









 TDengine是一款专为物联网设计的高性能时序数据库,提供10倍以上的性能提升,显著降低成本。它具备强大的分析功能,能够轻松集成第三方工具,采用列式存储优化读写效率。
TDengine是一款专为物联网设计的高性能时序数据库,提供10倍以上的性能提升,显著降低成本。它具备强大的分析功能,能够轻松集成第三方工具,采用列式存储优化读写效率。
TDengine牺牲对场景可忽略的功能 提高性能 CUrd
白皮书介绍TDengine:
• 10 倍以上的性能提升:定义了创新的数据存储结构,单核每秒就能处理至少 2
万次请求,插入数百万个数据点,读出一千万以上数据点,比现有通用数据库
快了十倍以上。
• 硬件或云服务成本降至 1/5:由于超强性能,计算资源不到通用大数据方案的
1/5;通过列式存储和先进的压缩算法,存储空间不到通用数据库的 1/10
• 全栈时序数据处理引擎:将数据库、消息队列、缓存、流式计算等功能融合一
起,应用无需再集成 Kafka/Redis/HBase/Spark/HDFS 等软件,大幅降低应
用开发和维护的复杂度成本。
• 强大的分析功能:无论是十年前还是一秒钟前的数据,指定时间范围即可查
询。数据可在时间轴上或多个设备上进行聚合。临时查询可通过 Shell,
Python, R, Matlab 随时进行。
• 与第三方工具无缝连接:不用一行代码,即可与 Telegraf, Grafana, Matlab,
R 集成。后续将支持 MQTT, OPC, Hadoop,Spark 等, BI 工具也将无缝连接。
• 零运维成本、零学习成本:安装、集群一秒搞定,无需分库分表,实时备份。
标准 SQL,支持 JDBC, RESTful, 支持 Python/Java/C/C++/Go, 与 MySQL
相似,零学习成本。
TDengine 系统结构
TDengine 是基于硬件、软件系统不可靠、一定会有故障的假设进行设计的,是基于
任何单台计算机都无足够能力处理海量数据的假设进行设计的,因此 TDengine 从研
发的第一天起,就是按照分布式高可靠架构进行设计的,是完全去中心化的。
TDengine 整个系统结构如图所示,下面对一些基本概念进行介绍。
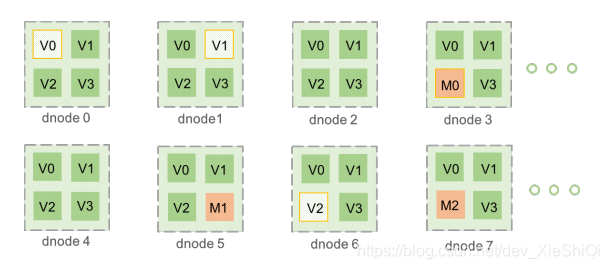
物理节点:集群里的任何一台物理机器(dnode),根据其具体的 CPU、Memory、存
储和其他物理资源,TDengine 将自动配置多个虚拟节点。
虚拟数据节点:存储具体的时序数据,所有针对时序数据的插入和查询操作,都在虚
拟数据节点上进行(图例中用 V 标明)。位于不同物理机器上的虚拟数据节点可以组
成一个虚拟数据节点组(如图例中 dnode0 中的 V0, dnode1 中的 V1, dnode6 中的
V2 组成了一个组),虚拟节点组里的虚拟节点的数据以异步的方式进行实时同步,并
实现数据的最终一致性,以保证一份数据在多台物理机器上有拷贝,而且即使一台物
理机器宕机,总有位于其他物理机器上的虚拟节点能处理数据请求,从而保证系统运
行的高可靠性。
虚拟管理节点:负责所有节点运行状态的采集、节点的负载均衡,以及所有 Meta
Data 的管理,包括用户、数据库、表的管理(图例中用 M 标明)。当应用需要插入
