EE NN NN **
** OOOOOOOO XX XX YY GGG EEEEE NNNN **
** OOOOOOOO XX XX YY GGG EEEEE NN **
** OO OO XXX XXX YYY YY GG GG EE NN **
** OO OO XXXXXX YYYYYY GG GG EEEEEE NN **
** OO OO XX YYYY GG GG EEEEEE NN **
** **
****************************************************************
**************************************************************
修改URL为hockey.html,显示it’s in the air. look at the letters.
获得下一题URL为:http://www.pythonchallenge.com/pc/def/oxygen.html
- 源代码无明显提示,猜测是需要处理图片,使用PIL库,(参考)
from PIL import Image
def oxygen():
img = Image.open('./oxygen.png', 'r')
width, height = img.size
h = height/2
pic = img.load()
data = []
for x in range(width):
#元组表示RGB数据
if (pic[x, h][0] == pic[x, h][1]) and (pic[x, h][1] == pic[x, h][2]):
data.append(pic[x, h][0])
ret = ""
for i in data:
ret += chr(i)
print(ret)
第一次输出结果:
sssssmmmmmmmaaaaaaarrrrrrrttttttt ggggggguuuuuuuyyyyyyy,,,,,,, yyyyyyyooooooouuuuuuu mmmmmmmaaaaaaadddddddeeeeeee iiiiiiittttttt....... ttttttthhhhhhheeeeeee nnnnnnneeeeeeexxxxxxxttttttt llllllleeeeeeevvvvvvveeeeeeelllllll iiiiiiisssssss [[[[[[[111111100000005555555,,,,,,, 111111111111110000000,,,,,,, 111111111111116666666,,,,,,, 111111100000001111111,,,,,,, 111111100000003333333,,,,,,, 111111111111114444444,,,,,,, 111111100000005555555,,,,,,, 111111111111116666666,,,,,,, 111111122222221111111]]]]]]]]
可以看到有很多重复字符,观察得到除第一个字符外,其他字符循环周期为7,所以增加去除连续重复字符的操作:
from PIL import Image
def oxygen():
img = Image.open('./oxygen.png', 'r')
width, height = img.size
h = height/2
pic = img.load()
data = []
num = 5
for x in range(width):
#元组表示RGB数据
#找规律:最开始是5个元素,之后每7个元素为一组
if (pic[x, h][0] == pic[x, h][1]) and (pic[x, h][1] == pic[x, h][2]):
if num > 1:
num -= 1
else:
data.append(pic[x, h][0])
num = 7
ret = ""
for i in data:
ret += chr(i)
print(ret)
输出结果:
smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]
解析最后得到的数组ASCII码:
integrity
获得下一题URL为:http://www.pythonchallenge.com/pc/def/integrity.html
- 源代码提示有un和pw两个字符串,参考https://blog.csdn.net/weixin_46283214/article/details/105389166引入bz2库进行解码:
import bz2
def bz2_decompress():
user = b"BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084"
pw = b"BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08"
print("user:", bz2.decompress(user).decode('utf-8'))
print("ps:", bz2.decompress(pw).decode('utf-8'))
点击图片上的蜜蜂,弹出登陆界面,将解码结果输入,跳转下一题界面:http://www.pythonchallenge.com/pc/return/good.html
- 标题提示connect the dots,源代码注释有提示两组数据first和second,以及first+second=?,使用PIL库的ImageDraw模块将两组数据连线,得到一个牛的图案。获得下一题URL:http://www.pythonchallenge.com/pc/return/bull.html
- 点击图片上的牛,跳转页面sequence.txt,显示:
a = [1, 11, 21, 1211, 111221,
图片下方提示len(a[30]) = ?,要根据a的现有元素找规律,计算出a[30]的长度,可以看出:
a[0]=1——1个1
a[1]=11——2个1
a[2]=21——1个2 1个1
a[3]=1211——1个1 1个2 2个1
a[4]=111221——3个1 2个2 1个1
所以得出规律:a[i+1] = a[i]从左到右的数字个数描述
def num_count():
a = '1'
num = '1'
flag = 0
ret = []
for i in range(30):
for ch in a:
if ch != num:
ret.append(str(flag))
ret.append(num)
num = ch
flag = 1
else:
flag += 1
ret.append(str(flag))
ret.append(num)
a = ''.join(ret)
num = a[0]
flag = 0
ret = []
print(len(a))
输出结果5808,获得下一题URL为:http://www.pythonchallenge.com/pc/return/5808.html
