






一、storm计算框架
:性能优化的第一步就是找到瓶颈在哪里,从瓶颈处入手,解决关键点问题,事半功倍。
除了通过系统命令查看CPU使用,jstack查看堆栈的调用情况以外,还可以通过Storm自身提供的信息来对性能做出相应的判断。
在Storm 的UI中,对运行的topology提供了相应的统计信息
三个重要参数:
·Execute latency:消息(tuple)的平均处理时间,单位是毫秒。
·Process latency:消息从收到到被ack掉所花费的时间,单位为毫秒。如果没有启用Acker机制,那么Process latency的值为0。
·Capacity:计算公式为Capacity = Spout 或者 Bolt 调用 execute 方法处理的消息数量 × 消息平均执行时间/时间区间。如果这个值越接近1,说明Spout或者Bolt基本一直在调用 execute 方法,因此并行度不够,需要扩展这个组件的 Executor数量。
一、
Storm可以很容易地在集群中横向拓展它的计算能力,它会把整个运算过程分割成多个独立的tasks在集群中进行并行计算。在Storm中,一个task就是运行在集群中的一个Spout或Bolt实例。
Topology的运行涉及到四种组件:
Node(machines):集群中的节点,就是这些节点一起工作来执行Topology。
Worker(JVMs):一个worker就是一个独立的JVM进程。每个节点都可以通过配置运行一个或多个worker,一个Topology可以指定由多少个worker来执行。
Executors(threads):一个worker JVM中运行的线程。一个worker进程可以执行一个或多个executor线程。一个Executor可以运行一个“组件”内的多个tasks,Storm默认一个每个executor分配一个task。
Task(bolt/spout实例):Tasks就是spouts和bolts的实例,它具体是被executor线程处理的。
二、
Storm实例:wordcount
Topology默认执行情况如下: 一个节点会为Topology分配一个worker,这个worker会为每个Task启一个executor。 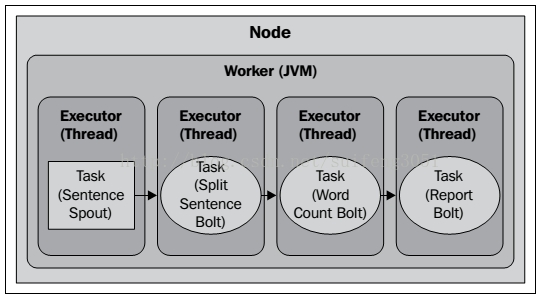
2.1 为Topology增加worker
两种途径增加workers:通过程序设置或storm rebalance命令。
Config config = new Config();
config.setNumWorkers(2);
注意:在LocalMode下不管设置几个worker,最终都只有一个worker进程。
2.2 配置executors和tasks
task是spout和bolt的实例,一个executor线程处理多个task,task是真正处理具体数据的一个过程。Task的数量在整个topology运行期间一般是不变的,但是组件的Executor是有可能发生变化的,即有:thread<=task。
2.2.1 设置executor(thread)数量
每个组件产生多少个Executor?在程序中设置或storm rebalance命令
builder.setSpout(SENTENCE_SPOUT_ID,spout, 2);
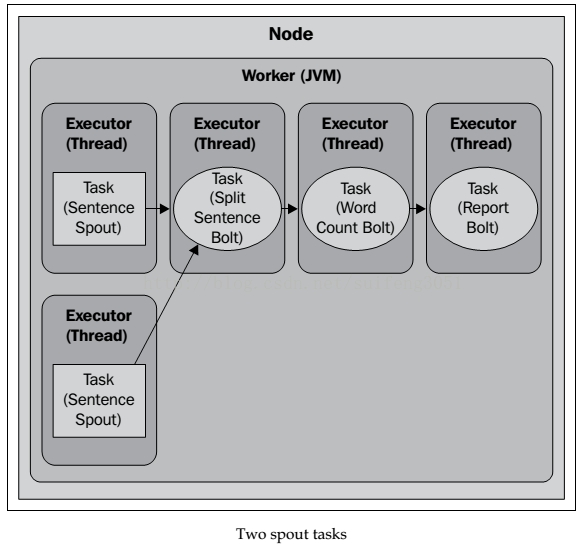
2.2.2 设置task的数量
每个组件创建多少个task?在程序中设置或storm rebalance命令
builder.setBolt(SPLIT_BOLT_ID,splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID,newFields("word"));
如果一开始分配2个workers,则Topology的运行情况如下:
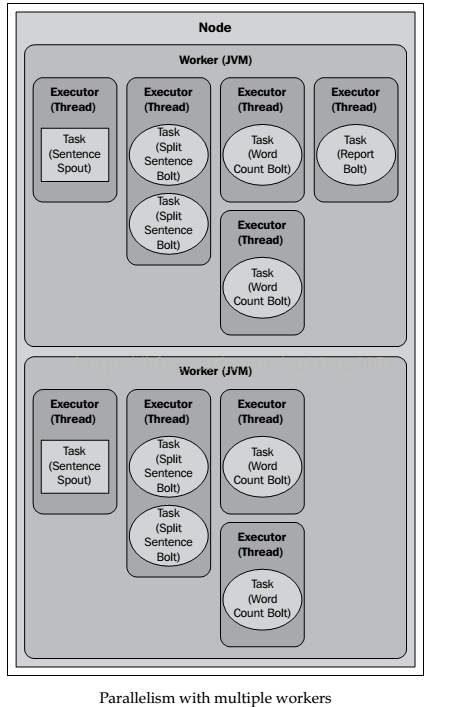
三、
一个实际topology的全景,topology由三个组件组成,
一个Spout:BlueSpout
两个Bolt:GreenBolt、YellowBolt。
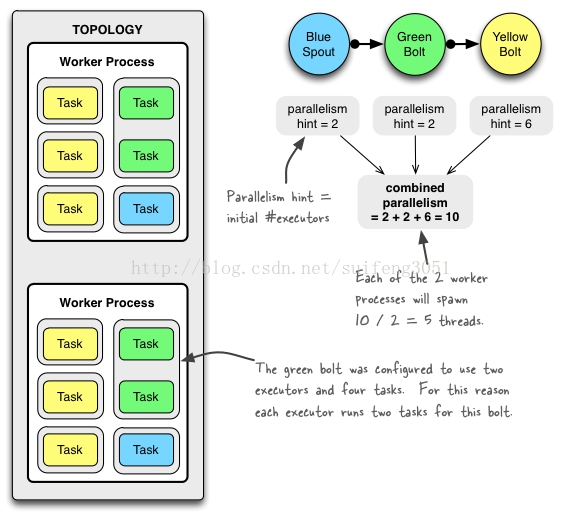
如上图,我们配置了两个worker进程,两个BlueSpout线程,两个GreenBolt线程和六个YellowBolt线程,那么分布到集群中的话,每个工作进程都会有5个executor线程。具体代码:
