






介绍
Zookeeper没有使用Paxos实现,而是使用ZAB(Zookeeper原子消息广播协议)作为数据一致性的核心算法。
ZAB是一种专为Zookeeper设计的支持崩溃恢复的原子广播协议。
ZAB分为原子广播和崩溃恢复两种模式。
原子广播
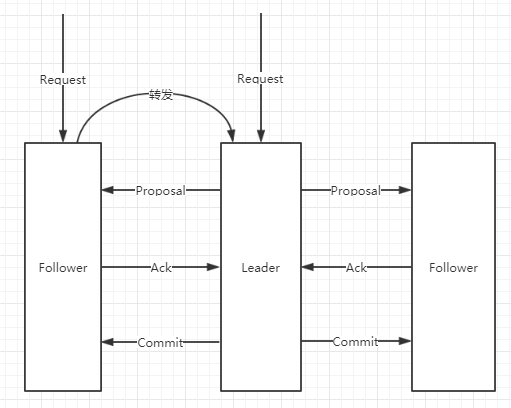
原子广播类似于前面说过的2pc协议,过程如下:
- Leader将客户端请求封装成Proposal,同时分配一个事务ID(ZXID)
- Leader会为每一个Follower分配一个队列,然后将Proposal放入队列中,根据FIFO策略发送消息
- Follower接收到Proposal后,以日志形式写入本地磁盘中。然后反馈Ack
- Leader接收到大半Follower的Ack后,广播Commit,并且提交Proposal
- Follower接收到Commit后提交
与2pc的差异在于移除了中断操作,只要超过半数的Follower反馈Ack后,Leader就会发送Commit;此外2pc的单点问题会由崩溃恢复解决。
崩溃恢复
一旦 Leader 服务器出现崩溃或者由于网络原因导致 Leader 服务器失去了与过半 Follower 的联系,那么就会进入崩溃恢复模式。
崩溃恢复要求具有以下特性:
- 确保那些已经在Leader上提交的事务最终被所有服务器提交
场景:一个事务在 Leader 上提交了,并且过半的 Folower 都响应 Ack 了,但是 Leader 在 Commit 消息发出之前挂了。 - 确保丢弃已经被 Leader 提出的但是没有被提交的事务
场景:假设一个事务在 Leader 提出之后,Leader 挂了。
崩溃恢复分为发现(Leader选举)和数据同步两个阶段
发现(Leader选举)
针对上面的特性1,我们如果让新选举出来的Leader具有最大的ZXID,那么这个Leader将拥有所有被Leader提交的事务;同时省去检查Proposal的提交和丢弃工作。
ZAB的选举算法为FastLeaderElection,规则如下:
- 优先检查ZXID,ZXID的较大的为Leader;
- ZXID一样,myid较大的为Leader。
数据同步
Leader会为每个Follower创建一个队列,将那些未被Follower同步的消息以Proposal发送,并紧接着发送Commit;等到Follower同步所有数据,才加入真正可用的Follower列表。
ZAB对特性2场景下产生的数据进行回退是依据ZXID。
ZXID = 32位的Leader的周期epoch + 32位的单调递增的事务id
epoch在每次选举出新的Leader都为自增1,而事务id会置0
当一个在特性2场景下崩溃的机器重启以follower身份连上新Leader时,会比较ZXID,然后回退崩溃前的事务。
数据同步结束之后将切换为原子广播模式。
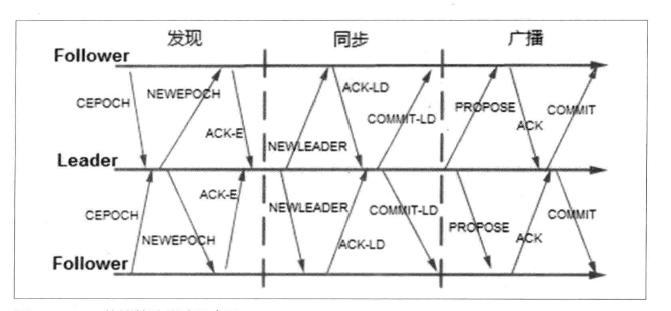
ZAB的整体流程
参考资料
从 Paxos 到 Zookeeper——分布式一致性原理和实践
https://www.jianshu.com/p/2bceacd60b8a















 1745
1745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









