







论文笔记
论文来源:
代码来源
1论文摘要的翻译
我们训练了一个大型的深度卷积神经网络,将ImageNet LSVRC-2010竞赛中的120万张高分辨率图像分为1000个不同的类别。在测试数据上,我们实现了前1和前5的错误率分别为37.5%和17.0%,大大优于之前的先进技术。这个神经网络有6000万个参数和65万个神经元,由5个卷积层组成,其中一些是最大池化层,还有3个完全连接的层,最后是1000路softmax。为了使训练更快,我们使用了非饱和神经元和一个非常高效的GPU实现卷积操作。为了减少全连接层的过拟合,我们采用了最近开发的一种称为==“dropout”的正则化方法==,该方法被证明非常有效。我们还在ILSVRC-2012比赛中输入了该模型的一个变体,并获得了前5名的15.3%的测试错误率,而第二名的错误率为26.2%。
2论文的创新点
- 此模型在ILSVRC-2010和ILSVRC-2012比赛中使用的ImageNet子集上训练了迄今为止最大的卷积神经网络之一,并取得了迄今为止在这些数据集上报道的最佳结果。
- 为了减少全连接层的过拟合,该论文采用了了一种称为“dropout”的正则化方法,该方法被证明非常有效。
3 论文方法的概述
模型架构
网络架构如下图所示。它包含八个学习层——五个卷积层和三个全连接层。
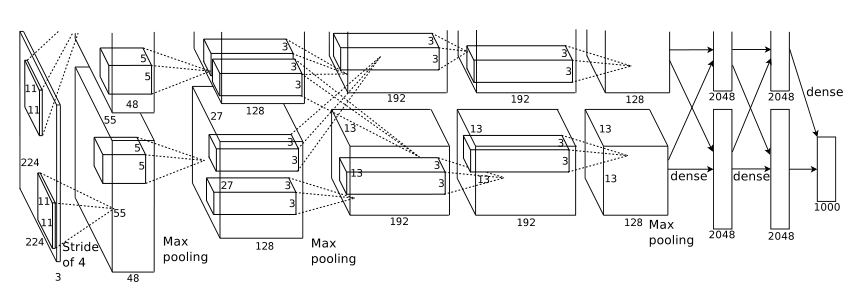
第一个卷积层是输入层,输入224×224×3图像,采用96个大小为11×11×3的卷积核,步幅为4像素进行卷积过滤,响应归一化和池化,并输出结果
第二个卷积层将第一个卷积层的输出作为输入,并使用256个大小为5 × 5 × 48的卷积核对其进行卷积过滤
第三层、第四层和第五层卷积层相互连接,没有任何中间池化层或归一化层。第三个卷积层有384个大小为3 × 3 × 256的核,这些核连接到第二个卷积层的输出(归一化,池化)。第四个卷积层有384个大小为3 × 3 × 192的核,第五个卷积层有256个大小为3 × 3 × 192的核。完全连接的层每层有4096个神经元
其余三个是完全连接的。最后一个完全连接层的输出被馈送到一个1000路softmax,
数据集处理
将图像降采样到256 × 256的固定分辨率。给定一个矩形图像,我们首先重新缩放图像,使较短的边长度为256,然后从结果图像中裁剪出中心的256×256补丁。
** 激活函数**
本实验中,我们使用这种非线性的神经元称为整流线性单元(relu)。公式如下
R e l u ( x ) = m a x ( 0 , x ) Relu(x) = max(0, x) Relu(x)=max(0,x)
使用relu的深度卷积神经网络的训练速度比使用tanh单元的深度卷积神经网络快几倍
显示了特定四层卷积网络在CIFAR-10数据集上达到25%训练误差所需的迭代次数。

多GPU训练
当前的gpu特别适合跨gpu并行化,因为它们能够直接从彼此的内存中读取和写入,而无需通过主机内存。我们采用的并行化方案实际上是将一半的内核(或神经元)放在每个GPU上,还有一个额外的技巧:GPU只在某些层进行通信。这意味着,例如,第3层的内核从第2层的所有内核映射中获取输入。然而,第4层的内核只从位于同一GPU上的第3层的内核映射中获取输入。选择连接模式是交叉验证的一个问题,但
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