Config conf = new Config(); conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout(“blue-spout”, new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping(“blue-spout”);
topologyBuilder.setBolt(“yellow-bolt”, new YellowBolt(), 6) .shuffleGrouping(“green-bolt”);
StormSubmitter.submitTopology( “mytopology”, conf, topologyBuilder.createTopology() );
Storm中也有一个参数来控制topology的并行数量: TOPOLOGY_MAX_TASK_PARALLELISM: 这个参数可以控制一个组件上Executor的最大数量。它通常用来在本地模式测试topology的最大线程数量。当然我们也可以在代码中设置:
config.setMaxTaskParallelism().
四、
如何改变一个运行topology中的Parallelism
Storm中一个很好的特性就是可以在topology运行期间动态调制worker进程或Executor线程的数量而不需要重启topology。这种机制被称作rebalancing。 我们有两种方式来均衡一个topology:
1:通过Storm web UI
2:通过storm rebalance命令
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
二、storm调度算法
DefaultScheduler:默认调度算法,采用轮询的方式将系统中的可用资源均匀地分配给topology,但也不是绝对均匀。会先将其它topology不需要的资源重新收集起来。EventScheduler:和DefaultScheduler差不多,不会先将其它topology不需要的资源重新收集起来。
IsolationScheduler:用户可定义topology的机器资源,storm分配的时候会优先分配这些机器,以保证分配给该topology的机器只为这一个topology服务。
DefaultScheduler:
1:调用cluster的needsSchedualerTopologies方法获得需要进行任务分配的topologies
开始分别对每一个topology进行处理
2:调用cluster的getAvailableSlots方法获得当前集群可用的资源,以<node,port>集合的形式返回,赋值给available-slots
3:获得当前topology的executor信息并转化为<start-t ask-id,end-task-id>集合存入all-executors,根据topology计算executors信息,采用compute-executors算法。
4:调用DefaultScheduler的get-alive-assigned-node+port->executors方法获得该topology已经获得的资源,返回<node+port,executor>集合的形式存入alive-assigned
5:调用slot-can-reassign对alive-assigned中的slots信息进行判断,选出其中能被重新分配的slot存入变量can-reassigned。这样可用的资源就由available-slots和can-reassigned两部分组成。
6:计算当前topology能使用的全部slot数目total-slots--to-use:min(topology的NumWorker数,available-slots+can-reassigned),如果total-slots--to-use>当前已分配的slots数目,则调用bad-slots方法计算可被释放的slot
7:调用cluster的freeSlots方法释放计算出来的bad-slot
8:最后调用EventScheduler的schedule-topologies-evenly进行分配
:先计算集群中可供分配的slot资源,并判断当前已分配给运行Topology的slot是否需要重新分配,然后对可分配的slot进行排序,再计算Topology的executor信息,最后将资源平均地分配给Topology。
