







数据统计的三步走
爬取数据的三字真言
**整理清洗数据;
更新数据库;
数据的可视化;**
下面我几句我这几天所的可视化数据统计的知识,来简单总结一下知识点:
1、整理清洗数据
我们上代码:
#引入我们所需要的库文件
import pymongo
from string import punctuation
import charts
#连接数据库
client = pymongo.MongoClient('localhost',27017)
ceshi = client['ceshi']
item_info = ceshi['item_infoY']
#展开预览数据
for i in item_info.find().limit(300):
print(i['area'])
二、更新数据库
加入我们想要的数据是这样的:
[‘朝阳’, ‘高碑店’]
[‘朝阳’, ‘定福庄’]
[‘西城’, ‘西单’]
[‘朝阳’, ‘望京’]
但是真实的数据是这样的:
[‘朝阳’, ‘-‘, ‘高碑店’]
[‘朝阳’, ‘-‘, ‘定福庄’]
[‘西城’, ‘-‘, ‘西单’]
[‘朝阳’, ‘-‘, ‘望京’]
所以我们要将数据库中的数据更改为我们想要的:
下面简单的上段代码演示一下:
for i in item_info.find():
if i['area']:
area = [i for i in i['area'] if i not in punctuation]
else:
area = ['不明']
#将更改后的数据在数据库中进行更新:
item_info.update({'_id':i['_id']},{'$set':{'area':area}})三、数据可视化
1、首先到HighCharts官网查找你想要的演示图形;
HighCharts官网:
然后查看图形代码,然后用python实现图形代码;
下面我用折线图为做个示例:
首先,我们来看一下官网上折线图的js代码是怎样的:
$(function () {
$('#container').highcharts({
title: {
text: 'Monthly Average Temperature',
x: -20 //center
},
subtitle: {
text: 'Source: WorldClimate.com',
x: -20
},
xAxis: {
categories: ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
},
yAxis: {
title: {
text: 'Temperature (°C)'
},
plotLines: [{
value: 0,
width: 1,
color: '#808080'
}]
},
tooltip: {
valueSuffix: '°C'
},
legend: {
layout: 'vertical',
align: 'right',
verticalAlign: 'middle',
borderWidth: 0
},
series: [{
name: 'Tokyo',
data: [7.0, 6.9, 9.5, 14.5, 18.2, 21.5, 25.2, 26.5, 23.3, 18.3, 13.9, 9.6]
}, {
name: 'New York',
data: [-0.2, 0.8, 5.7, 11.3, 17.0, 22.0, 24.8, 24.1, 20.1, 14.1, 8.6, 2.5]
}, {
name: 'Berlin',
data: [-0.9, 0.6, 3.5, 8.4, 13.5, 17.0, 18.6, 17.9, 14.3, 9.0, 3.9, 1.0]
}, {
name: 'London',
data: [3.9, 4.2, 5.7, 8.5, 11.9, 15.2, 17.0, 16.6, 14.2, 10.3, 6.6, 4.8]
}]
});
});然后我们试着用python来实现上面的js代码:
#在这里我们需要一个日期,这里实现的一个自增长的日期函数;
def get_all_dates(date1,date2):
the_date = date(int(date1.split('.')[0]),int(date1.split('.')[1]),int(date1.split('.')[2]))
end_date = date(int(date2.split('.')[0]),int(date2.split('.')[1]),int(date2.split('.')[2]))
days = timedelta(days=1)
while the_date <= end_date:
yield (the_date.strftime('%Y.%m.%d'))
the_date = the_date + days#打印一下;
for i in get_all_dates('2015.12.24','2016.01.05'):
print(i)结果是:
2015.12.24
2015.12.25
2015.12.26
2015.12.27
2015.12.28
2015.12.29
2015.12.30
2015.12.31
2016.01.01
2016.01.02
2016.01.03
2016.01.04
2016.01.05
#我们需要将我们的数据和js代码中的series数据格式统一;
def get_data_within(date1,date2,areas):
for area in areas:
area_day_posts = []
for date in get_all_dates(date1,date2):
a = list(item_info.find({'pub_date':date,'area':area}))
each_day_post = len(a)
area_day_posts.append(each_day_post)
data = {
'name': area,
'data': area_day_posts,
'type': 'line'
}
yield data#打印一下:
for i in get_data_within('2015.12.24','2016.01.05',['朝阳','海淀','通州']):
print(i)结果是:
{‘data’: [220, 217, 259, 266, 322, 287, 309, 307, 346, 440, 488, 641, 649], ‘type’: ‘line’, ‘name’: ‘朝阳’}
{‘data’: [137, 146, 154, 156, 176, 183, 171, 217, 239, 284, 288, 397, 395], ‘type’: ‘line’, ‘name’: ‘海淀’}
{‘data’: [58, 54, 74, 57, 82, 84, 93, 79, 114, 113, 133, 151, 201], ‘type’: ‘line’, ‘name’: ‘通州’}
#最后用python将js代码实现:
options = {
'title' : {'text': '发帖量统计'},
'subtitle': {'text': '可视化统计图表'},
'xAxis' : {'categories': [i for i in get_all_dates('2015.12.24','2016.01.05')]},
'yAxis' : {'title': {'text': '数量'}}
}
series = [i for i in get_data_within('2015.12.24','2016.01.05',['朝阳','海淀','通州'])]
charts.plot(series, options=options,show='inline')
# options=dict(title=dict(text='Charts are AWESOME!!!'))看一下成果:
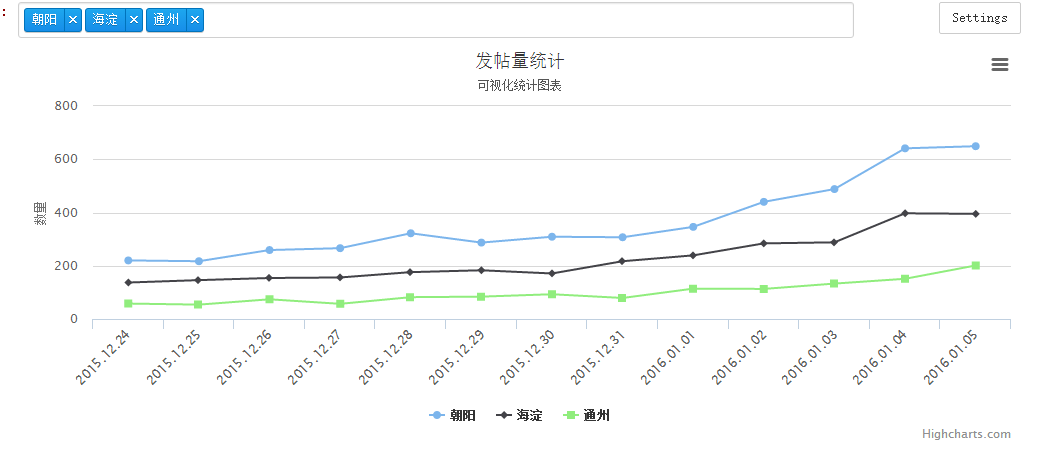
最后要说的是我们所用的工具插件都有哪些:
1、jupyter
2、Highcharts
安装成功后我来演示一下具体你操作:
打开命令行工具,输入jupyter-notebook;
这时默认浏览器会自动打开,接着你就可以在上面对你所爬取的数据进行统计可视化了;















 5345
5345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









