







在实际生活中,我们常常需要根据已知的某些知识来预测未知的知识。例如我们可能需要根据房子的住宿面积来预测房子的销售价格,在这个问题中,已知的知识就是房子的住宿面积,未知的知识就是房子的销售价格。对于supervised learning来说,首先会拥有一个训练数据集training data。我们的任务就是从training data中学习到一个尽可能好的模型,可以对现实世界进行相关预测。
在预测问题中,如果要预测的变量(target value)取值是连续的,这个问题就叫做回归问题(regression),如果target value是离散的就称之为分类问题(classification)。
在预测问题中,我们将输入数据记为X,输出记为Y,我们的任务就是找到一个足够好的函数h:X—>Y。
(一)线性回归
如果我们预测的回归函数h是输入变量的线性组合,那么就称该问题为一个线性回归问题。即函数形式为: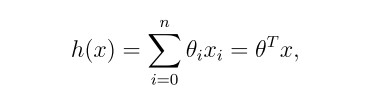
当我们得到预测函数时,将对我们的预测做出评价。一种简单的评价就是看我们做出的预测和我们已知的训练数据之间的差异。可以使用损失函数进行评价。损失函数可以定义为:
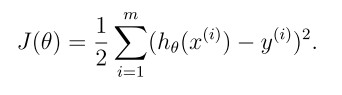
这里的损失函数使用了普通的最小二乘法定义。
我们选择模型的过程就是确定θ 的过程,我们的目标是选择使J(θ)尽可能小的θ 。在确定θ 是常使用梯度下降法得到。

















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