接下来我们提交3个topology
| Topology | Worker数 | Executer数 | Task数 |
| T-1 | 3 | 8 | 16 |
| T-2 | 5 | 10 | 10 |
| T-3 | 3 | 5 | 10 |
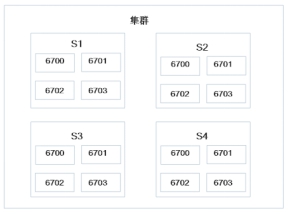
1、提交T-1
1:计算slots。sort-slots算法对可用slots进行处理,结果为{[s1 6700] [s2 6700] [s3 6700] [s4 6700] [s1 6701] [s2 6701] [s3 6701] [s4 6701] [s1 6702] [s2 6702] [s3 6702] [s4 6702] [s1 6703] [s2 6703] [s3 6703] [s4 6703]}
2:计算executor。compute-executors算法计算后得到的Executor列表为:{[1 2] [3 4] [5 6] [7 8] [9 10] [11 12] [13 14] [15 16]};注:格式为[start-task-id end-task-id],共8个executor,第一个包含2个task,start-task-id为1,end-task-id为2,所以记为[1 2],后面依次类推
3:计算worker。8个Executor在3个worker上的分布状态为[3,3,2]
分配结果为:
{[1 2] [3 4] [5 6]} -> [s1 6700]
{[7 8] [9 10] [11 12]} -> [s2 6700]
{[13 14] [15 16]} -> [s3 6700]
分配后集群状态为:
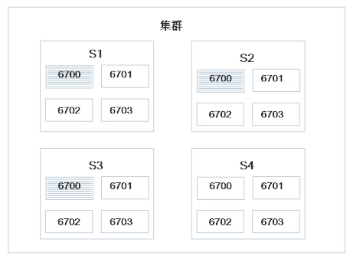
2、提交T-2、T-3
分配后集群状态为:
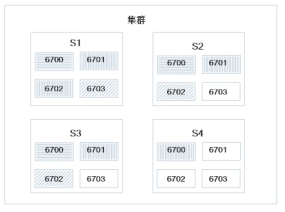
出现负载不均衡现象。
//
三、Jstorm调度
Jstorm(Jstorm介绍:http://wenku.baidu.com/view/59e81017dd36a32d7375818b.html)是阿里团队对Storm使用纯Java语言进行的重写,基本内核思想和Storm没有区别,架构如下,加了一些自己的优化。
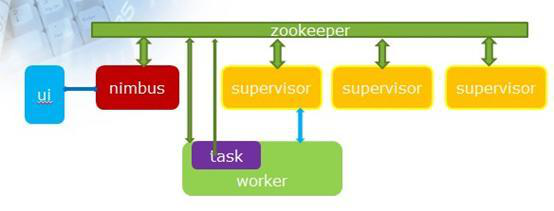
图1 Jstorm架构图
Jstorm早期版本(0.9.5之前)宣称支持从CPU、Memory、Disk以及Net四个纬度对资源进行分配和调度,并且任务分配粒度细到Task级别,但是新版本(本次分析基于最新发布版本0.9.6.2)紧支持CPU和Memory维度的任务分配,并且任务分配粒度也只到Worker级别,之前的相关API已经不推荐使用。
Jstorm的作者longda确认,Jstorm新版本确实删除掉了之前繁杂的资源分配机制,目前支持CPU和Memory维度的的资源分配,并且资源分配的粒度也只是到Worker级别。
2 Jstorm调度机制
Jstorm没有像Storm那样提供可插拔的任务分配器,它实现了Storm的默认调度算法,对默认调度算法进行了优化和扩展,并且在此基础上提供了丰富的调度定制化接口,用户可以方便的设置相应调度策略。
2.1 Jstorm的默认调度算法
Jstorm整体上继承了Storm的默认调度算法,保证Topology平均的分配在集群上,具体如下:
以Worker为维度,尽量将Worker平均分配到各个Supervisor上。
以Worker为单位,确认Worker与Task数目大致的对应关系。
建立Task-Worker的关系,建立关系的优先级为:尽量避免同类Task在同一Work和Supervisor下的情况,尽量保证Task在Worker和Supervisor基准上平均分配,尽量保证有直接信息流传输的Task在同一Worker中。
2.2 Jstorm的调度定制化接口
从Jstorm 0.9.0 开始, JStorm 提供非常强大的调度功能, 基本上可以满足大部分的需求(官方所言)。
Jstorm从0.9.5版本之后,提供了如下调度定制化接口:
2.2.1 设置每个Woker的默认内存大小
Jstorm提供如下接口来设置每个Worker占用的内存大小:
ConfigExtension.setMemSizePerWorker (Map conf, long memSize)
