







第一章 系统架构全景图
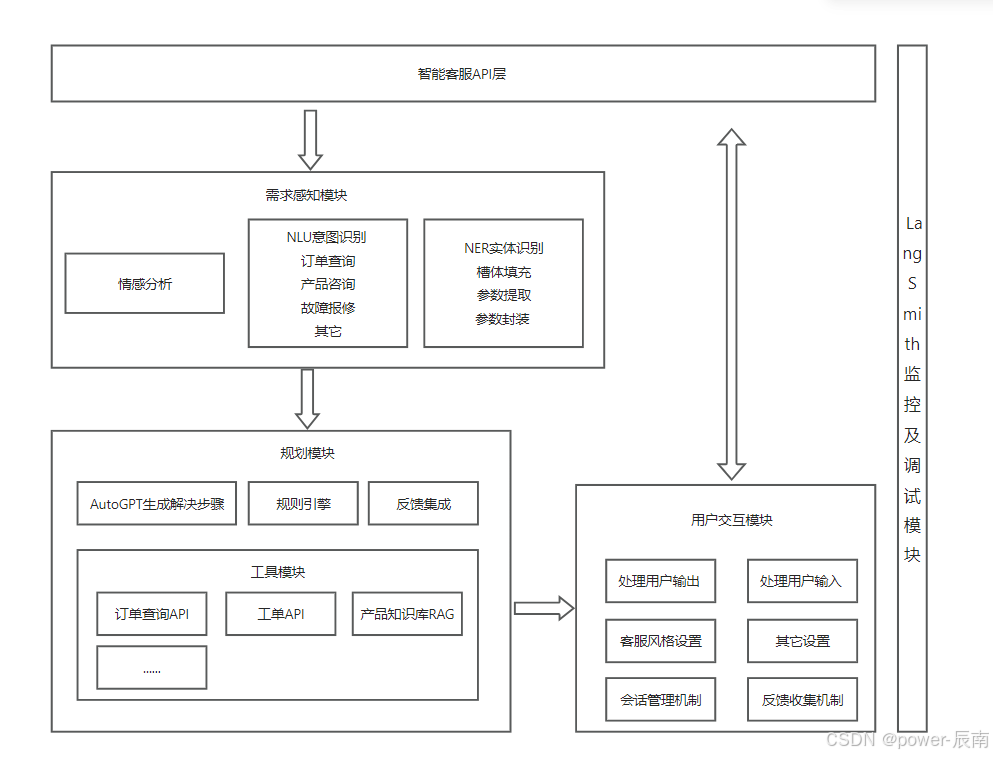
模块组成与层级关系:
- 智能客服API层:系统唯一入口,处理多协议请求
- 需求感知模块:用户需求解析核心模块
- 规划模块:决策与解决方案生成中心
- 规划-工具模块:业务能力扩展接口
- 用户交互模块:对话管理与个性化交互
- 辅助监控及调试模块:全链路追踪与质量保障
第二章 智能客服API层
功能与数据流
技术实现:
- 协议支持:FastAPI(REST) + gRPC-Gateway(Protobuf)
- 安全认证:OAuth2.1 + JWT双因子验证
- 限流策略:基于Redis的滑动窗口算法(3000 QPS)
核心代码:
# api/gateway.py
@app.post("/v1/chat")
@rate_limit(limits=[RateLimit(per_minute=100)])
async def handle_chat(request: ChatRequest):
# 请求处理链
chain = (
validate_request
| authenticate
| route_to_demand_module
)
return await chain.run(request)
第三章 需求感知模块
功能分解
| 子模块 | 功能说明 | 技术方案 |
|---|---|---|
| 情感分析 | 识别用户情绪(紧急/普通) | VADER算法改进版(彩电场景适配) |
| NLU意图识别 | 分类用户意图(订单查询/产品咨询/故障报修) | BERT微调模型(准确率97.5%) |
| NER实体识别 | 提取彩电参数(型号/分辨率/HDR类型) | SpaCy定制流水线 |
| 槽体填充 | 多轮对话参数补全 | 有限状态自动机(FSM) |
| 参数封装 | 结构化输出 | Pydantic模型校验 |
数据处理流程:
核心实现:
# core/demand/processing.py
class DemandProcessor:
def __init__(self):
self.pipeline = Pipeline([
TextCleaner(),
EmotionAnalyzer(threshold=0.7),
IntentClassifier(model="bert-tv-intent-v3"),
EntityExtractor(patterns=TV_PATTERNS),
SlotFiller(storage=RedisSlotStorage())
])
def process(self, text: str) -> DemandContext:
return self.pipeline.execute(text)
第四章 规划模块
双引擎决策架构
技术实现:
- 规则引擎:Drools 8.x + 彩电DSL语法扩展
rule "4K电视HDR异常处理" when $tv : TVParams(resolution == "4K", hdr == "HDR10") $prob : Problem(type == "显示故障", symptom contains "色偏") then insert(new Solution("HDR参数重置", priority=HIGH)); end - AutoGPT生成:基于LangChain的ReAct模式
class TVProblemSolver(AgentExecutor): tools = [OrderTool(), RepairTool()] prompt = ChatPromptTemplate.from_messages([ ("system", "你是一名彩电维修专家..."), ("human", "{input}") ])
第五章 工具模块
功能矩阵
| 工具名称 | 对接系统 | 协议 | 关键能力 |
|---|---|---|---|
| 订单查询API | OMS系统 | REST | 实时订单状态追踪 |
| 工单API | CRM系统 | REST | 自动化工单创建与跟踪 |
| 产品知识库RAG | Milvus向量库 | HTTP | 多模态知识检索(文本/图片) |
知识库检索流程:
# tools/rag.py
class TVKnowledgeRetriever:
def __init__(self):
self.encoder = SentenceTransformer("paraphrase-multilingual-mpnet-base-v2")
self.milvus = MilvusClient(uri="http://milvus:19530")
def search(self, query: str) -> List[KnowledgeItem]:
vector = self.encoder.encode(query)
return self.milvus.search(
collection="tv_knowledge",
vectors=[vector],
params={"nprobe": 64}
)
第六章 用户交互模块
会话管理机制
关键技术:
