







阿里巴巴供应商爬虫
起因
学了爬虫入门之后,打算找一个有难度的网站来实践,一开始打算找淘宝或者天猫(业界老大)来实践,但后续发现网上已经有很多这方面的项目,于是瞄上了阿里的国际网站阿里巴巴。开始一切顺利,没发现什么难度,后面发现供应商的联系方式需要登录,于是以其为目标开始写爬虫。
网站结构
1.阿里巴巴有个供应商分类的页面
https://www.alibaba.com/companies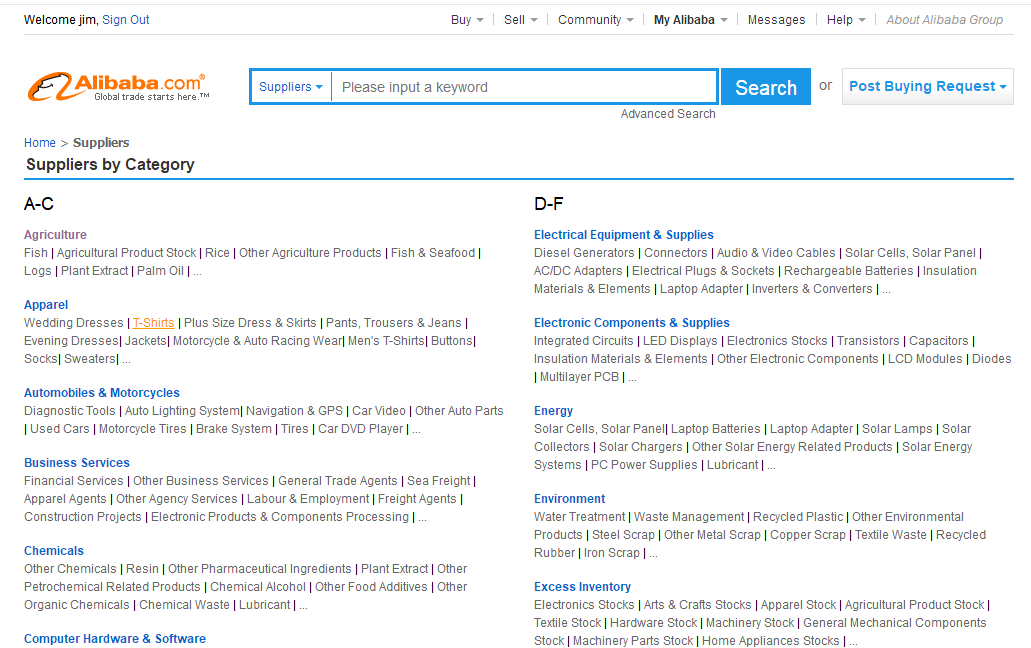
2.点进去之后有个二级分类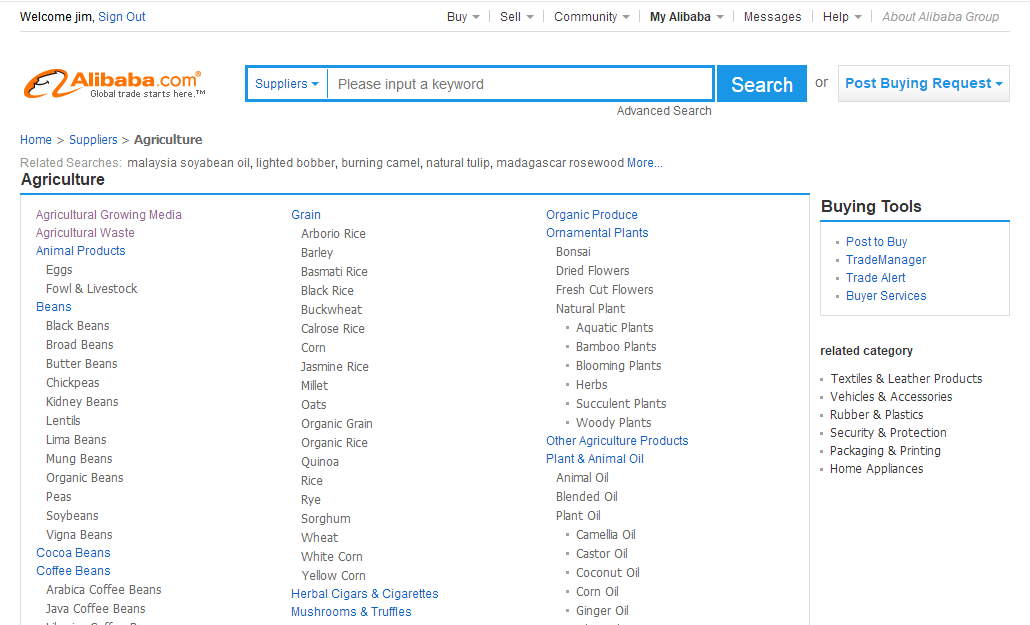
3.再点进去就可以找到这个分类下的所有供应商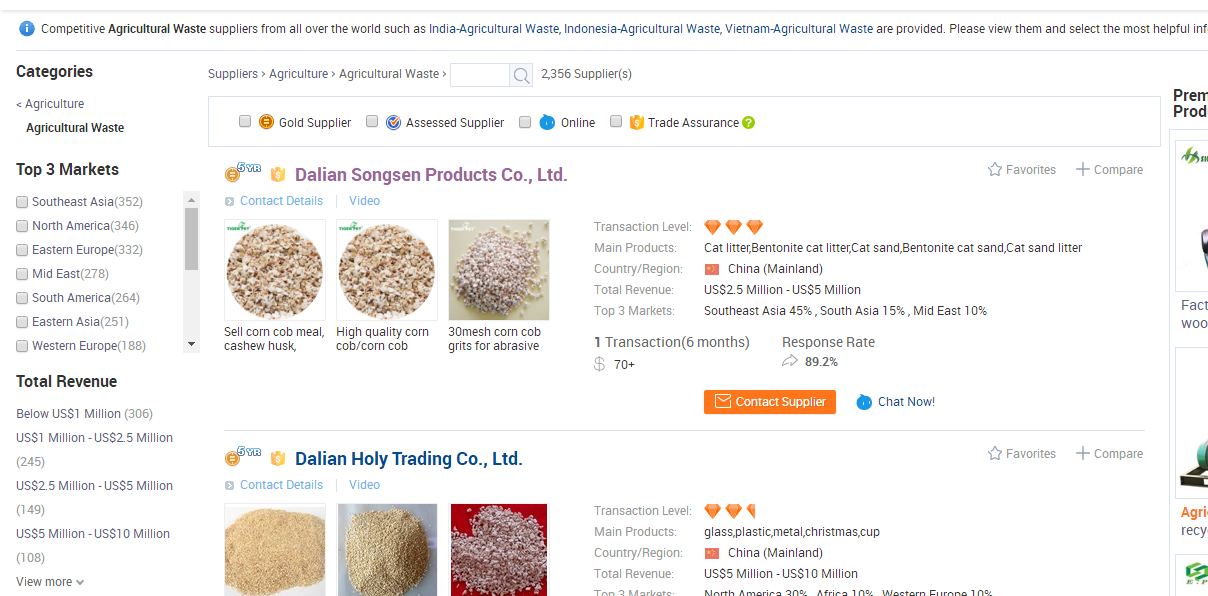
4.再进去就可以找供应商的联系方式了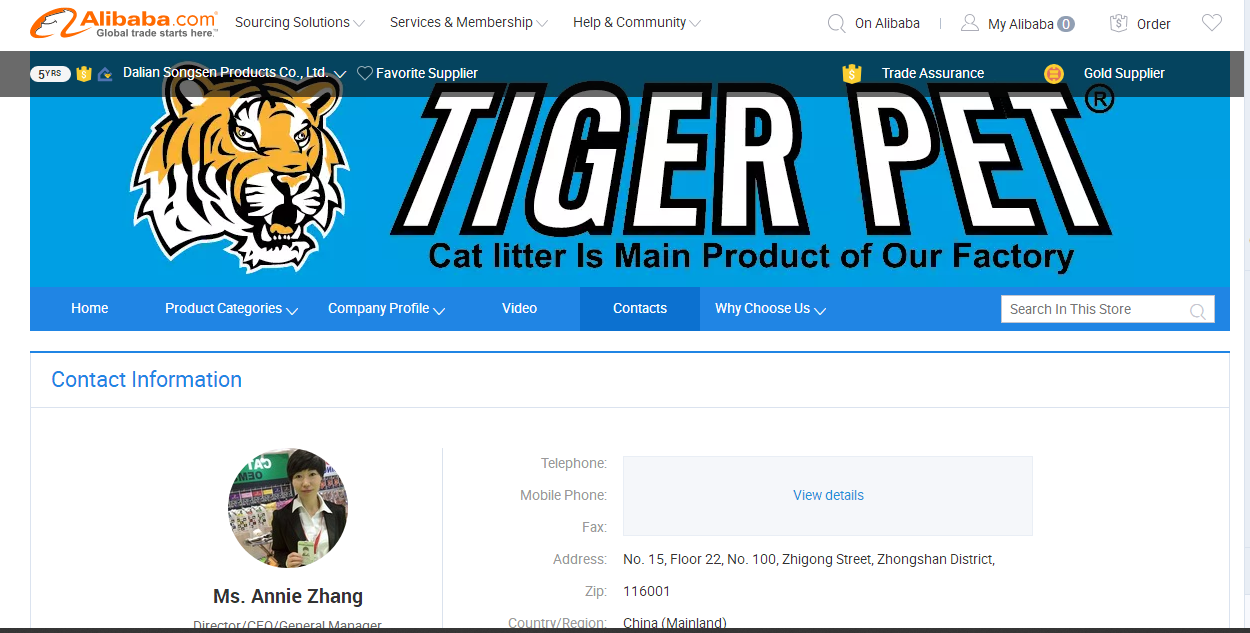
5.这时要获取联系方式就需要登录
爬虫思路
1.先从供应商分类页面开始爬取,获取到所有的供应商联系方式的页面(即上面网站结构的第4步)存入数据库
2.编写另一个爬虫从数据库拿到联系方式页面,再用selenium登录获取联系方式(这一步是取巧了,但也导致爬取速度直线下降)
代码结构
#scrapy的代码结构
alibaba
-spider
--company.py #获取供应商联系方式页面
--contact.py #获取联系方式的页面
-items
-middlewares.py
-pipelines.py
-setting.pycompany.py
class CompanySpider(scrapy.Spider):
name = 'company'
allowed_domains = ['www.alibaba.com']
start_urls = ['https://www.alibaba.com/companies']
# 爬取大的分类信息
def parse(self, response):
categorys = response.css(".ui-box.ui-box-normal.ui-box-wrap.clearfix .g-cate-list dl dt a")
for cat in categorys:
name = cat.css("::text").extract_first()
url = cat.css("::attr(href)").extract_first()
yield scrapy.Request(url, callback=self.parseCategory, meta={'cat': name})
pass
# 爬取详细分类信息
def parseCategory(self, response):
cat = response.meta['cat']
ccats = response.css("#category-main-box .g-float-left>ul>li>a")
for ccat in ccats:
name = ccat.css("::text").extract_first()
url = ccat.css("::attr(href)").extract_first()
ccat_url = urljoin(self.start_urls[0], 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