ConfigExtension.setMemSizePerWorkerByKB(Map conf, long memSize)
ConfigExtension.setMemSizePerWorkerByMB(Map conf, long memSize)
ConfigExtension.setMemSizePerWorkerByGB(Map conf, long memSize)
2.2.2 设置每个Worker的memory,cpu权重
Jstorm提供如下接口来设置每个Worker的cgroup,cpu权重
ConfigExtension.setCpuSlotNumPerWorker(Map conf, int slotNum)
2.2.3 设置是否使用旧的分配方式
Jstorm提供如下接口来设置是否使用旧的分配方式
ConfigExtension.setUseOldAssignment(Map conf, boolean useOld)
2.2.4 设置强制某个Component的Task运行在不同的节点上
Jstorm可以强制某个component的task 运行在不同的节点上,接口如下:
ConfigExtension.setTaskOnDifferentNode(Map componentConf, boolean isIsolate)
注意:这个配置componentConf是component的配置, 需要执行addConfigurations 加入到spout或bolt的configuration当中
2.2.5 自定义Worker分配
自定义Worker分配的示例如下:
WorkerAssignment worker = new WorkerAssignment();
worker.addComponent(String compenentName, Integer num);//在这个worker上增加task
worker.setHostName(String hostName);//强制这个worker在某台机器上
worker.setJvm(String jvm);//设置这个worker的jvm参数
worker.setMem(long mem); //设置这个worker的内存大小
worker.setCpu(int slotNum); //设置cpu的权重大小
ConfigExtension.setUserDefineAssignment(Map conf, List<WorkerAssignment> userDefines)
注:每一个worker的参数并不需要被全部设置,worker属性在合法的前提下即使只设置了部分参数也仍会生效。
Jstorm和Storm对比:
1.稳定性
均匀的将每个组件(spout/bolt)的线程(并行度)分配到集群中的各个节点。Jstorm会尽可能的将同一个组件的线程分配到不同的节点及worker上以减少同质竞争(同一个组件线程做的是一样的事情,比如可能都是cup密集型,那么放到不同节点就能提供效率,更好的利用资源)。
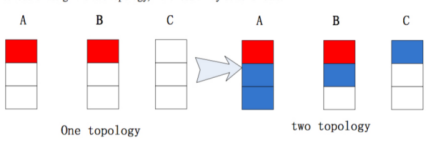
举个例子,一个集群有三个节点,node-A有3个worker,node-B有2个worker,node-C有一个worker。当用户提交一个topology(该topology需要4个worker,1个spout(X),一个bolt(Y),spout/bolt各占2个线程)。初始时:在Storm与Jstorm是一样的。
这时,如果node-C挂掉了,那么node-C中的worker必须要重写分配。如果是Storm的默认分配记过如下:
如果是Jstorm的默认调度来进行分配的化,结果如下:
显然,JStorm的默认调度算法比Storm的更加优秀。
2.负载均衡
Jstorm尽量保证每个worker所分得的线程数基本一致,并且worker在各个supervisors之间也尽量分配的均匀。例如,一个集群有3个节点,node-A有3个worker,noder-B有3个woker,node-C与3个woker。用户先提交了一个需要2个woker的topology,然后,又提交了一个需要4个worker的topology。
如果是Storm的默认调度算法来分配这两个topology,结果如下:
显然可以看出,这个分配是不均匀的。。而Jstorm的默认分配就能得到一个均匀的结果:
