







N-Gram是大词汇连续语音识别中常用的一种语言模型。在语音识别中,对中文而言,我们称之为汉语语言模型(CLM, Chinese Language Model)。汉语语言模型利用上下文中相邻词间的搭配信息,在需要把连续无空格的拼音、笔划,或代表字母或笔划的数字,转换成汉字串(即句子)时,可以计算出具有最大概率的句子,从而实现到汉字的自动转换,无需用户手动选择,避开了许多汉字对应一个相同的拼音(或笔划串,或数字串)的重码问题。
该模型基于假设–第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。常用的是二元的Bi-Gram和三元的Tri-Gram模型。
对于一个句子T,如何计算其出现的概率呢?假设T由词序列W1,W2,W3,…Wn组成,则P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)。
补充下概率相关的知识:
P(B|A)=P(AB)/P(A),即P(AB)=P(B|A)P(A),P(A)>0;
P(A1A2…An)=P(A1)P(A2|A1)…P(An|A1A2…An),P(An|A1A2…An)>0.
但是N-Gram方法存在两个致命的缺陷:一是参数空间过大,不实用;另外一个是数据稀疏严重。
为了解决这个问题,我们引入了马尔科夫假设:一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bi-Gram(二元模型),句子的概率为:
P(T) = P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1).
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram(三元模型)。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。
那么如何得到P(Wn|W1W2…Wn-1)呢?一种简单的估计方法就是最大似然估计(Maximum Likelihood Estimate)了。即P(Wn|W1W2…Wn-1) = (C(W1 W2…Wn))/(C(W1 W2…Wn-1))。最后就是在训练语料库中统计序列C(W1 W2…Wn) 出现的次数和C(W1 W2…Wn-1)出现的次数。
下面我们用bigram举个例子。假设语料库总词数为13,748,
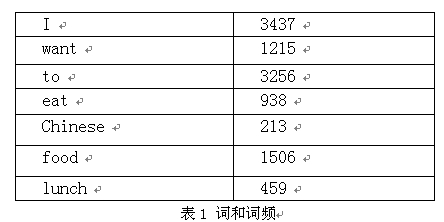
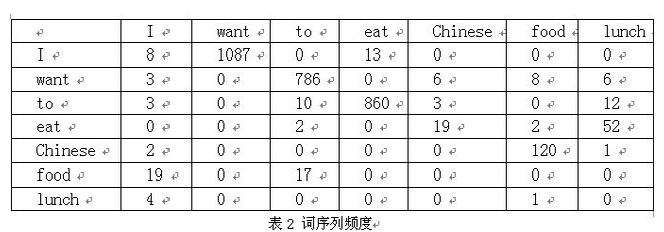
P(I want to eat Chinese food)
=P(I)*P(want|I)*P(to|want)P(eat|to)*P(Chinese|eat)*P(food|Chinese)
=(3437/13748)(1087/3437)(786/1215)(860/3256)(19/938)(120/213)=0.000154171
ps:网上很多资料中,没有词与词频这张表,造成文章表意不清楚。
还有一个问题,就是数据稀疏,假设词表中有20000个词,如果使用bi-Gram那可能的N-Gram就有400000000个,如果是tri-Gram那可能的N-Gram就有8000000000000个!!那么对于其中很多词对的组合,在语料库中都没有出现,根据最大似然估计得到的概率将为0,最后的结果是,该模型只能算可怜兮兮的几个句子,而大部分的句子的概率为0。因此,要进行数据平滑(Data Smoothing),数据平滑的目的有两个:一是让所有的N-Gram概率之和为1,而是使所有的N-Gram的概率均不为0。
这里提及的最大似然估计方法和数据平滑概念将在后期继续概括。















 1715
1715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