- 图像处理不熟悉,没做。可参考https://blog.csdn.net/weixin_46283214/article/details/105450074?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-1&spm=1001.2101.3001.4242
- gfx不熟悉,没做。参考https://blog.csdn.net/Jurbo/article/details/52291403?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control&dist_request_id=1332024.4886.16189670869155289&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control
- 没做,可参考上面的链接
- 参考https://blog.csdn.net/xiaoquantouer/article/details/51577929?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-4&spm=1001.2101.3001.4242
def get_pic():
img = Image.open('./wire.png')
ret = Image.new(img.mode, (100, 100))
move = [(1, 0), (0, 1), (-1, 0), (0, -1)]#右,上,左,下,每次转90度
step = [[i, i - 1, i - 1, i - 2] for i in range(100, 1, -2)]
index = 0
circle = 0
x, y = -1, 0
round = 0
for i in range(10000):
x += move[index][0]
y += move[index][1]
print(x, y)
pix = img.getpixel((i, 0))
ret.putpixel((x, y), pix)
if round != step[circle][index]-1:
round += 1
else:
round = 0
index += 1
if index == 4:
index = 0
circle += 1
ret.show()
得到图片:

修改URL为cat后得到猫咪的名字uzi
获得下一题URL:
http://www.pythonchallenge.com/pc/return/uzi.html
- 源代码提示1: he ain’t the youngest, he is the second;提示2: todo: buy flowers for tomorrow。图片显示是1xx6年的一月份,26号是星期一,右下角显示二月份有29天,所以要找出是闰年的满足1xx6的第二个年份。
import calendar
def find_year():
years = ['1'+str(y)+str(x)+'6' for x in range(1,10) for y in range(1,10)]
ret = []
for year in years:
if calendar.isleap(int(year)):
weekday = datetime.datetime(int(year), 1, 26).strftime("%a")
if weekday == 'Mon':
ret.append(int(year))
ret.sort()
print(ret[-2])
输出结果:
1756
1756年1月27是莫扎特的生日,获得下一题URL:http://www.pythonchallenge.com/pc/return/mozart.html
- 将有颜色的像素拉直,将有色像素及其右边的像素移到左边,有色像素左边的像素移到右边
def get_straight():
gif = Image.open("mozart.gif")
img = Image.new(gif.mode, gif.size)
width, height = gif.size[0], gif.size[1]
for i in range(height):
pixs = [gif.getpixel((x, i)) for x in range(width)]
#把每一行的195移到最前面
#获取有色像素点索引
color = [k for k, v in enumerate(pixs) if v == 195]
#将有颜色的像素之后的所有像素移到左边
for index in range(color[-1], width):
img.putpixel((index-color[-1], i), gif.getpixel((index, i)))
#将有色像素之前的像素移到之后
for index in range(width-1-color[-1], width):
img.putpixel((index, i), gif.getpixel((index-width+1+color[-1], i)))
img.show()
获得下一题URL:
def get_cookieinfo():
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?busynothing="
busynothing = "12345"
get_time = 1
cookie_dict = {"Set-Cookie": []}
while busynothing != "it.":
req = request.Request(url+busynothing)
with request.urlopen(req) as web:
text = web.read().decode('utf-8')
header = web.getheaders()
for k, v in header:
if "Set-Cookie" in k:
value = v.split(';')
cookie_dict[k].append(value[0])
busynothing = text.split(' ')[-1]
if busynothing:
pass
else:
busynothing = input("input nothing:")
break
bz2_code = ''
for info in cookie_dict['Set-Cookie']:
index = info.index('=')
bz2_code += info[index+1:]
print(bz2_code)
new_data = bz2_code.replace('+', '%20')
new_data = urllib.parse.unquote_to_bytes(new_data)
print(new_data)
print("ps:", bz2.decompress(new_data).decode('utf-8'))
server = ServerProxy("http://www.pythonchallenge.com/pc/phonebook.php")