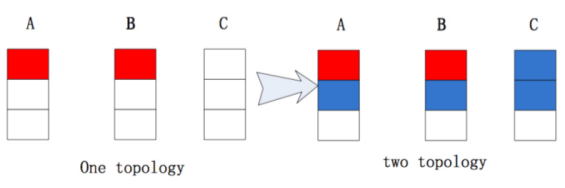
3.性能
Jstorm会试图将两个需要通讯的线程尽量放在一个worker中来减少网络的传输。例如:一个集群中有2个节点,node-A有2个worker,node-B有2个worker。当用户提交一个topology(需要2个worker,1个spout(X),2个bolt(Y、Z),三个组件各一个线程)。整个topology的数据流为X->Y->Z。如果Storm的默认调度算法来分配,可能的结果为:
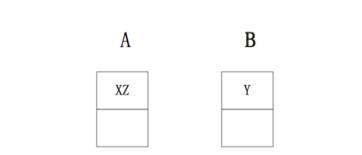
显然中间需要网络间传输,而JStorm的分配就能避免这个问题:
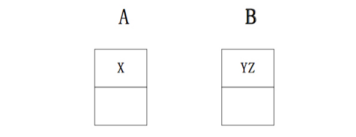
这里Y与Z的通讯是进程间通讯。在进程间通讯,消息不需要序列与反序列化。这样会极大的提高效率。
想要(稳定性/性能/平衡)都同时满足是很困难的。Jstorm对于重要性排序是:稳定性>性能>负债均衡。
JStorm相比Storm调度更强大
1彻底解决了storm 任务分配不均衡问题
2从4个维度进行任务分配:CPU、Memory(Disk、Net)
3默认一个task,一个cpu slot。当task消耗更多的cpu时,可以申请更多cpu slot
:解决新上线的任务去抢占老任务的cpu
:一淘有些task内部起很多线程,单task消耗太多cpu
4默认一个task,一个memory slot。当task需要更多内存时,可以申请更多内存slot
先海狗项目中,slot task 需要8G内存,而且其他任务2G内存就够了
5默认task,不申请disk slot。当task 磁盘IO较重时,可以申请disk slot
:海狗/实时同步项目中,task有较重的本地磁盘读写操作
6可以强制topology运行在单独一个节点上
:节省网络带宽
:Tlog中大量小topology,为了减少网络开销,强制任务分配到一个节点上
7可以强制某个component的task 运行在不同的节点上
聚石塔,海狗项目,某些task提供web Service服务,为了端口不冲突,因此必须强制这些task运行在不同节点上
8可以自定义任务分配:提前预约任务分配到哪台机器上,哪个端口,多少个cpu slot,多少内存,是否申请磁盘
:海狗项目中,部分task期望分配到某些节点上
9可以预约上一次成功运行时的任务分配:上次task分配了什么资源,这次还是使用这些资源
:CDO很多任务期待重启后,仍使用老的节点,端口
//
storm的基础框架如下:
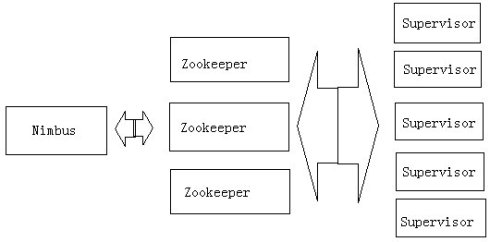
Nimbus是主节点维护的一个守护进程,用于分配代码、布置任务及故障检测。每个工作节点都运行了一个名为“Supervisor”的守护进程,用于监听工作,开始并终止工作进程。Nimbus和Supervisor的协调工作是由Zookeeper来完成的。Zookeeper用于管理集群中的不同组件,ZeroMQ是内部消息系统(netty)。
改进是在调度方面。参考思路:由于storm的调度是平均分配的,因此在offline情况下可以根据节点之间是否连通、找出类似于最短路径,从而动态调整拓扑图,以改进调度。另一方面,在online情况下,可以根据节点的负载情况,当负载量大于某个门限值时,认为到该节点不可达,重新选择路径,可以考虑以节点的负载量作为其他几点到该节点的距离,从而根据可达性等类似指标,使用类似于最短路径的算法,动态的调整拓扑结构,从而改进调度效率。
四、调度详解
任务调度接口定义:
| 1 | IScheduler{ |
| 2 | // conf为当前nimbus的storm配置 |
| 3 | void prepare(Map conf); // 初始化 |
| 4 | // topologyies表示集群中所有topology信息,cluster表示当前集群包括用户自定义调度逻辑事所需的 所有资源(Slot、Supervisor、以及任务分配情况)。 |
| 5 | void schedule(Topologies topologies,Cluster cluster); |
| 6 | }; |
Storm调度的相关术语
1、slot。这代表一个Supervisor节点上的一个单位资源。每个slot对应一个port,一个slot只能被一个Worker占用。