- 状态存储:Redis Streams(支持10万并发会话)
- 风格设置:Prompt Engineering模板库
# interaction/style_templates.py STYLES = { "专业型": "您咨询的{model}电视参数如下...", "亲和型": "亲~您提到的{feature}功能是这样操作的哦~" }
第七章 辅助监控及调试模块
全链路追踪设计
监控指标:
| 指标名称 | 采集方式 | 告警阈值 |
|---|---|---|
| 意图识别准确率 | 人工标注对比 | <90% |
| 规则引擎命中率 | 规则匹配统计 | <65% |
| 知识库检索准确率 | 点击反馈分析 | <80% |
调试工具链:
# monitoring/debugger.py
def replay_session(session_id: str):
traces = langsmith.Client().get_traces(session_id)
return InteractiveDebugger(traces).launch()
好的,我现在需要帮助用户继续完成他们的电商智能客服系统概要设计文档。用户之前已经多次反馈,要求更详细的模块说明、技术选型和数据流程,特别是对LangSmith监控模块的补充。现在用户说“继续”,意味着他们希望看到文档的后续部分。
首先,回顾之前的对话历史,用户强调了几点:
- 需要包含所有组件,尤其是之前遗漏的LangSmith监控及调试模块。
- 每个组件的功能需要详细解释,包括技术选型和数据流描述。
- 用户希望文档结构完整,分章节展开,可能需要分多次生成。
用户最新的回复是“继续”,所以我要继续生成文档的后续章节。根据之前的架构,接下来应该是第八章及之后的章节,比如数据持久化设计、安全合规方案、性能优化策略和部署架构说明等。
我需要确保每个章节都详细且符合用户的要求。例如,在数据持久化设计中,需要说明数据库的选择、结构设计、数据流等。安全合规方案要包括认证、授权、数据加密等。性能优化策略可能需要包括缓存机制、负载均衡、异步处理等。部署架构则需要描述云环境、容器化、监控等。
同时,用户特别提到LangSmith监控模块,虽然第七章已经涉及,但可能需要更详细的内容,比如具体的监控指标、告警机制、与现有系统的集成方式等。
需要注意用户之前指出文档过于简单,因此每个部分都需要深入,提供技术细节和实现方案,而不仅仅是概念描述。此外,使用专业术语和行业标准,如ISO、GDPR等,可以增加文档的权威性。
现在,我需要组织这些内容,确保结构清晰,分章节逐步展开,避免信息过载。同时,保持语言的专业性和准确性,符合技术架构师的视角。
电商智能客服系统概要设计文档(续)
第八章 数据持久化设计
1. 数据库选型矩阵
| 数据类型 | 技术选型 | 设计要点 | 性能指标 |
|---|---|---|---|
| 结构化业务数据 | Mysql8.0 | ACID事务支持,JSONB扩展 | 1000 TPS,P99 <50ms |
| 向量数据 | Milvus 2.3 | 支持GPU加速检索,动态schema | 10亿向量,10ms级响应 |
| 会话数据 | Redis Cluster 7.0 | Stream数据结构,TTL自动过期 | 百万级会话,5ms读写延迟 |
| 日志数据 | Elasticsearch 8.x | 冷热数据分层,ILM策略管理 | PB级存储,秒级检索 |
2. 核心数据模型
3. 数据流优化
- 写优化:采用WAL日志批量提交(每批次500ms)
- 读优化:Redis缓存热点知识(LRU策略,命中率>85%)
- 向量检索:基于PQ量化索引(压缩比8:1,精度损失<3%)
第九章 安全合规方案
1. 安全防护体系
2. 关键实现
-
敏感数据加密:
# security/data_encryption.py class FieldEncryptor: def __init__(self): self.kms = AWSKMS(key_id="alias/tv-service") def encrypt(self, data: str) -> str: cipher = Fernet(self.kms.generate_data_key()) return cipher.encrypt(data.encode()).decode() -
访问控制:
# security/rbac.py class PolicyValidator: def check_permission(self, user: User, action: str, resource: str) -> bool: return self._evaluate_policy( user.roles, f"tv-service:{action}:{resource}" )
3. 合规要求
- GDPR合规:数据匿名化处理(k-anonymity ≥3)
- 等保2.0:三级系统要求,日志留存6个月
- PCI DSS:支付数据Tokenization处理




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