print(server.phone('Leopold'))
获得URL:http://www.pythonchallenge.com/pc/stuff/violin.php,注意输出结果是:ps: is it the 26th already? call his father and inform him that “the flowers are on their way”. he’ll understand.需要告诉他"the flowers are on their way"
在cookie中加上"the flowers are on their way"
headers = { 'Cookie': 'info=the flowers are on their way'}
req = request.Request(url = 'http://www.pythonchallenge.com/pc/stuff/violin.php', headers=headers)
with request.urlopen(req) as web:
text = web.read().decode('utf-8')
print(text)
返回结果为:
<html>
<head>
<title>it's me. what do you want?</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<br><br>
<center><font color="gold">
<img src="leopold.jpg" border="0"/>
<br><br>
oh well, don't you dare to forget the balloons.</font>
</body>
</html>
获得下一题URL为:http://www.pythonchallenge.com/pc/return/balloons.html
- 参考https://editor.csdn.net/md?not_checkout=1&articleId=115907644
首先根据源代码提示,两图的差异在于亮度,修改URL为http://www.pythonchallenge.com/pc/return/brightness.html提示或许需要使用gzip,修改后缀为gzip后下载一个.gz文件,使用gzip模块打开后发现数据分为左右两边,所以是需要对比两边的数据,然后就没什么思路了,参考链接后才知道原来是要用difflib模块,还要把区分的数据分开写入三个文件里:
import gzip
import difflib
import binascii
def gzip_read():
img_data = ["", "", ""]
img1 = open("./img1.png", "wb")
img2 = open("./img2.png", "wb")
img3 = open("./img3.png", "wb")
data_list1 = []
data_list2 = []
with gzip.open('./deltas.gz', 'rb') as gzip_file:
for line in gzip_file:
data = str(line.decode('utf-8').strip('\n'))
#除最后一行,前面部分长度为53,总体长度为109
s1 =data[:53].rstrip(' ')
s2 = data[56:]
if s1 != '':
data_list1.append(s1)
if s2 != '':
data_list2.append(s2)
d = list(difflib.ndiff(data_list1, data_list2))
for dif in d:
if dif[0] == ' ':
img_data[0] += ''.join(dif[1:])
elif dif[0] == '+':
img_data[1] += ''.join(dif[1:])
elif dif[0] == '-':
img_data[2] += ''.join(dif[1:])
img1.write(binascii.unhexlify(img_data[0].replace(' ', '')))
img2.write(binascii.unhexlify(img_data[1].replace(' ', '')))
img3.write(binascii.unhexlify(img_data[2].replace(' ', '')))
遇到的两个问题一个是ndiff函数的使用,函数的两个参数要求是字符串数组,最开始用字符串输入时也可以成功运行,但输出的数据有误,写入图片以后打不开;另一个是写入文件时,需要把十六进制的数据转换成二进制的字节数据写入,直接写入十六进制的字节数据也无法打开正确图片。
获得以下图片:


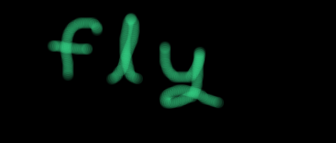
获得下一题的URL:http://www.pythonchallenge.com/pc/hex/bin.html
登录框用户名密码填写图片显示内容即可。
- 页面提示有.wav文件和base64,先用base64将源代码里的数据解码,写入wav文件,只听见一个sorry,又查了攻略发现要把文件颠倒,参考https://blog.csdn.net/enderman19980125/article/details/102529120?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-8.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-8.control
import base64
import wave
def encode_base64(encrypt):
text = base64.b64decode(encrypt)
with open("./base64.wav", "wb") as wav:
wav.write(text)
with wave.open("./base64.wav", "rb") as wav:
with wave.open("./reverse.wav", "wb") as f:
f.setparams(wav.getparams())
for i in range(wav.getnframes()):
f.writeframes(wav.readframes(1)[::-1])
获得下一题URL:http://www.pythonchallenge.com/pc/hex/idiot.html,进入后点击进入下一level即可进入下一题。
- 参考各种资料…
def inspect_web():
# start = 30203
start = 2123456744
end = start+1
url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg"
for i in range(50):
headers = {'Range': f'bytes={start}-{end}', 'Authorization': 'Basic YnV0dGVyOmZseQ=='}