2、Worker,Executor.Task,1个Worker包含1个或多个Executor,每个Executor包含1个或多个Task。
3、Executor的表现形式为[1-1],[2-2],中括号内的数字代表该Executor中的起始Task id到末尾Task id,1个Worker就相当于在外面加个大括号{[1-1],[2-2]}
4.Component。Storm中的每个组件就是指一类Spout或1个类型的Bolt。
EventScheduler
实现流程图:
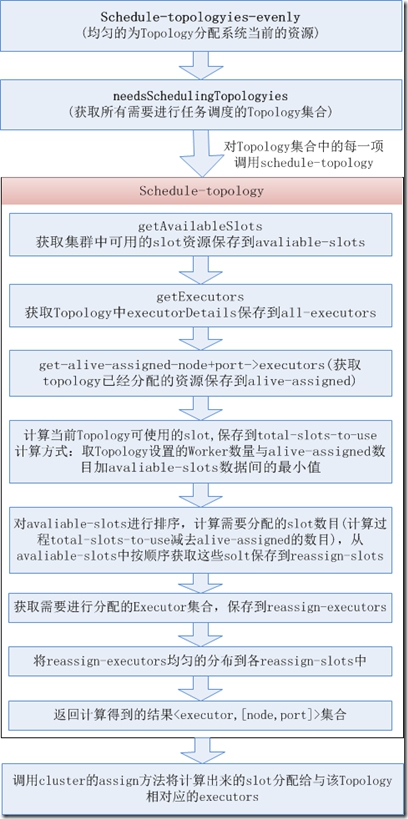
功能:对资源进行均匀分配的调度器,实现了IScheduler接口, schedule方法实现如下
| 1 | defn– schedule[this ^Topologies topologyies ^Cluster cluster] |
| 2 | (schedule-topologies-evenly topologies cluster) |
schedule-topologies-evenly方法原型:
| 1 | defn schedule-topologies-evenly[^Topologies topologies ^Cluster cluster] |
方法说明:
调用cluster对象的needsSchedulingTopology方法获取需要进行任务调度的Topology集合,判读依据:Topology设置的NumWorkers数目是否大于已经分配给该Topology的Worker数目,以及该Topology尚未分配的Executor数目是否大于0.
对需要进行任务调度的Topology获取其topology-id,然后调用schedule-topology方法获取到new-assignment(<executor,node+port>集合)。
用node和port信息构造WorkerSlot对象并将作为slot.
对Executor集合中的每一项构造ExecutorDetail对象,并返回一个ExecutorDetails集合。
调用cluster的assign方法将计算出来的slot分配给与该Topology相对应的executors.
schedule-topology
方法原型:
| 1 | defn- schedule-topology [^TopologyDetails topology ~Cluster cluster] |
方法说明:
调用cluster的getAvailableSlots方法获取当前集群可用的slot资源(集群中还没使用的Supervisor端口),并转换为<node,port>集合(available-slots).
将topology中的ExecutorDetails集合转换为<start-task-id,end-task-id>集合。
调用get-alive-assigned-node+port->executors方法获取当前topology已经分配的资源情况,返回<node+port,executors>集合(alive-assigned)。
获取当前topology可以使用的slot数目,topology设置的worker数目与当前available-slots数目加上alive-assigned数据二者的最小值(total-slots-to-use)。
对available-slots进行排序,计算需要分配的solt数目(total-slots-to-use减去alive-assigned),从排序后的solt中顺序获取需要分配的solt做为reassign-solts.
比较all-executors跟已分配的Executor集合间的差异,获取需要进行分配的Executor集合,做为reassign-executors.
将计算出来的reassign-solts与reassign-executor进行关联,转换为<executor,slot>映射集合(映射方式为:使executor均匀的分布在slot上),保存到ressignment中.
///
下面是调度器的核心实现。
import backtype.storm.scheduler.*;
import clojure.lang.PersistentArrayMap;
import java.util.*;
/**
* 直接分配调度器,可以分配组件(spout、bolt)到指定节点中
* Created by zhexuan on 15/7/6.
