







1、逻辑回归
逻辑回归(Logistic Regression)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。经典之作《数学之美》中也看到它用于广告预测,还有类似的用户购买某商品的可能性,事件的发生都可以用可能性或几率(Odds)来表示。“几率”是指事件发生的可能性与不发生的可能性的比值。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。假设我们的样本是{x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
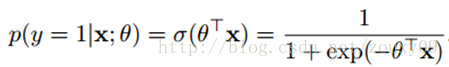
这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
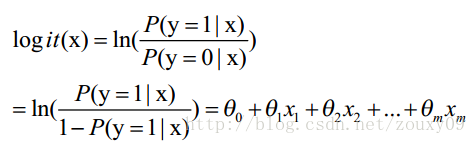
换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,萝卜青菜,各有所爱嘛。例如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,没钱了一起努力奋斗,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm。他们的加权和就是你的总得分了。
所以说上面的logistic回归就是一个线性分类模型,它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响(不知道理解的是否正确)。而实现这个伟大的功能其实就只需要平凡一举,也就是在输出加一个logistic函数。另外,对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。
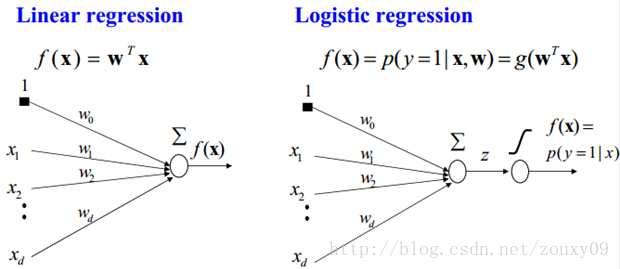
LogisticRegression最基本的学习算法是最大似然。啥叫最大似然,可以看看另一篇博文“从最大似然到EM算法浅解”。
假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
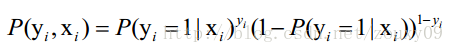
上面为什么是这样呢?当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):
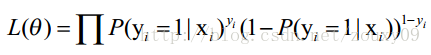
那最大似然法就是求模型中使得似然函数最大的系数取值θ。这个最大似然就是我们的代价函数(cost function)。先尝试对上面的代价函数求导,为了方便,先变换下L(θ):取自然对数,然后化简(注:有xi的时候,表示它是第i个样本),得到:
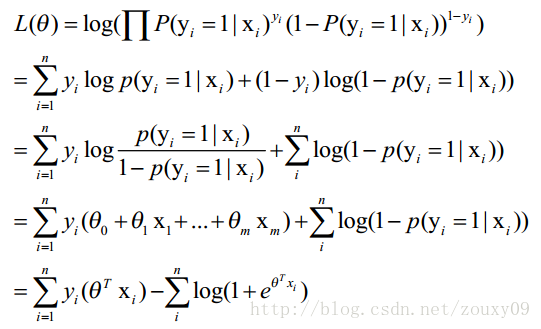
这时候,用L(θ)对θ求导,得到:
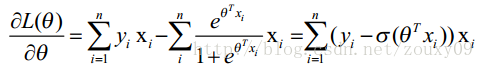
2、优化求解
2.1、梯度下降(gradient descent)
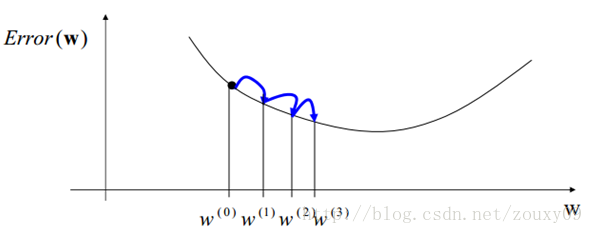
对Logistic Regression来说,梯度下降算法如下:
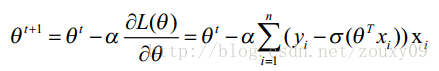
其中,参数α叫学习率,就是每一步走多远,这个参数蛮关键的。如果设置的太多,那么很容易就在最优值附加徘徊,因为你步伐太大了。例如要从广州到上海,但是你的一步的距离就是广州到北京那么远,没有半步的说法,自己能迈那么大步,是幸运呢?还是不幸呢?事物总有两面性嘛,它带来的好处是能很快的从远离最优值的地方回到最优值附近,只是在最优值附近的时候,它有心无力了。但如果设置的太小,那收敛速度就太慢了,向蜗牛一样,虽然会落在最优的点,但是这速度如果是猴年马月,我们也没这耐心啊。所以有的改进就是在这个学习率这个地方下刀子的。我开始迭代是,学习率大,慢慢的接近最优值的时候,我的学习率变小就可以了。所谓采两者之精华啊!这个优化具体见2.3 。
2.2、随机梯度下降(stochastic gradient descent)
2.3、改进的随机梯度下降
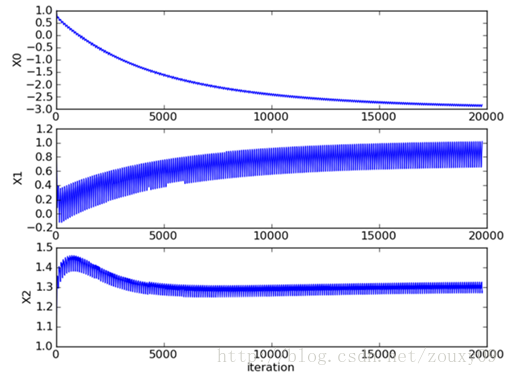
对随机梯度下降算法,我们做两处改进来避免上述的波动问题:
- 在每次迭代时,调整更新步长alpha的值。随着迭代的进行,alpha越来越小,这会缓解系数的高频波动(也就是每次迭代系数改变得太大,跳的跨度太大)。当然了,为了避免alpha随着迭代不断减小到接近于0(这时候,系数几乎没有调整,那么迭代也没有意义了),我们约束alpha一定大于一个稍微大点的常数项,具体见代码。
- 每次迭代,改变样本的优化顺序。也就是随机选择样本来更新回归系数。这样做可以减少周期性的波动,因为样本顺序的改变,使得每次迭代不再形成周期性。















 2807
2807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