或查询一张表时,如果不知道这张表位于哪个数据节点,应用会连接管理节点来获取
该信息。Meta Data 的管理也需要有高可靠的保证,系统采用 Master-Slave 的机
制,容许多到 5 个虚拟管理节点组成一个虚拟管理节点集群(如图例中的 M0, M1,
M2)。这个虚拟管理节点集群的创建是完全自动的,无需任何人工干预,应用也无需
知道虚拟管理节点具体在哪台物理机器上运行。
TDengine 存储结构
为提高压缩和查询效率,TDengine 采用列式存储。基于时序数据特点,与众多的时
序数据库不一样的是,TDengine 将每一个采集点的数据作为数据库中的一张独立的
表来存储。这样对于一个采集点的数据而言,无论在内存还是硬盘上,数据点在介质
上是连续存放的,这样大幅减少随机读取操作,减少 IO 操作次数,数量级的提升读
取和查询效率。而且由于不同数据采集设备产生数据的过程完全独立,每个设备只产
生属于自己的数据,一张表也就只有一个写入者。这样每个表就可以采用无锁方式来
写,写入速度就能大幅提升。同时,对于一个数据采集点而言,其产生的数据是时序
的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
数据具体写如流程如图所示:
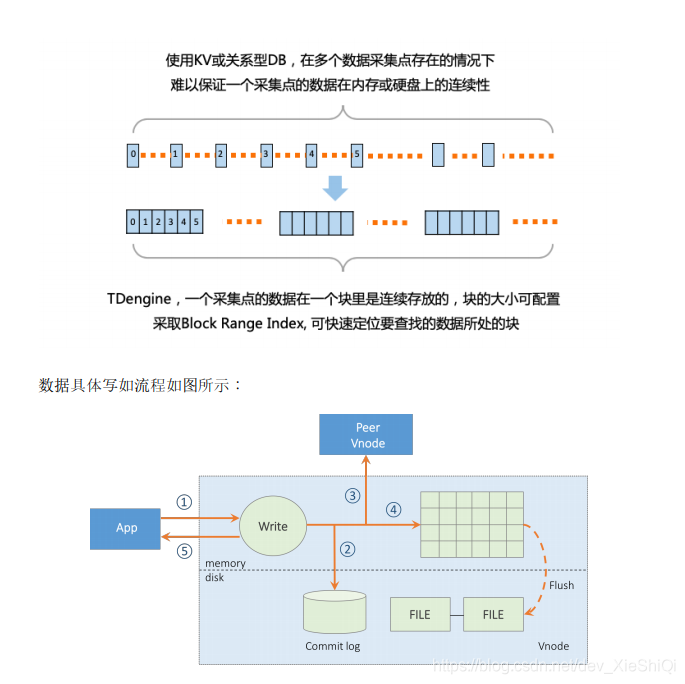
写入数据时,先将数据点写进 Commit 日志,然后转发给同一虚拟节点组里的其他节
点,再按列写入分配的内存块。当内存块的剩余空间达到一定临界值或设定的
commit 时间时, 内存块的数据将写入硬盘。内存块是固定大小(如 16K)的, 但依据系
统内存的大小,每个采集点可以分配一个到多个内存块,采取 LRU 策略进行管理。
在一个内存块里,数据是连续存放的,但块与块是不连续的,因此 TDengine 为每一
个表在内存里建立有块的索引,以方便写入和查询。
数据写入硬盘是以添加日志的方式进行的,以大幅提高落盘的速度。为避免合并操
作,每个采集点(表)的数据也是按块存储,在一个块内,数据点是按列连续存放
的,但块与块之间可以不是连续的。 TDengine 对每张表会维护一索引,保存每个数
据块在文件中的偏移量,起始时间、数据点数、压缩算法等信息。每个数据文件仅仅
保存固定一段时间的数据(比如一周,可以配置),因此一个表的数据会分布在多个数
据文件中。查询时,根据给定的时间段,TDengine 将计算出查找的数据会在哪个数
据文件,然后读取。这样大幅减少了硬盘操作次数。多个数据文件的设计还有利于数
据同步、数据恢复、数据自动删除操作,更有利于数据按照新旧程度在不同物理介质
上存储,比如最新的数据存放在 SSD 盘上,最老的数据存放在大容量但慢速的硬盘
上。
通过这样的设计,TDengine 将硬盘的随机读取几乎降为零,从而大幅提升写入
和查询效率,让 TDengine 在很廉价的存储设备上也有超强的性能。
为减少文件个数,一个虚拟节点内的所有表在同一时间段的数据都是存储在同一个数
据文件里,而不是一张表一个数据文件。但是对于一个数据节点,每个虚拟节点都会
有自己独立的数据文件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