*/
public class DirectScheduler implements IScheduler{
@Override
public void prepare(Map conf) {
}
@Override
public void schedule(Topologies topologies, Cluster cluster) {
System.out.println("DirectScheduler: begin scheduling");
// Gets the topology which we want to schedule
Collection<TopologyDetails> topologyDetailes;
TopologyDetails topology;
//作业是否要指定分配的标识
String assignedFlag;
Map map;
Iterator<String> iterator = null;
topologyDetailes = topologies.getTopologies();
for(TopologyDetails td: topologyDetailes){
map = td.getConf();
assignedFlag = (String)map.get("assigned_flag");
//如何找到的拓扑逻辑的分配标为1则代表是要分配的,否则走系统的调度
if(assignedFlag != null && assignedFlag.equals("1")){
System.out.println("finding topology named " + td.getName());
topologyAssign(cluster, td, map);
}else {
System.out.println("topology assigned is null");
}
}
//其余的任务由系统自带的调度器执行
new EvenScheduler().schedule(topologies, cluster);
}
/**
* 将组件(spout、bolt)分配到指定节点
*/
private void topologyAssign(Cluster cluster, TopologyDetails topology, Map map){
Set<String> keys;
PersistentArrayMap designMap;
Iterator<String> iterator;
iterator = null;
// make sure the special topology is submitted,
if (topology != null) {
designMap = (PersistentArrayMap)map.get("design_map");
if(designMap != null){
System.out.println("design map size is " + designMap.size());
keys = designMap.keySet();
iterator = keys.iterator();
System.out.println("keys size is " + keys.size());
}
if(designMap == null || designMap.size() == 0){
System.out.println("design map is null");
}
boolean needsScheduling = cluster.needsScheduling(topology);
if (!needsScheduling) {
System.out.println("Our special topology does not need scheduling.");
} else {
System.out.println("Our special topology needs scheduling.");
// find out all the needs-scheduling components of this topology
Map<String, List<ExecutorDetails>> componentToExecutors = cluster.getNeedsSchedulingComponentToExecutors(topology);
System.out.println("needs scheduling(component->executor): " + componentToExecutors);
System.out.println("needs scheduling(executor->components): " + cluster.getNeedsSchedulingExecutorToComponents(topology));
SchedulerAssignment currentAssignment = cluster.getAssignmentById(topology.getId());
if (currentAssignment != null) {
System.out.println("current assignments: " + currentAssignment.getExecutorToSlot());
} else {
System.out.println("current assignments: {}");
}
String componentName;
String nodeName;
if(designMap != null && iterator != null){
while (iterator.hasNext()){
componentName = iterator.next();
nodeName = (String)designMap.get(componentName);
System.out.println("现在进行调度 组件名称->节点名称:" + componentName + "->" + nodeName);
componentAssign(cluster, topology, componentToExecutors, componentName, nodeName);
}
}
}
}
}
/**
* 组件调度
* @param cluster
* 集群的信息
* @param topology
* 待调度的拓扑细节信息
* @param totalExecutors
* 组件的执行器
* @param componentName
* 组件的名称
* @param supervisorName
* 节点的名称
*/
private void componentAssign(Cluster cluster, TopologyDetails topology, Map<String, List<ExecutorDetails>> totalExecutors, String componentName, String supervisorName){
if (!totalExecutors.containsKey(componentName)) {
System.out.println("Our special-spout does not need scheduling.");
} else {
System.out.println("Our special-spout needs scheduling.");
List<ExecutorDetails> executors = totalExecutors.get(componentName);
// find out the our "special-supervisor" from the supervisor metadata
Collection<SupervisorDetails> supervisors = cluster.getSupervisors().values();
SupervisorDetails specialSupervisor = null;
for (SupervisorDetails supervisor : supervisors) {
Map meta = (Map) supervisor.getSchedulerMeta();
if(meta != null && meta.get("name") != null){
System.out.println("supervisor name:" + meta.get("name"));
if (meta.get("name").equals(supervisorName)) {
System.out.println("Supervisor finding");
specialSupervisor = supervisor;
break;
}
}else {
System.out.println("Supervisor meta null");
}
}
// found the special supervisor
if (specialSupervisor != null) {
System.out.println("Found the special-supervisor");
List<WorkerSlot> availableSlots = cluster.getAvailableSlots(specialSupervisor);
// 如果目标节点上已经没有空闲的slot,则进行强制释放
if (availableSlots.isEmpty() && !executors.isEmpty()) {
for (Integer port : cluster.getUsedPorts(specialSupervisor)) {
cluster.freeSlot(new WorkerSlot(specialSupervisor.getId(), port));
}
}
// 重新获取可用的slot
availableSlots = cluster.getAvailableSlots(specialSupervisor);
// 选取节点上第一个slot,进行分配
cluster.assign(availableSlots.get(0), topology.getId(), executors);
System.out.println("We assigned executors:" + executors + " to slot: [" + availableSlots.get(0).getNodeId() + ", " + availableSlots.get(0).getPort() + "]");
} else {
System.out.println("There is no supervisor find!!!");
}
}
}
}
Storm自定义实现直接分配调度器,代码修改自Twitter Storm核心贡献者徐明明
在准备开发Storm自定义之前,事先已经了解了下现有Storm使用的调度器,默认是DefaultScheduler,调度原理大体如下:
* 在新的调度开始之前,先扫描一遍集群,如果有未释放掉的slot,则先进行释放
* 然后优先选择supervisor节点中有空闲的slot,进行分配,以达到最终平均分配资源的目标
现有scheduler的不足之处,上述的调度器基本可以满足一般要求,但是针对下面个例还是无法满足:
* 让spout分配到固定的机器上去,因为所需的数据就在那上面
* 不想让2个Topology运行在同一机器上,因为这2个Topology都很耗CPU
DirectScheduler把划分单位缩小到组件级别,1个Spout和1个Bolt可以指定到某个节点上运行,如果没有指定,还是按照系统自带的调度器进行调度.这个配置在Topology提交的Conf配置中可配.
