







这篇文章介绍用线性回归解决波士顿房价的预测问题,线性回归的原理部分参见线性回归博客。
一、了解数据
首先导入需要的包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
from sklearn import preprocessing加载波士顿房价的数据集
data = load_boston()
data_pd = pd.DataFrame(data.data,columns=data.feature_names)
data_pd['price'] = data.target在拿到数据之后,先要查看数据的类型,是否有空值,数据的描述信息等等。
# 查看数据类型
data_pd.get_dtype_counts()
可以看到数据都是Int类型
接下来要查看数据是否存在空值,从结果来看数据不存在空值。
# 查看空值
data_pd.isnull().sum()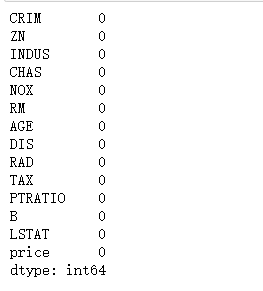
# 查看数据大小
data_pd.shape![]()
接下来查看数据的描述信息,在描述信息里可以看到每个特征的均值,最大值,最小值等信息。
# 查看数据描述
data_pd.describe()
查看数据前5行,同时给出数据特征的含义
# 显示数据前5行
data_pd.head()
二、分析数据
计算每一个特征和price的相关系数
data_pd.corr()['price']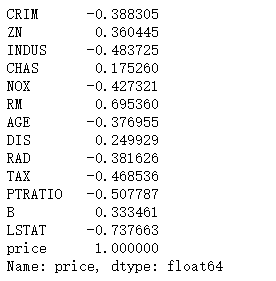
将相关系数大于0.5的特征画图显示出来:
corr = data_pd.corr()
corr = corr['price']
corr[abs(corr)>0.5].sort_values().plot.bar()
可以看出LSTAT、PTRATIO、RM三个特征的相关系数大于0.5,下面画出三个特征关于price的散点图。



可以看出三个特征和价格都有明显的线性关系。
三、建立模型
首先制作训练集和测试集
# 制作训练集和测试集的数据
data_pd = data_pd[['LSTAT','PTRATIO','RM','price']]
y = np.array(data_pd['price'])
data_pd=data_pd.drop(['price'],axis=1)
X = np.array(data_pd)
# 分割训练集和测试集
train_X,test_X,train_Y,test_Y = train_test_split(X,y,test_size=0.2)# 加载模型
linreg = LinearRegression()
# 拟合数据
linreg.fit(train_X,train_Y)
# 进行预测
y_predict = linreg.predict(test_X)
# 计算均方差
metrics.mean_squared_error(y_predict,test_Y) 最后的误差是![]()
四、用LASSO进行降维,找到最重要的特征
# 导包
from sklearn.linear_model import Lasso,LassoCV,LassoLarsCV
from sklearn.metrics import r2_score
# 重新加载数据
data = load_boston()
X = pd.DataFrame(data.data,columns=data.feature_names)
y = np.array(data.target)
# 分割训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=14)
# 找到Lasso的alapha值
model = LassoCV(cv=20).fit(X, y)
# 进行Lasso回归
lasso = Lasso(max_iter=10000, alpha=model.alpha_)
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test)
# 输出Lasso系数
lasso.coef_
可以看到系数大于0.5的有4个特征LSTAT、PTRATIO、RM、DIS其中DIS是上面相关性分析没有的特征,将这个特征加入,重新运行线性回归。
# 制作训练集和测试集的数据
data_pd = data_pd[['LSTAT','PTRATIO','RM','DIS','price']]
y = np.array(data_pd['price'])
data_pd=data_pd.drop(['price'],axis=1)
X = np.array(data_pd)
train_X,test_X,train_Y,test_Y = train_test_split(X,y,test_size=0.2)
# 训练模型,并重新计算均方差
linreg = LinearRegression()
linreg.fit(train_X,train_Y)
y_predict = linreg.predict(test_X)
metrics.mean_squared_error(y_predict,test_Y)最后的误差为![]()















 3185
3185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









