







据当代市场学权威菲利普.科特勒研究结论,若一个公司的用户流失率降低5%,则利润将会增加25%-85%。企业若想获得一位新客户,成本往往比挽留一位存量客户所用的成本要高,运营商行业挽留一位有拆机倾向的客户往往只需一个电话或者一个优惠政策即可。本文针对近期争议颇高的不限量套餐用户展开,通过数据挖掘模型对历史数据进行建模,对有流失风险的用户进行精准定位。
我们把该命题归结为如下2个问题:
- 问题1:预测哪些客户(尤其是高价值客户)可能会流失?
- 问题2:可能流失客户的特征是什么?
当然,如果考虑成本费用问题,可以衍生问题3,市场挽留活动的预计收益是什么。
流失用户识别主要包括以下步骤

本案例共抽取了过去10个月的历史数据,累计813683条记录,其中前8个月数据作为模型训练数据,后选取1月数据作为模型测试数据,选取1月数据作为模型检验数据。
注:训练数据是指数据挖掘过程中用于训练数据挖掘模型的数据。训练数据选择一般有以下要求:数据样本尽可能大、数据多样化,数据样本质量较高。测试数据用于模型检验,检验数模作为评估模型的准确率。
1. 数据抽取与数据变换
在数据准备阶段,我们需要考虑有哪些描述用户的数据可以作为预测用户流失变量,包含两个类别数据,分别为:
- 用户基本信息数据:包含用户类型,用户入网时间,用户办理套餐,套餐积分等,这类基本数据一般都可以从业务系统数据库获得。
- 用户行为数据:主要是用户使用电信产品的行为数据,包括用户通话时长,用户使用流量,用户收入等。
为了取得良好的数据挖掘效果,我们偶尔需要对数据进行变化或者生产相关的衍生变量。下面总结一些常用的衍生变量的方法。
- 强度相对指标:有一定联系的的两个指标之间相比的结果的到的指标,如通话时长和通话次数两个指标相比,得到每次通话时长,使我们了解用户的通话习惯,是长话短说型,还是短话长说型。
- 比例相对指标:用来反映总体中各个部分所占比例的一个指标,例如通话时长的被动通话时长和主叫通话时长占比。
- 汇总类指标:在本案例中,一个用户对应有10个月的数据,对应着10条记录,而对应一条是否流失记录,为了便于建立挖掘模型,我们需要将这6条数据变为1条数据,可以根据变量求和、计算平均值、最大值、最小值、标准差等汇总指标。
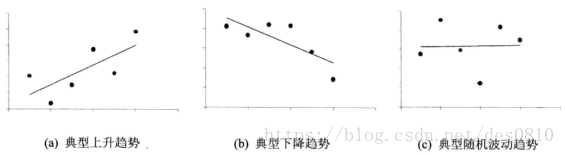
- 趋势类指标:对于时间序列变量而言,最重要的方面是看趋势,如针对收入这个变量,即看一个用户收入在10月期间是变多了还是变少了,还是随机性波动? 我们有理由假设假如一个用户收入变少,是否更有可能流失。

其中x代表月份,y代表待计算趋势的字段,如收入 ,n代表月份数。序列常见的趋势有:
- 波动类指标:对时间序列而言,趋势只反映了大致方向,而波动类指标衡量波动大小。本案例波动值计算公式如下:
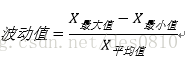
本案例数据变化通过Spss Modeler实现,流程图如下:

2. 数据探索性分析
- 离散型变量的探索性分析方法:离散变量可通过频数分布表,饼图,条形图等可视化变量取值以及各个取值占比是多少。
- 连续型变量的探索型分析方法:使用描述统计量,如反映集中趋势指标有均值,中位数等,反映趋势和离散程度的标准差、级差等;使用图形,如直线图,核密度估计图等
注: kdeplot(核密度估计图):
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
seaborn.kdeplot(data,data2=None,shade=False,vertical=False,kernel='gau',bw='scott',gridsize=100,cut=3,clip=None,legend=True,cumulative=False,shade_lowest=True,cbar=False, cbar_ax=None, cbar_kws=None, ax=None, *kwargs)
具体示例如下:
#核密度估计图示例
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