打包此项目,将jar包拷贝到STORM_HOME/lib目录下
在nimbus节点的storm.yaml配置中,进行如下的配置:
storm.scheduler: "storm.DirectScheduler"
然后是在supervisor的节点中进行名称的配置,配置项如下:
supervisor.scheduler.meta:
name: "your-supervisor-name"
在集群这部分的配置就结束了,然后重启nimbus,supervisor节点即可,集群配置只要1次配置即可.
int numOfParallel;
TopologyBuilder builder;
StormTopology stormTopology;
Config config;
//待分配的组件名称与节点名称的映射关系
HashMap<String, String> component2Node;
//任务并行化数设为10个
numOfParallel = 2;
builder = new TopologyBuilder();
String desSpout = "my_spout";
String desBolt = "my_bolt";
//设置spout数据源
builder.setSpout(desSpout, new TestSpout(), numOfParallel);
builder.setBolt(desBolt, new TestBolt(), numOfParallel)
.shuffleGrouping(desSpout);
config = new Config();
config.setNumWorkers(numOfParallel);
config.setMaxSpoutPending(65536);
config.put(Config.STORM_ZOOKEEPER_CONNECTION_TIMEOUT, 40000);
config.put(Config.STORM_ZOOKEEPER_SESSION_TIMEOUT, 40000);
component2Node = new HashMap<>();
component2Node.put(desSpout, "special-supervisor1");
component2Node.put(desBolt, "special-supervisor2");
//此标识代表topology需要被调度
config.put("assigned_flag", "1");
//具体的组件节点对信息
config.put("design_map", component2Node);
StormSubmitter.submitTopology("test", config, builder.createTopology());
https://github.com/linyiqun/storm-scheduler
Storm中nimbus负责Topology分配,主要两阶段:
1. 逻辑分配阶段
这里又会涉及到两个概念executor和task,简单讲对于一个具体的component来说,task就是component在运行时的实例个数,即component静态的class代码,task是运行时的具体object对象,task的个数即是component在runtime时被实例化的对象个数,
而executor可以理解为线程的概念,一个component对应的executor个数就是component运行时所独占的线程数,举例来讲,某个component的task个数是6,executor个数是2,则运行时component就有6个实例运行在2个线程中,一个线程负责执行3个task,默认情况下一般会将task个数配置为executor的个数,即每一个线程只负责执行一个component的实例化对象。
:逻辑阶段所作的工作就是计算Topology中所有的component的executor个数,task个数,然后将所有的task分配到executor中。
2. 物理分配阶段
executor代表的是线程,具体要落地执行还需要依附于进程,因此物理分配阶段做的工作就是将所有的executor分配到worker slot进程中(一个slot代表一个jvm虚拟机)。
由于在逻辑分配阶段,task就是按照topology进行了排序,即相同component所属的task排列在一起,而在物理分配阶段slot资源也是按照端口进行了排序,即相同端口的slot排在了一起,
而具体分配算法是将排好序的task一次轮序分配到排好序的slot中,因此同一个component所属的不同task会尽可能的分到不同机器的相同端口上的slot中,实现了整个Topology的负载均衡,这样分配的好处是防止同一个component的所有task都分配到同一台机器上,造成整个集群负载不均。















 3448
3448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









