






正则表达式在平时处理文本内容的时候有很大用处,这里就简单的总结一下正则表达式的用法。
一、元字符
在学习正则表达式的时候,首先要了解正则里的一些基本符号。
首先是表示一些单字符。
. 任意字符(除换行符外) | |
| \d 任意数字 | \D 任意非数字 |
| \w 任意字母数字下划线 | \W 任意非字母数字下划线 |
| \s 任意空白符 | \S 任意非空白符 |
有了单字符之后,需要匹配单字符出现的次数,也就是量词。
| * 表示0到多次 |
| + 表示1到多次 |
| ?表示0或1次 |
| {m} 出现m次 |
| {m, } 表示至少出现m次 |
| {m,n} 表示出现m到n次 |
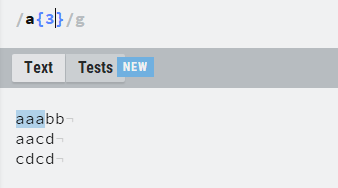
有了单字符和量词之后,我们可以进行一些简单的匹配,比如下面的正则,在三个字符串中找到aaabb这个词组。
但是如果想要做一些精细化的匹配就做不到了,比如我们想做一个匹配手机号的正则,现在我们只能用\d{11}来表示,但是这只能表示长度为11的数字,并不能匹配到符合规则的手机号,这个时候就引入了范围。
| |表示或,ab|bc表示ab或者bc |
| [....]表示选括号任意单个元素,[a-z]表示匹配a-z这26个字母中的任意一个 |
| [^....]表示取反,不选括号内的任意单个元素 |
有了范围之后就可以匹配一定规则的手机号了,如下:
1[3-9]\d{9}
表示符合以下条件的手机号
第 1 位固定为数字 1;
第 2 位可能是 3,4,5,6,7,8,9;
第 3 位到第 11 位我们认为可能是 0-9 任意数字。二、贪婪与非贪婪
在处理量词的时候,可以选择两种模式,一种是贪婪模式,一种是非贪婪模式。
| 贪婪模式 | 表示次数的量词尽可能多的匹配 |
| 非贪婪模式 | 表示次数的量词满足条件后,长度最少的,在量词后加?即可表示非贪婪 |
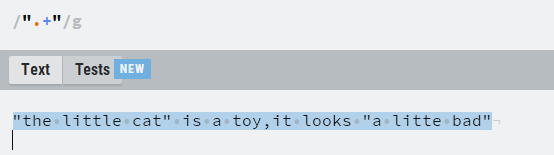
如下图所示,第一个图片表示的是贪婪模式,他尽可能多的匹配了双引号内的单词,第二个图片表示了非贪婪的模式,他匹配了两个双引号内的内容。

正则的贪婪和非贪婪的模式下,都会用到回溯。回溯过程如下:
regex:xy{1,3}z
text: xyyz
首先,匹配到了x字符,匹配y字符的时候,由于采用贪婪模式,会尽可能多的匹配字符,匹配到了两个y
然后第三个y去匹配z的时候发现匹配不上,这时候会换z去匹配文本。
regex:xy{1,3}?z
text: xyyz
首先,匹配到了x字符,匹配y字符的时候,由于采用非贪婪模式,会尽可能少的匹配字符,
匹配到1个y之后,就会用z去匹配第二个y,发现匹配不上,就会用第二个y来匹配文本中的y,
匹配上之后,用z去匹配文本中的z
三、分组与引用
分组是一种帮我们简化正则编写的方法,
the little cat cat is in the hat hat, we like it.
比如我想匹配上面连续的两个cat和连续的两个hat,如果不用分组的话,我们只能写成cat cat|hat hat这样的正则表达式。
有了分组之后,我们就可以这样写。
(\w+) \1其中,\1就表示引用前面括号内的内容,\1就表示和前面的(\w+)一样的内容,所有括号内的内容,我们都可以用\数字的方式引用,如果我们不想引用这个括号里的内容,用(?:内容)就可以取消用\数字的方式来引用。
四、匹配模式
除了上面介绍的内容,正则表达式还有一些匹配模式,用来改变元字符的匹配行为。分别是不区分大小写模式、点号通配模式、多行模式和注释模式。
不区分大小写的模式,用(?i)来表示不区分大小写,可以看到5个含有大小写的cat都被匹配了,如果不用大小写模式,匹配到这5个cat的正则就比较麻烦。

点号通配模式,(?s)来表示,这样点号就可以匹配上了换行。正常点号是不能匹配换行符的,所以下面右侧的图匹配了5行,而用了点号通配模式,就只匹配了一条记录。


多行模式,(?m)来表示,可以匹配多行,他改变的是^和$的匹配行为。如果不用多行模式的话,会匹配整个文本中匹配开头和结尾。用了多行模式会匹配每一行的开头和结尾。


注释模式,(?#)来表示注释,

五、环视
环视是用来表示,匹配的前面和后面满足某种规则的方法,环视的用法如下。

下面是一个例子,只匹配开头是1-9,一共6位的数字,如果不用环视,最后一行的数字,会被分成两组。
















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