req = request.Request(url=url, headers=headers)
with request.urlopen(req) as web:
data = web.read()
print(data)
byte_range = dict(web.info())['Content-Range']
pattern = re.compile(r"bytes ([0-9|-]+)")
byte_range = pattern.findall(byte_range)
byte_range = byte_range[0].split('-')
print(byte_range)
start = int(byte_range[1])+1
end = start+1
print(start, end)
'''
##start = 30203
b"Why don't you respect my privacy?\n"
['30203', '30236']
30237 30238
b'we can go on in this way for really long time.\n'
['30237', '30283']
30284 30285
b'stop this!\n'
['30284', '30294']
30295 30296
b'invader! invader!\n'
['30295', '30312']
30313 30314
b'ok, invader. you are inside now. \n'
['30313', '30346']
30347 30348
HTTP Error 416
##start = 2123456744
b'esrever ni emankcin wen ruoy si drowssap eht\n'
['2123456744', '2123456788']
2123456789 2123456790
b'esrever ni emankcin wen ruoy si drowssap eht\n'
['2123456744', '2123456788']
2123456789 2123456790
b'esrever ni emankcin wen ruoy si drowssap eht\n'
['2123456744', '2123456788']
......
'''
此时将URL修改为invader.html,显示”Yes! that’s you!“
反过来查看:
for i in range(50):
headers = {'Range': f'bytes={start}-{end}', 'Authorization': 'Basic YnV0dGVyOmZseQ=='}
req = request.Request(url=url, headers=headers)
with request.urlopen(req) as web:
data = web.read()
print(data)
byte_range = dict(web.info())['Content-Range']
pattern = re.compile(r"bytes ([0-9|-]+)")
byte_range = pattern.findall(byte_range)
byte_range = byte_range[0].split('-')
print(byte_range)
end = int(byte_range[0])-1
start = end - 1
print(start, end)
得到输出:
b'esrever ni emankcin wen ruoy si drowssap eht\n'
['2123456744', '2123456788']
2123456742 2123456743
b'and it is hiding at 1152983631.\n'
['2123456712', '2123456743']
2123456710 2123456711
访问1152983631,读到的数据很多,将其保存为zip文件:
for i in range(50):
headers = {'Range': f'bytes={start}-{end}', 'Authorization': 'Basic YnV0dGVyOmZseQ=='}
req = request.Request(url=url, headers=headers)
with request.urlopen(req) as web:
data = web.read()
print(data)
with open("./invader.zip", "wb") as inf:
inf.write(data)
byte_range = dict(web.info())['Content-Range']
pattern = re.compile(r"bytes ([0-9|-]+)")
byte_range = pattern.findall(byte_range)
byte_range = byte_range[0].split('-')
print(byte_range)
end = int(byte_range[0])-1
start = end - 1
print(start, end)
解压文件,输入密码为redavni解压readme.txt文件获得
Yes! This is really level 21 in here.
And yes, After you solve it, you'll be in level 22!
Now for the level:
* We used to play this game when we were kids
* When I had no idea what to do, I looked backwards.
- 解压package.pack文件,参考搜索到的各种资料,最后输出什么字符没搞懂为什么这么输出,感觉只是猜出来的,输出的都是字符的话能隐约看出有些隐藏信息,然后修改字符让人眼能够看得更清楚。
import zlib
def zlib_file():
with open("./invader/package.pack", "rb") as z_f:
text = z_f.read()
while True:#循环解压
if text.startswith(b"x\x9c"):
text = zlib.decompress(text)
print('-', end='')
elif text.startswith(b"BZ"):
text = bz2.decompress(text)
print('b', end='')
elif text.endswith(b"\x9cx"):
text = text[::-1]
print('\n', end='')
else:
print("\nfinal text:", text[::-1])
break















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









